OptiMind: Teaching LLMs to Think Like Optimization Experts
作者: Xinzhi Zhang, Zeyi Chen, Humishka Zope, Hugo Barbalho, Konstantina Mellou, Marco Molinaro, Janardhan Kulkarni, Ishai Menache, Sirui Li
分类: cs.LG
发布日期: 2025-09-26 (更新: 2026-01-14)
💡 一句话要点
OptiMind:教LLM像优化专家一样思考,提升混合整数线性规划建模精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 混合整数线性规划 优化建模 错误分析 领域知识
📋 核心要点
- 现有方法在将自然语言转化为优化模型时,面临训练数据稀缺、噪声大,且缺乏领域知识利用的挑战,导致准确率受限。
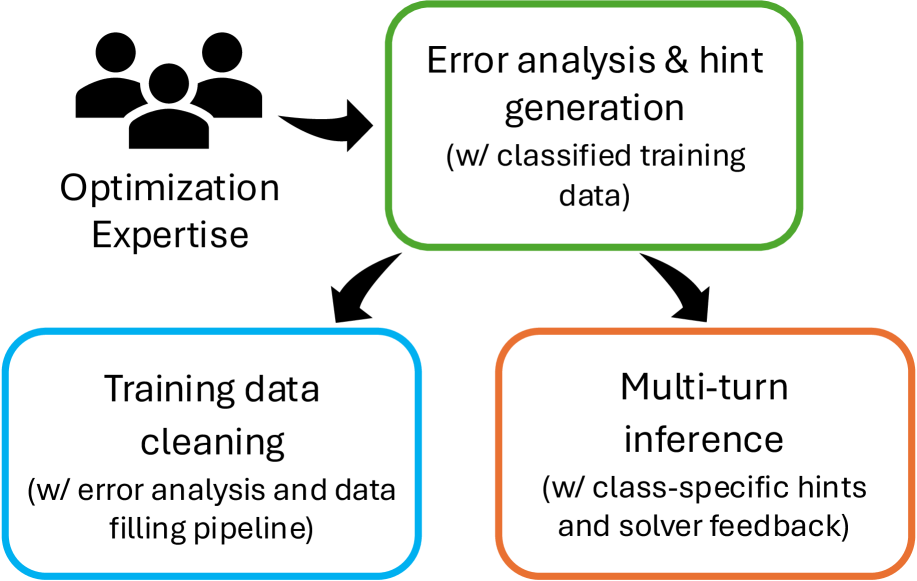
- OptiMind框架的核心思想是整合优化领域的专业知识,通过半自动的、基于类别的错误分析,指导LLM的训练和推理过程,从而避免常见错误。
- 实验结果表明,OptiMind框架显著提高了混合整数线性规划的建模准确率,在多个优化基准测试中提升了20.7%。
📝 摘要(中文)
数学规划,即将运算和决策问题用精确的数学语言表达,是各个领域的基础,但仍然是一项需要运筹学专业知识的技能密集型过程。大型语言模型在复杂推理方面的最新进展激发了人们对自动化该任务的兴趣,即将自然语言翻译成可执行的优化模型。然而,目前的方法由于缺乏领域知识,以及稀缺且嘈杂的训练数据,准确率有限。本文系统地整合了优化专业知识,以提高混合整数线性规划(数学规划的一个关键分支)的建模准确性。我们的OptiMind框架利用半自动的、基于类别的错误分析来指导训练和推理,显式地防止每个优化类中的常见错误。我们最终微调的LLM在多个优化基准测试中显著提高了20.7%的建模准确率,并在测试时缩放方法(如自洽性和多轮反馈)下保持一致的增益,从而进一步推动了LLM辅助优化建模的稳健性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在将自然语言描述转化为混合整数线性规划(MILP)模型时准确率低的问题。现有方法主要依赖于大量的训练数据,但这些数据往往稀缺且包含噪声,同时缺乏对优化领域知识的有效利用,导致LLM难以准确理解问题并生成正确的数学模型。
核心思路:OptiMind的核心思路是将优化领域的专业知识融入到LLM的训练和推理过程中。通过对LLM生成的MILP模型进行错误分析,识别出常见的错误模式,并针对这些错误模式设计相应的训练策略和推理方法,从而提高LLM的建模准确率。这种方法类似于让LLM学习“像优化专家一样思考”。
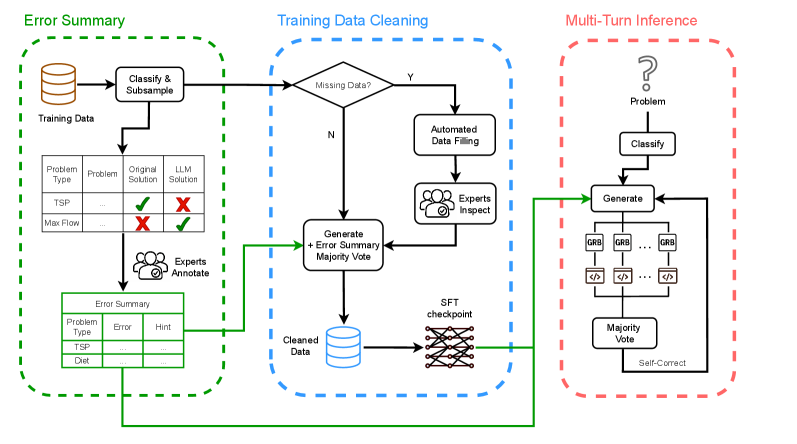
技术框架:OptiMind框架主要包含以下几个阶段:1) 数据收集与预处理:收集包含自然语言描述和对应MILP模型的训练数据,并进行清洗和标注。2) 错误分析:对LLM生成的MILP模型进行半自动的、基于类别的错误分析,识别常见的错误类型,例如变量定义错误、约束条件错误等。3) 模型训练:使用错误分析的结果指导LLM的训练过程,例如通过引入特定的损失函数或数据增强方法,来减少特定类型的错误。4) 模型推理:在推理阶段,利用错误分析的结果对LLM生成的MILP模型进行修正,例如通过规则或启发式方法来纠正常见的错误。
关键创新:OptiMind的关键创新在于将优化领域的专业知识显式地融入到LLM的训练和推理过程中。与以往主要依赖于数据驱动的方法不同,OptiMind更加注重对问题的理解和对错误模式的识别,从而能够更有效地提高LLM的建模准确率。此外,半自动的错误分析方法也降低了人工标注的成本。
