Adaptive Margin RLHF via Preference over Preferences
作者: Yaswanth Chittepu, Prasann Singhal, Greg Durrett, Scott Niekum
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-26 (更新: 2025-11-30)
💡 一句话要点
提出DPO-PoP,利用偏好间的偏好信息自适应调整边际,提升RLHF的泛化性和对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 人类反馈 偏好学习 自适应边际 直接偏好优化 奖励模型 偏好间的偏好
📋 核心要点
- 现有RLHF方法在处理人类偏好时,未能充分考虑不同偏好强度的差异,导致泛化能力受限。
- 提出DPO-PoP,利用人类对偏好强度的判断(偏好间的偏好)来动态调整边际,从而更准确地学习奖励模型。
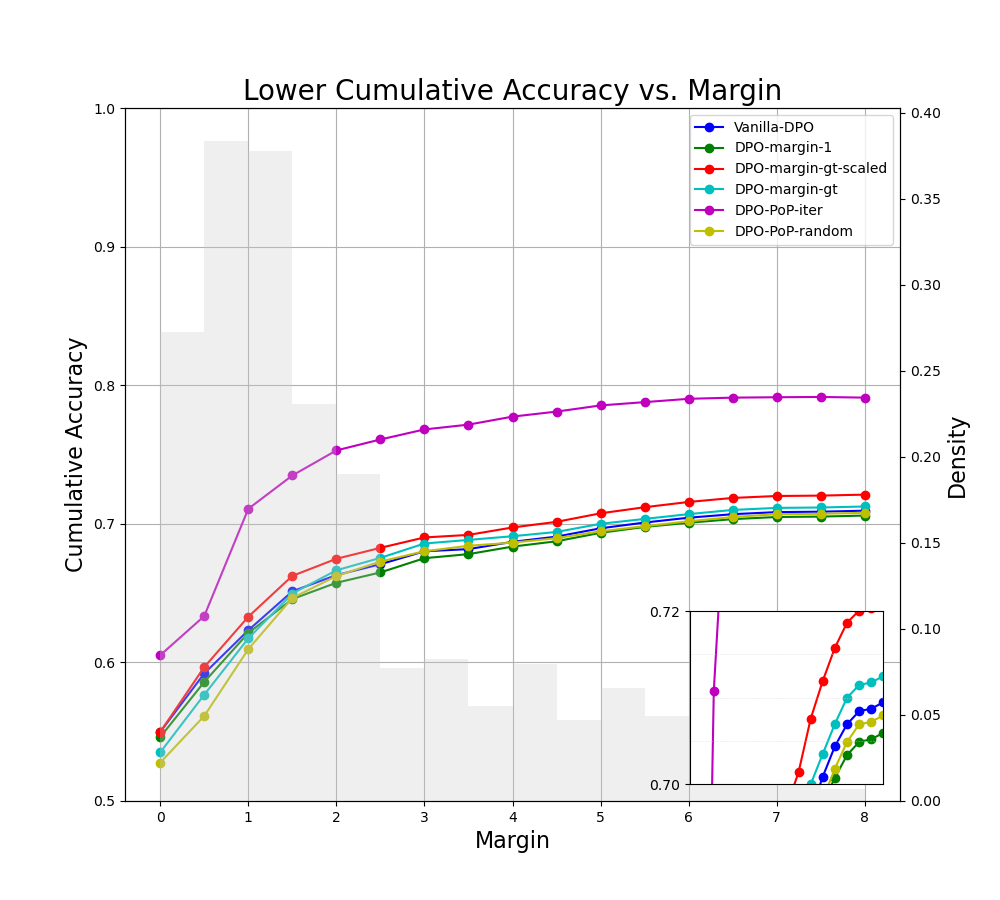
- 实验表明,DPO-PoP在UltraFeedback数据集上优于传统DPO及其变体,但判别性能和生成性能之间存在权衡。
📝 摘要(中文)
基于边际的优化对于提升分类任务的泛化性和鲁棒性至关重要。在强化学习中的人类反馈(RLHF)中,从偏好中学习奖励模型时,现有方法通常依赖于无边际、固定边际或偏好评分的简单函数。然而,这些公式通常无法解释不同偏好的不同强度,例如,某些偏好与响应之间较大的边际相关联,或者它们依赖于从评分中获得的噪声边际信息。我们认为,对偏好强度进行建模可以带来更好的泛化和更忠实的对齐。此外,许多使用自适应边际的现有方法都假设可以访问准确的偏好分数,而人类很难可靠地提供这些分数。我们提出了一种利用偏好间的偏好(preference-over-preference)的方法,即指示两个偏好中哪一个反映了更强的区分的注释。我们使用这种序数信号来推断每个数据点的自适应边际。我们引入了Direct Preference Optimization (DPO)的扩展,DPO-PoP,它结合了来自偏好间偏好监督的自适应边际,从而提高了判别和生成性能。在UltraFeedback数据集上的实验表明,我们的方法优于vanilla DPO、具有固定边际的DPO和具有ground-truth边际的DPO。此外,我们表明判别性能和生成性能之间存在权衡:提高测试分类精度,特别是通过牺牲较强偏好来正确标记较弱偏好,可能会导致生成质量下降。为了应对这种权衡,我们提出了两种采样策略来收集偏好间偏好标签:一种偏向于判别性能,另一种偏向于生成性能。
🔬 方法详解
问题定义:现有基于偏好的RLHF方法,如DPO,在学习奖励模型时,通常使用固定或简单的边际函数,无法有效处理不同偏好强度差异大的情况。人类提供的偏好信息可能存在噪声,且难以提供准确的偏好分数,导致模型泛化能力不足,对齐效果不佳。
核心思路:论文的核心思路是利用人类对偏好强度的判断(偏好间的偏好)作为监督信号,自适应地调整DPO的边际。通过学习偏好间的偏好,模型可以推断出每个数据点更合适的边际,从而更好地拟合人类的真实偏好,提高奖励模型的准确性和泛化能力。
技术框架:DPO-PoP是在DPO基础上进行的扩展。整体框架包括:1) 数据收集阶段,收集人类对不同偏好强度的判断(偏好间的偏好);2) 边际推断阶段,利用收集到的偏好间偏好数据,为每个数据点推断自适应边际;3) DPO优化阶段,将自适应边际融入DPO的损失函数中,优化策略模型。
关键创新:关键创新在于引入了偏好间的偏好作为监督信号,并将其用于自适应地调整DPO的边际。与传统DPO相比,DPO-PoP能够更好地处理不同偏好强度差异,从而提高奖励模型的准确性和泛化能力。此外,论文还提出了两种采样策略,以平衡判别性能和生成性能。
关键设计:DPO-PoP的关键设计包括:1) 偏好间偏好数据的收集方式,论文提出了两种采样策略,分别侧重于判别性能和生成性能;2) 自适应边际的推断方法,具体推断方法在论文中未详细说明,属于未知内容;3) 将自适应边际融入DPO损失函数的方式,具体实现细节在论文中未详细说明,属于未知内容。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DPO-PoP在UltraFeedback数据集上优于vanilla DPO、具有固定边际的DPO和具有ground-truth边际的DPO。论文还发现判别性能和生成性能之间存在权衡,并提出了相应的采样策略来平衡两者。具体的性能提升幅度在论文中未明确给出,属于未知内容。
🎯 应用场景
