GuardNet: Graph-Attention Filtering for Jailbreak Defense in Large Language Models
作者: Javad Forough, Mohammad Maheri, Hamed Haddadi
分类: cs.LG
发布日期: 2025-09-27
💡 一句话要点
提出GuardNet,通过图注意力过滤防御大语言模型的越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击防御 图神经网络 图注意力网络 对抗性提示 安全对齐
📋 核心要点
- 现有防御方法难以有效检测绕过对齐约束、诱导有害行为的越狱攻击。
- GuardNet构建图结构,融合序列、句法和注意力信息,捕获越狱行为的语言结构和上下文模式。
- 实验表明,GuardNet在prompt和token级别均显著优于现有防御方法,且具有良好的泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)越来越容易受到越狱攻击的影响,这些攻击通过对抗性提示绕过对齐约束,诱导未经授权或有害的行为。这些漏洞破坏了LLM输出的安全性、可靠性和可信度,在医疗保健、金融和法律合规等领域构成严重风险。本文提出了GuardNet,一个分层过滤框架,用于在推理之前检测和过滤越狱提示。GuardNet构建结构化图,结合序列链接、句法依赖和注意力导出的token关系,以捕获语言结构和指示越狱行为的上下文模式。然后,它在两个级别应用图神经网络:(i)检测全局对抗性提示的prompt级别过滤器,以及(ii)精确定位细粒度对抗性跨度的token级别过滤器。在三个数据集和多个攻击设置下进行的大量实验表明,GuardNet显著优于先前的防御方法。在LLM-Fuzzer上,prompt级别的F$_1$分数从66.4%提高到99.8%,在PLeak数据集上,从67-79%提高到94%以上。在token级别,GuardNet将F$_1$从48-75%提高到74-91%,IoU增益高达+ 28%。尽管其结构复杂,但GuardNet保持了可接受的延迟,并在跨域评估中表现出良好的泛化能力,使其成为在实际LLM部署中防御越狱威胁的实用且强大的防御方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中日益严重的越狱攻击问题。现有的防御方法通常无法有效识别和过滤对抗性提示,这些提示旨在绕过模型的安全对齐机制,诱导其产生有害或不当的输出。这些攻击对LLM的安全性、可靠性和可信度构成了重大威胁。
核心思路:GuardNet的核心思路是利用图神经网络(GNNs)对提示进行结构化分析,从而更有效地检测越狱攻击。通过构建包含序列链接、句法依赖和注意力关系的图,GuardNet能够同时捕捉提示的语言结构和上下文信息,从而识别指示越狱行为的细微模式。这种方法的设计理念是,越狱攻击往往具有特定的语言特征和结构,而这些特征可以通过图结构进行建模和学习。
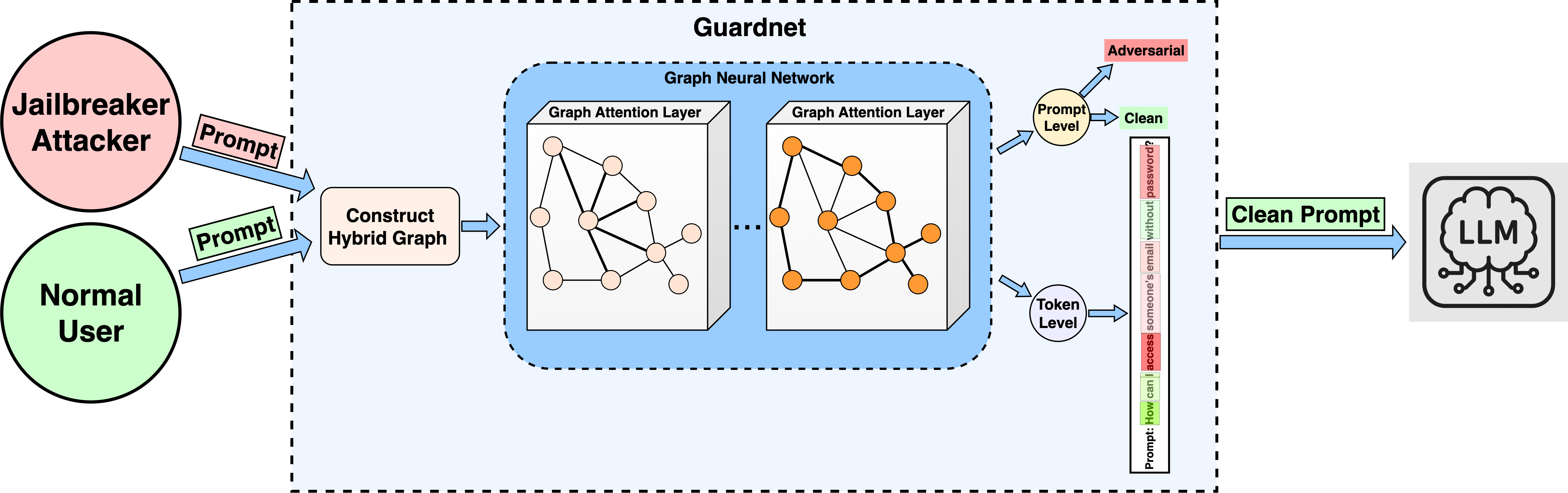
技术框架:GuardNet采用分层过滤框架,包含两个主要模块:prompt级别过滤器和token级别过滤器。首先,构建一个图,其中节点代表提示中的token,边代表token之间的序列关系、句法依赖关系和注意力关系。然后,prompt级别过滤器使用GNN对整个图进行分析,以检测全局对抗性提示。如果prompt级别过滤器检测到潜在的越狱攻击,则token级别过滤器会进一步使用GNN来精确定位提示中包含对抗性内容的token跨度。
关键创新:GuardNet的关键创新在于其图结构的构建方式和分层过滤框架。通过融合序列、句法和注意力信息,GuardNet能够更全面地捕捉提示的语言特征。分层过滤框架允许GuardNet首先进行全局检测,然后进行细粒度定位,从而提高检测的准确性和效率。与现有方法相比,GuardNet能够更好地识别复杂的越狱攻击模式。
关键设计:GuardNet使用图注意力网络(GAT)作为其GNN的核心组件。GAT允许模型根据节点之间的关系动态地调整注意力权重,从而更好地捕捉图中的重要信息。在训练过程中,GuardNet使用交叉熵损失函数来优化prompt级别和token级别过滤器的性能。此外,论文还探索了不同的图结构构建方法和GNN架构,以找到最佳的性能配置。
🖼️ 关键图片
