SINQ: Sinkhorn-Normalized Quantization for Calibration-Free Low-Precision LLM Weights
作者: Lorenz K. Müller, Philippe Bich, Jiawei Zhuang, Ahmet Çelik, Luca Benfenati, Lukas Cavigelli
分类: cs.LG
发布日期: 2025-09-26 (更新: 2026-01-29)
🔗 代码/项目: GITHUB
💡 一句话要点
SINQ:通过Sinkhorn归一化量化低精度LLM权重,无需校准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低精度量化 大型语言模型 后训练量化 Sinkhorn归一化 激活感知量化
📋 核心要点
- 现有低精度量化方法在4bit及以下位宽时,由于异常值影响,导致困惑度明显下降,尤其是在免校准的均匀量化中。
- SINQ通过引入第二轴缩放因子和Sinkhorn-Knopp算法,对权重矩阵的行和列方差进行归一化,从而近似激活感知量化。
- 实验表明,SINQ能显著降低困惑度差距,例如在WikiText2和C4数据集上,相对于未校准的均匀量化基线,困惑度差距降低超过50%。
📝 摘要(中文)
后训练量化已成为以低精度部署大型语言模型的最常用策略。然而,当前方法在小于等于4比特的位宽下表现出困惑度下降,部分原因是表示异常值导致与这些异常值共享相同尺度的参数出现精度问题。对于无需校准的均匀量化方法,这个问题尤其明显。我们引入SINQ,通过额外的第二轴比例因子和一个快速的Sinkhorn-Knopp风格算法来增强现有的后训练量化器,该算法寻找比例来归一化每行和每列的方差。我们表明,这通过从权重矩阵结构中恢复列比例来近似激活感知量化,这些列比例可以预测矩阵在训练期间接收到的典型激活幅度。我们的方法在层之间没有交互,并且可以很容易地应用于新的架构来量化任何线性层。我们评估了我们的方法在Qwen3模型系列等模型上。SINQ将WikiText2和C4上的困惑度差距相对于未校准的均匀量化基线降低了50%以上,计算开销为零或可忽略不计,并且可以通过将其与校准和非均匀量化级别相结合来进一步增强。代码可在https://github.com/huawei-csl/SINQ获得。
🔬 方法详解
问题定义:论文旨在解决低精度量化(尤其是4bit及以下)大型语言模型时,由于权重矩阵中存在异常值,导致模型性能显著下降的问题。现有的免校准均匀量化方法对此问题尤为敏感,因为异常值会影响共享同一缩放因子的其他权重的精度。
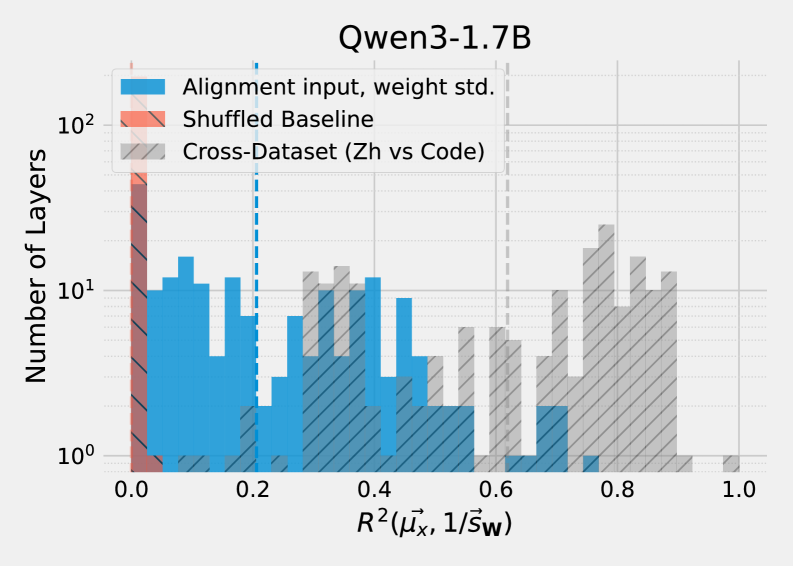
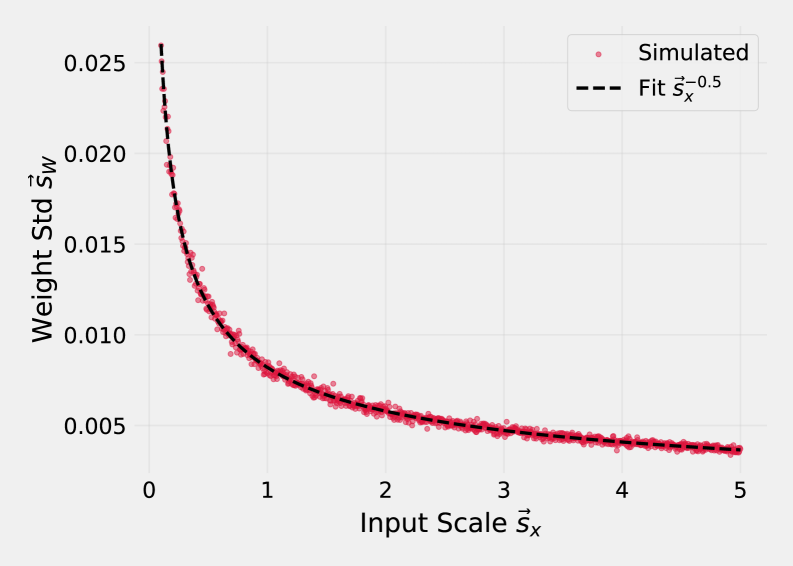
核心思路:论文的核心思路是通过对权重矩阵的行和列进行归一化,从而近似激活感知量化。具体来说,通过引入第二轴缩放因子,并使用Sinkhorn-Knopp算法来寻找合适的缩放因子,使得每行和每列的方差得到归一化。这样做的目的是为了减轻异常值的影响,并恢复权重矩阵中隐含的激活信息。
技术框架:SINQ方法可以看作是对现有后训练量化器的增强。它主要包含以下几个步骤:1) 对权重矩阵进行量化;2) 使用Sinkhorn-Knopp算法计算行和列的缩放因子;3) 将缩放因子应用于量化后的权重矩阵。该方法可以很容易地集成到现有的量化流程中,并且不需要对模型结构进行修改。
关键创新:SINQ的关键创新在于使用Sinkhorn归一化来近似激活感知量化,而无需显式地进行激活校准。通过分析权重矩阵的结构,SINQ能够恢复与激活幅度相关的列缩放因子,从而提高量化精度。此外,SINQ方法在层之间没有依赖关系,可以独立地应用于每个线性层。
