RLP: Reinforcement as a Pretraining Objective
作者: Ali Hatamizadeh, Syeda Nahida Akter, Shrimai Prabhumoye, Jan Kautz, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Yejin Choi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-26
备注: RLP introduces a new paradigm for RL-based Pretraining
💡 一句话要点
提出RLP:一种将强化学习作为预训练目标的方法,提升模型推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 预训练 思维链 推理能力 信息增益
📋 核心要点
- 现有大型语言模型训练主要依赖于下一个token预测的预训练,缺乏探索性学习机制。
- RLP将强化学习融入预训练阶段,通过信息增益奖励鼓励模型进行链式思考探索。
- 实验表明,RLP显著提升了模型在数学和科学推理任务上的性能,并具有良好的可扩展性。
📝 摘要(中文)
大型推理模型的训练范式通常始于在海量数据上使用下一个token预测损失进行预训练。强化学习虽然在扩展推理能力方面很强大,但通常只作为后训练的最后阶段引入,并且先于监督微调。本文提出了RLP,一种信息驱动的强化预训练目标,将强化学习的核心精神——探索——带到预训练的最后阶段。核心思想是将思维链视为一种探索性行为,其奖励基于其为预测未来token提供的信息增益来计算。这种训练目标本质上鼓励模型在预测接下来会发生什么之前进行独立思考,从而在预训练的早期阶段培养独立的思考行为。更具体地说,奖励信号衡量的是在同时以上下文和采样的推理链为条件时,下一个token的对数似然的增加,与仅以上下文为条件相比。这种方法产生了一种无需验证器的密集奖励信号,从而可以在预训练期间对整个文档流进行有效训练。具体来说,RLP将推理的强化学习重新定义为普通文本上的预训练目标,从而弥合了下一个token预测与有用的思维链推理的出现之间的差距。在Qwen3-1.7B-Base上使用RLP进行预训练,使八个基准数学和科学套件的总体平均水平提高了19%。通过相同的后训练,收益会累积,在AIME25和MMLU-Pro等推理繁重的任务上改进最大。将RLP应用于混合Nemotron-Nano-12B-v2将总体平均水平从42.81%提高到61.32%,并将科学推理的平均水平提高了23%,证明了跨架构和模型大小的可扩展性。
🔬 方法详解
问题定义:现有大型语言模型主要依赖于下一个token预测进行预训练,这种方法虽然简单有效,但缺乏对模型推理能力的直接训练。模型通常需要在预训练后通过监督微调或强化学习进行进一步的推理能力提升,这增加了训练的复杂性。现有方法的痛点在于,预训练阶段缺乏对探索性推理过程的建模,导致模型难以自主进行复杂推理。
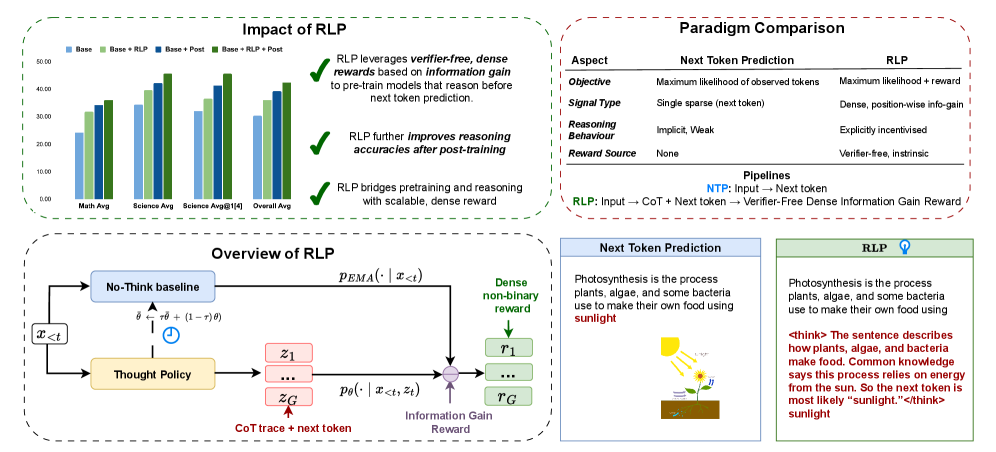
核心思路:RLP的核心思路是将强化学习的探索精神引入预训练阶段,鼓励模型在预测下一个token之前进行链式思考(Chain-of-Thought, CoT)。通过将CoT视为一种探索性行为,并根据其为预测未来token提供的信息增益来计算奖励,从而引导模型学习更有效的推理路径。这种设计旨在让模型在预训练阶段就具备独立思考的能力,为后续的推理任务打下基础。