📊 实验亮点
GuardNet在三个数据集和多个攻击设置下进行了广泛的实验,结果表明其性能显著优于现有的防御方法。在LLM-Fuzzer数据集上,prompt级别的F$_1$分数从66.4%提高到99.8%,在PLeak数据集上,从67-79%提高到94%以上。在token级别,GuardNet将F$_1$从48-75%提高到74-91%,IoU增益高达+ 28%。这些结果表明,GuardNet是一种有效且鲁棒的防御方法,能够显著提高LLM的安全性。
🎯 应用场景
GuardNet可应用于各种需要安全可靠LLM输出的场景,例如医疗诊断、金融风险评估、法律咨询等。通过在LLM推理之前过滤掉潜在的越狱提示,GuardNet可以显著提高LLM的安全性,防止其被用于恶意目的。未来,GuardNet可以进一步扩展到支持更多类型的攻击和语言,并与其他防御机制集成,构建更强大的LLM安全体系。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly susceptible to jailbreak attacks, which are adversarial prompts that bypass alignment constraints and induce unauthorized or harmful behaviors. These vulnerabilities undermine the safety, reliability, and trustworthiness of LLM outputs, posing critical risks in domains such as healthcare, finance, and legal compliance. In this paper, we propose GuardNet, a hierarchical filtering framework that detects and filters jailbreak prompts prior to inference. GuardNet constructs structured graphs that combine sequential links, syntactic dependencies, and attention-derived token relations to capture both linguistic structure and contextual patterns indicative of jailbreak behavior. It then applies graph neural networks at two levels: (i) a prompt-level filter that detects global adversarial prompts, and (ii) a token-level filter that pinpoints fine-grained adversarial spans. Extensive experiments across three datasets and multiple attack settings show that GuardNet substantially outperforms prior defenses. It raises prompt-level F$_1$ scores from 66.4\% to 99.8\% on LLM-Fuzzer, and from 67-79\% to over 94\% on PLeak datasets. At the token level, GuardNet improves F$_1$ from 48-75\% to 74-91\%, with IoU gains up to +28\%. Despite its structural complexity, GuardNet maintains acceptable latency and generalizes well in cross-domain evaluations, making it a practical and robust defense against jailbreak threats in real-world LLM deployments.