关键设计:OptiMind框架的关键设计包括:1) 基于类别的错误分析:将MILP模型中的错误分为不同的类别,例如变量定义错误、约束条件错误等,并针对每个类别设计相应的处理方法。2) 半自动的错误分析:利用自动化工具辅助人工进行错误分析,从而降低人工标注的成本。3) 针对性的训练策略:根据错误分析的结果,设计针对性的训练策略,例如通过引入特定的损失函数或数据增强方法,来减少特定类型的错误。
🖼️ 关键图片

📊 实验亮点
OptiMind框架在多个优化基准测试中显著提高了混合整数线性规划的建模准确率,平均提升幅度达到20.7%。此外,在测试时采用自洽性和多轮反馈等缩放方法后,性能依然保持一致的提升,表明OptiMind具有良好的泛化能力和鲁棒性。
🎯 应用场景
OptiMind的研究成果可以应用于多个领域,例如供应链管理、资源分配、生产调度等。通过利用LLM自动将自然语言描述转化为优化模型,可以降低建模的门槛,提高建模效率,并使得非专业人士也能够方便地使用优化技术解决实际问题。未来,该技术有望进一步发展,实现更加智能化的优化建模。
📄 摘要(原文)
Mathematical programming -- the task of expressing operations and decision-making problems in precise mathematical language -- is fundamental across domains, yet remains a skill-intensive process requiring operations research expertise. Recent advances in large language models for complex reasoning have spurred interest in automating this task, translating natural language into executable optimization models. Current approaches, however, achieve limited accuracy, hindered by scarce and noisy training data without leveraging domain knowledge. In this work, we systematically integrate optimization expertise to improve formulation accuracy for mixed-integer linear programming, a key family of mathematical programs. Our OptiMind framework leverages semi-automated, class-based error analysis to guide both training and inference, explicitly preventing common mistakes within each optimization class. Our resulting fine-tuned LLM significantly improves formulation accuracy by 20.7% across multiple optimization benchmarks, with consistent gains under test-time scaling methods such as self-consistency and multi-turn feedback, enabling further progress toward robust LLM-assisted optimization formulation.