A Framework for Scalable Heterogeneous Multi-Agent Adversarial Reinforcement Learning in IsaacLab
作者: Isaac Peterson, Christopher Allred, Jacob Morrey, Mario Harper
分类: cs.LG, cs.RO
发布日期: 2025-09-26
备注: 8 page, 9 figures, code https://github.com/DIRECTLab/IsaacLab-HARL
🔗 代码/项目: GITHUB
💡 一句话要点
扩展IsaacLab框架,实现异构多智能体对抗强化学习的可扩展训练
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 对抗学习 异构智能体 IsaacLab 机器人仿真
📋 核心要点
- 多智能体强化学习在动态环境中协作的机器人系统中至关重要,但现有工作主要集中在协作环境。
- 本文扩展IsaacLab框架,支持异构智能体对抗环境下的强化学习,解决实际应用中的对抗交互问题。
- 通过集成HAPPO的竞争变体,平台能够在对抗环境中高效训练和评估,并在多个基准测试中验证了框架的有效性。
📝 摘要(中文)
本文扩展了IsaacLab框架,以支持在高保真物理仿真中可扩展地训练对抗策略。我们引入了一套对抗性多智能体强化学习(MARL)环境,这些环境具有目标和能力不对称的异构智能体。我们的平台集成了异构智能体强化学习与近端策略优化(HAPPO)的竞争变体,从而能够在对抗性动态下进行高效的训练和评估。在多个基准场景中的实验表明,该框架能够为形态各异的多智能体竞争建模和训练鲁棒策略,同时保持高吞吐量和仿真真实感。代码和基准可在https://github.com/DIRECTLab/IsaacLab-HARL 获取。
🔬 方法详解
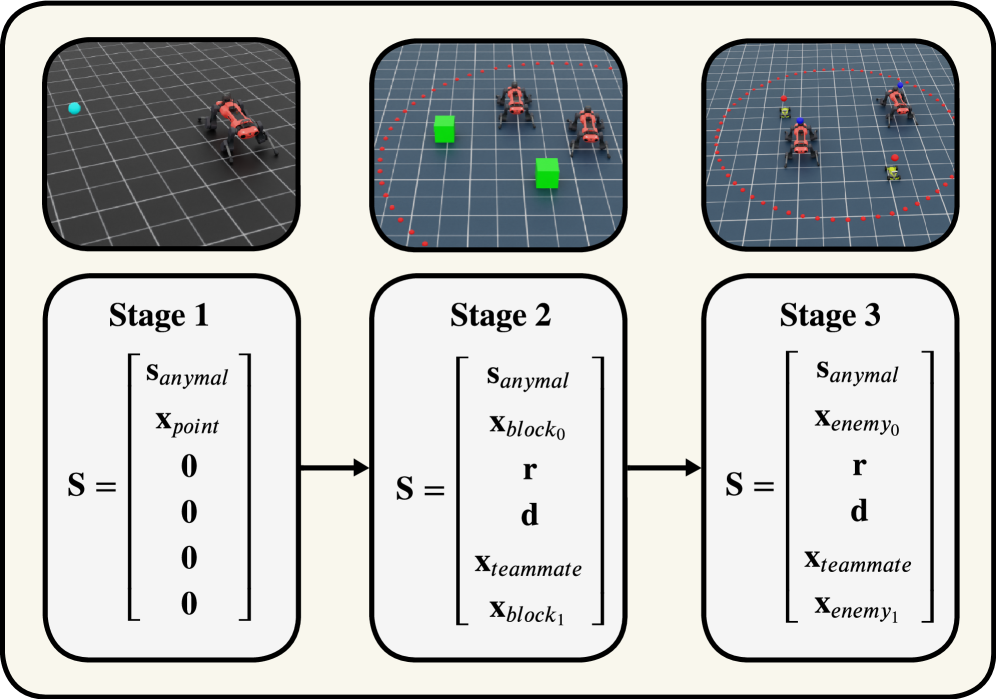
问题定义:现有的多智能体强化学习研究主要集中在协作场景,而忽略了对抗性交互在现实世界中的重要性,例如追逐-逃避、安全和竞争性操作等。此外,现有方法在处理具有不同形态和能力的异构智能体时,可能面临训练效率和策略鲁棒性的挑战。
核心思路:本文的核心思路是扩展IsaacLab框架,使其能够支持在高保真物理仿真环境中训练异构多智能体的对抗策略。通过构建一系列具有不对称目标和能力的智能体环境,并集成一种竞争性的HAPPO变体,实现高效的对抗训练和评估。
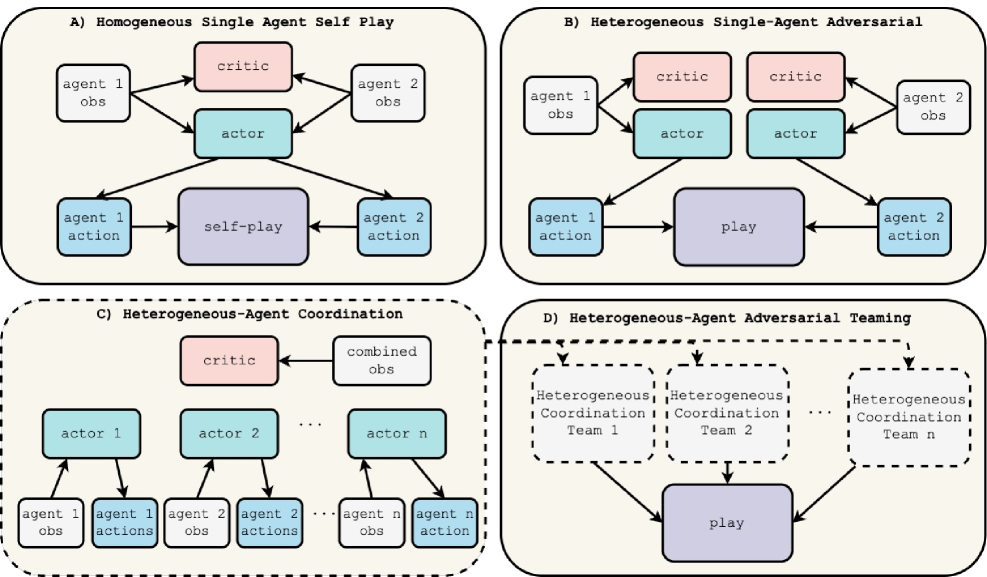
技术框架:该框架基于NVIDIA的IsaacLab平台,包含以下主要模块:1) 一系列对抗性MARL环境,用于模拟不同类型的对抗场景;2) 一种竞争性的HAPPO算法变体,用于训练异构智能体的策略;3) 一套评估工具,用于评估训练后的策略在不同场景下的性能。整体流程包括:定义对抗环境、配置HAPPO算法、进行训练、评估策略性能。
关键创新:该论文的关键创新在于:1) 扩展了IsaacLab框架,使其能够支持对抗性MARL环境的训练;2) 提出了一种适用于异构智能体对抗环境的HAPPO算法变体;3) 构建了一套包含多种对抗场景的基准测试环境,用于评估算法的性能。与现有方法相比,该框架能够更有效地训练具有不同形态和能力的智能体,并在对抗环境中实现更鲁棒的策略。