关键设计:SINQ的关键设计包括:1) 使用Sinkhorn-Knopp算法进行行和列的归一化。Sinkhorn-Knopp算法是一种迭代算法,可以有效地计算行和列的缩放因子,使得矩阵的行和列和都接近于1。2) 将SINQ方法与现有的量化方法相结合。SINQ可以与均匀量化、非均匀量化以及校准技术相结合,以进一步提高量化性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SINQ能够显著提升低精度量化LLM的性能。例如,在Qwen3模型系列上,SINQ将WikiText2和C4数据集上的困惑度差距相对于未校准的均匀量化基线降低了50%以上。此外,SINQ的计算开销非常小,可以忽略不计,并且可以与现有的校准和非均匀量化技术相结合,进一步提高性能。
🎯 应用场景
SINQ方法可广泛应用于大型语言模型的低精度部署,尤其是在资源受限的边缘设备上。通过降低模型大小和计算复杂度,SINQ能够使LLM在移动设备、嵌入式系统等平台上高效运行,从而推动AI技术在各行业的应用,例如智能助手、自然语言处理、机器翻译等。
📄 摘要(原文)
Post-training quantization has emerged as the most widely used strategy for deploying large language models at low precision. Still, current methods show perplexity degradation at bit-widths less than or equal to 4, partly because representing outliers causes precision issues in parameters that share the same scales as these outliers. This problem is especially pronounced for calibration-free, uniform quantization methods. We introduce SINQ to augment existing post-training quantizers with an additional second-axis scale factor and a fast Sinkhorn-Knopp-style algorithm that finds scales to normalize per-row and per-column variances. We show that this approximates activation-aware quantization by recovering column scales from the weight matrix structure that are predictive of the typical activation magnitudes the matrix received during training. Our method has no interactions between layers and can be trivially applied to new architectures to quantize any linear layer. We evaluate our method on the Qwen3 model family, among others. SINQ reduces the perplexity gap on WikiText2 and C4 by over 50% against uncalibrated uniform quantization baselines, incurs zero to negligible compute overhead, and can be further enhanced by combining it with calibration and non-uniform quantization levels. Code is available at https://github.com/huawei-csl/SINQ.