技术框架:RLP的整体框架是在标准的语言模型预训练流程中嵌入强化学习机制。具体来说,模型在给定上下文后,会生成一个推理链(CoT),然后基于上下文和推理链预测下一个token。奖励信号的计算基于在有无推理链的情况下,预测下一个token的对数似然的差异。整个训练过程可以看作是一个策略梯度强化学习过程,目标是最大化期望奖励。主要模块包括:文本编码器、推理链生成器(通常是语言模型本身)、奖励计算模块和策略更新模块。
关键创新:RLP最重要的创新点在于将强化学习重新定义为预训练目标,从而将探索性学习融入到预训练阶段。与传统的先预训练再微调的范式不同,RLP直接在预训练阶段就训练模型的推理能力。此外,RLP使用信息增益作为奖励信号,避免了对外部验证器的依赖,从而可以对整个文档流进行高效训练。这种方法弥合了下一个token预测与有用的思维链推理之间的差距。
关键设计:RLP的关键设计包括:1) 推理链的生成方式:通常使用语言模型本身进行采样,可以采用不同的采样策略,如top-k采样或nucleus采样。2) 奖励函数的定义:奖励函数基于信息增益,即在有无推理链的情况下,预测下一个token的对数似然的差异。3) 策略更新方式:可以使用标准的策略梯度算法,如REINFORCE或PPO。4) 模型架构:RLP可以应用于各种语言模型架构,如Transformer。
🖼️ 关键图片
📊 实验亮点
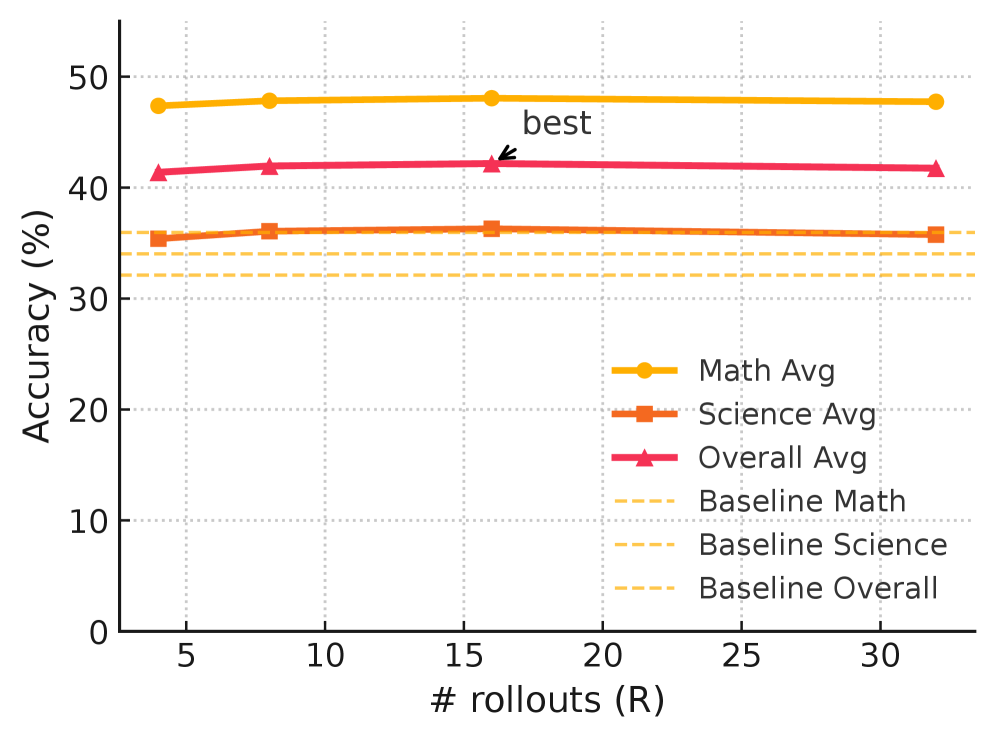
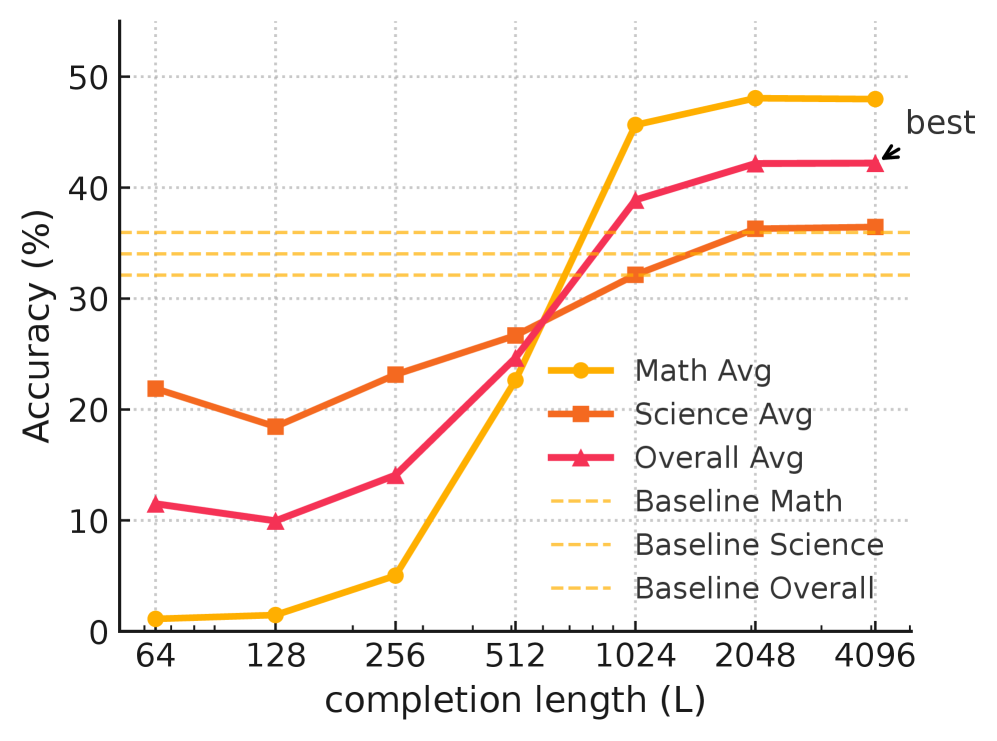
RLP在Qwen3-1.7B-Base模型上进行预训练,在八个数学和科学基准测试中,平均性能提升了19%。在Nemotron-Nano-12B-v2模型上,总体平均性能从42.81%提升至61.32%,科学推理平均性能提升了23%。在推理密集型任务(如AIME25和MMLU-Pro)上,RLP的提升尤为显著,表明其在提升模型推理能力方面的有效性。
🎯 应用场景
RLP具有广泛的应用前景,可用于提升各种自然语言处理任务中模型的推理能力,例如数学问题求解、科学推理、常识推理等。该方法可以应用于各种规模的语言模型,并可以与其他预训练技术相结合。RLP的实际价值在于降低了模型训练的成本,并提高了模型的泛化能力。未来,RLP有望成为一种标准的预训练技术,推动自然语言处理领域的发展。
📄 摘要(原文)
The dominant paradigm for training large reasoning models starts with pre-training using next-token prediction loss on vast amounts of data. Reinforcement learning, while powerful in scaling reasoning, is introduced only as the very last phase of post-training, preceded by supervised fine-tuning. While dominant, is this an optimal way of training? In this paper, we present RLP, an information-driven reinforcement pretraining objective, that brings the core spirit of reinforcement learning -- exploration -- to the last phase of pretraining. The key idea is to treat chain-of-thought as an exploratory action, with rewards computed based on the information gain it provides for predicting future tokens. This training objective essentially encourages the model to think for itself before predicting what comes next, thus teaching an independent thinking behavior earlier in the pretraining. More concretely, the reward signal measures the increase in log-likelihood of the next token when conditioning on both context and a sampled reasoning chain, compared to conditioning on context alone. This approach yields a verifier-free dense reward signal, allowing for efficient training for the full document stream during pretraining. Specifically, RLP reframes reinforcement learning for reasoning as a pretraining objective on ordinary text, bridging the gap between next-token prediction and the emergence of useful chain-of-thought reasoning. Pretraining with RLP on Qwen3-1.7B-Base lifts the overall average across an eight-benchmark math-and-science suite by 19%. With identical post-training, the gains compound, with the largest improvements on reasoning-heavy tasks such as AIME25 and MMLU-Pro. Applying RLP to the hybrid Nemotron-Nano-12B-v2 increases the overall average from 42.81% to 61.32% and raises the average on scientific reasoning by 23%, demonstrating scalability across architectures and model sizes.