关键设计:在HAPPO算法中,针对异构智能体的特点,可能需要调整策略网络结构,例如为不同类型的智能体设计不同的输入特征和网络层。损失函数的设计需要考虑对抗性目标,例如可以使用零和奖励或对抗性损失来鼓励智能体之间的竞争。此外,还需要仔细调整训练参数,例如学习率、折扣因子和探索策略,以确保训练的稳定性和收敛性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架能够在多个基准测试场景中有效地训练异构多智能体的对抗策略。通过与现有算法的比较,证明了该框架在训练效率和策略鲁棒性方面的优势。具体性能数据(例如胜率、平均奖励等)在论文中进行了详细展示,表明该框架能够为形态各异的多智能体竞争建模和训练鲁棒策略,同时保持高吞吐量和仿真真实感。
🎯 应用场景
该研究成果可应用于机器人领域的多种对抗性场景,例如无人机追逐、入侵检测、资源竞争等。通过训练鲁棒的对抗策略,可以提高机器人在复杂和动态环境中的适应性和安全性,并为开发更智能、更可靠的机器人系统奠定基础。未来,该框架还可扩展到其他领域,例如网络安全和金融交易。
📄 摘要(原文)
Multi-Agent Reinforcement Learning (MARL) is central to robotic systems cooperating in dynamic environments. While prior work has focused on these collaborative settings, adversarial interactions are equally critical for real-world applications such as pursuit-evasion, security, and competitive manipulation. In this work, we extend the IsaacLab framework to support scalable training of adversarial policies in high-fidelity physics simulations. We introduce a suite of adversarial MARL environments featuring heterogeneous agents with asymmetric goals and capabilities. Our platform integrates a competitive variant of Heterogeneous Agent Reinforcement Learning with Proximal Policy Optimization (HAPPO), enabling efficient training and evaluation under adversarial dynamics. Experiments across several benchmark scenarios demonstrate the framework's ability to model and train robust policies for morphologically diverse multi-agent competition while maintaining high throughput and simulation realism. Code and benchmarks are available at: https://github.com/DIRECTLab/IsaacLab-HARL .