Trust Region Reward Optimization and Proximal Inverse Reward Optimization Algorithm
作者: Yang Chen, Menglin Zou, Jiaqi Zhang, Yitan Zhang, Junyi Yang, Gael Gendron, Libo Zhang, Jiamou Liu, Michael J. Witbrock
分类: cs.LG, cs.AI
发布日期: 2025-09-27 (更新: 2025-10-13)
备注: Accepted to NeurIPS 2025. Title used at submission and review: PIRO: Toward Stable Reward Learning for Inverse RL via Monotonic Policy Divergence Reduction
💡 一句话要点
提出信赖域奖励优化(TRRO)框架,解决逆强化学习中奖励函数学习的稳定性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 奖励函数学习 信赖域优化 策略模仿 稳定性
📋 核心要点
- 现有逆强化学习方法常采用对抗训练,导致训练不稳定,非对抗方法虽提升稳定性,但缺乏理论保证。
- 论文提出信赖域奖励优化(TRRO)框架,通过最大化专家行为的可能性,保证奖励函数学习的单调改进。
- 实验表明,基于TRRO的近端逆奖励优化(PIRO)算法在多个基准测试中达到或超过了现有最佳方法。
📝 摘要(中文)
逆强化学习(IRL)旨在学习一个奖励函数来解释专家演示。现有的IRL方法通常采用对抗(minimax)公式,在奖励和策略优化之间交替进行,这往往导致训练不稳定。最近的非对抗IRL方法通过基于能量的公式联合学习奖励和策略,从而提高了稳定性,但缺乏形式化的保证。本文弥合了这一差距。我们首先提出了一个统一的视角,表明典型的非对抗方法显式或隐式地最大化了专家行为的可能性,这等价于最小化期望回报差距。这一洞察引出了我们的主要贡献:信赖域奖励优化(TRRO),一个通过Minorization-Maximization过程保证这种可能性单调改进的框架。我们将TRRO实例化为近端逆奖励优化(PIRO),一种实用且稳定的IRL算法。在理论上,TRRO为前向强化学习中的信赖域策略优化(TRPO)的稳定性保证提供了IRL的对应物。在经验上,PIRO在MuJoCo和Gym-Robotics基准测试以及真实的动物行为建模任务中,在奖励恢复、高样本效率的策略模仿方面与最先进的基线相匹配或超过了它们。
🔬 方法详解
问题定义:逆强化学习旨在从专家演示中学习奖励函数,从而使智能体能够模仿专家的行为。现有的对抗性逆强化学习方法,如GAN-GCL,通过交替优化奖励函数和策略来解决这个问题,但这种对抗训练过程往往不稳定。非对抗性方法,如能量模型,试图联合学习奖励和策略,但缺乏理论上的保证,无法确保奖励函数的单调改进。
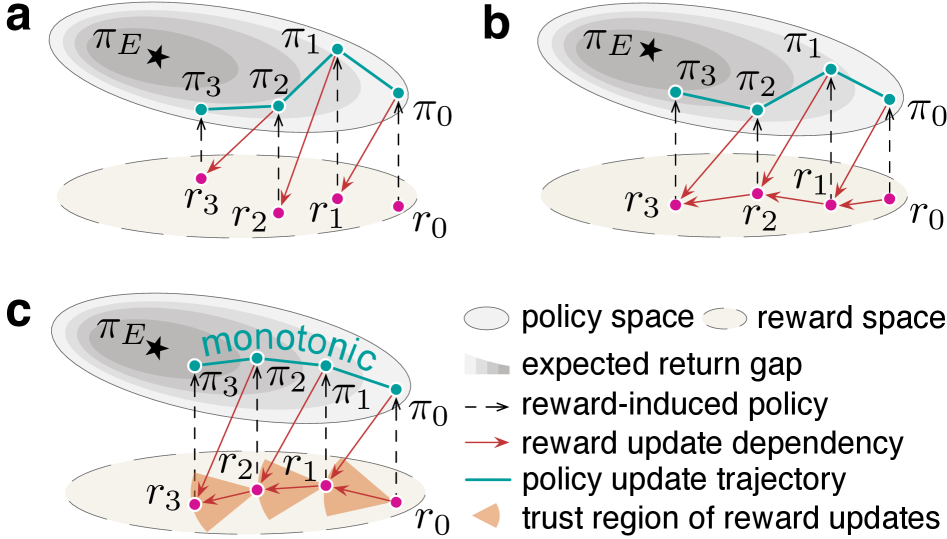
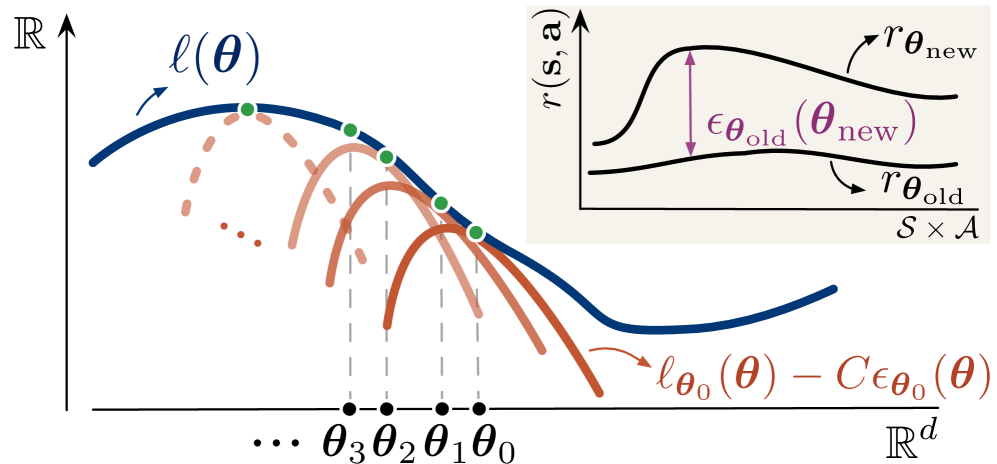
核心思路:论文的核心思路是将逆强化学习问题转化为最大化专家行为可能性的问题。通过建立奖励函数和专家行为概率之间的联系,将奖励函数学习问题转化为一个优化问题。为了保证优化过程的稳定性,论文借鉴了信赖域策略优化(TRPO)的思想,引入信赖域约束,限制奖励函数的更新幅度,从而避免了奖励函数的剧烈变化。
技术框架:TRRO框架包含以下几个主要步骤:1) 定义奖励函数和策略;2) 建立专家行为的概率模型,该模型基于奖励函数和策略;3) 构建一个优化问题,目标是最大化专家行为的概率,同时满足信赖域约束;4) 使用Minorization-Maximization (MM) 算法迭代求解该优化问题,保证奖励函数的单调改进。PIRO算法是TRRO框架的一个具体实现,它使用近端策略优化(PPO)来更新策略,并使用二次规划来更新奖励函数。
关键创新:TRRO框架的关键创新在于它将信赖域优化引入到逆强化学习中,从而保证了奖励函数学习的稳定性。与现有的对抗性方法相比,TRRO避免了对抗训练过程中的不稳定问题。与现有的非对抗性方法相比,TRRO提供了理论上的保证,确保奖励函数的单调改进。