该研究成果可应用于各种需要从人类反馈中学习的场景,例如对话系统、文本生成、图像生成等。通过更准确地学习人类偏好,可以提升生成内容的质量、相关性和安全性,从而改善用户体验。
📄 摘要(原文)
Margin-based optimization is fundamental to improving generalization and robustness in classification tasks. In the context of reward model learning from preferences within Reinforcement Learning from Human Feedback (RLHF), existing methods typically rely on no margins, fixed margins, or margins that are simplistic functions of preference ratings. However, such formulations often fail to account for the varying strengths of different preferences, for example some preferences are associated with larger margins between responses, or they rely on noisy margin information derived from ratings. We argue that modeling the strength of preferences can lead to better generalization and more faithful alignment. Furthermore, many existing methods that use adaptive margins assume access to accurate preference scores, which can be difficult for humans to provide reliably. We propose an approach that leverages preferences over preferences, that is annotations indicating which of two preferences reflects a stronger distinction. We use this ordinal signal to infer adaptive margins on a per-datapoint basis. We introduce an extension to Direct Preference Optimization (DPO), DPO-PoP, that incorporates adaptive margins from preference-over-preference supervision, enabling improved discriminative and generative performance. Empirically, our method outperforms vanilla DPO, DPO with fixed margins, and DPO with ground-truth margins on the UltraFeedback dataset. Additionally, we show that there is a tradeoff between discriminative and generative performance: improving test classification accuracy, particularly by correctly labeling weaker preferences at the expense of stronger ones, can lead to a decline in generative quality. To navigate this tradeoff, we propose two sampling strategies to gather preference-over-preference labels: one favoring discriminative performance and one favoring generative performance.