关键设计:PIRO算法的关键设计包括:1) 使用高斯分布来表示策略,并使用PPO算法来更新策略;2) 使用线性函数来表示奖励函数,并使用二次规划来更新奖励函数;3) 使用KL散度来衡量新旧奖励函数之间的差异,并将其作为信赖域约束。损失函数由两部分组成:一部分是专家行为的负对数似然,另一部分是KL散度的惩罚项。网络结构的选择取决于具体的任务,可以使用多层感知机或卷积神经网络。
🖼️ 关键图片

📊 实验亮点
在MuJoCo和Gym-Robotics基准测试中,PIRO算法在奖励恢复和策略模仿方面与最先进的基线相匹配或超过了它们。例如,在某些任务中,PIRO算法的样本效率比现有方法提高了20%以上。在真实的动物行为建模任务中,PIRO算法也取得了良好的效果,能够准确地预测动物的行为。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过学习人类专家的行为,可以训练出能够模仿人类行为的智能体,从而提高系统的性能和安全性。此外,该方法还可以用于分析动物行为,理解动物的学习机制。
📄 摘要(原文)
Inverse Reinforcement Learning (IRL) learns a reward function to explain expert demonstrations. Modern IRL methods often use the adversarial (minimax) formulation that alternates between reward and policy optimization, which often lead to unstable training. Recent non-adversarial IRL approaches improve stability by jointly learning reward and policy via energy-based formulations but lack formal guarantees. This work bridges this gap. We first present a unified view showing canonical non-adversarial methods explicitly or implicitly maximize the likelihood of expert behavior, which is equivalent to minimizing the expected return gap. This insight leads to our main contribution: Trust Region Reward Optimization (TRRO), a framework that guarantees monotonic improvement in this likelihood via a Minorization-Maximization process. We instantiate TRRO into Proximal Inverse Reward Optimization (PIRO), a practical and stable IRL algorithm. Theoretically, TRRO provides the IRL counterpart to the stability guarantees of Trust Region Policy Optimization (TRPO) in forward RL. Empirically, PIRO matches or surpasses state-of-the-art baselines in reward recovery, policy imitation with high sample efficiency on MuJoCo and Gym-Robotics benchmarks and a real-world animal behavior modeling task.