Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
作者: Yulei Qin, Xiaoyu Tan, Zhengbao He, Gang Li, Haojia Lin, Zongyi Li, Zihan Xu, Yuchen Shi, Siqi Cai, Renting Rui, Shaofei Cai, Yuzheng Cai, Xuan Zhang, Sheng Ye, Ke Li, Xing Sun
分类: cs.LG, cs.AI, cs.CL, cs.CV, cs.MA
发布日期: 2025-09-26 (更新: 2025-12-07)
备注: 45 pages, 14 figures
💡 一句话要点
SPEAR:基于自模仿学习和渐进探索的Agentic强化学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Agentic强化学习 自模仿学习 课程学习 探索-利用平衡 长时程任务
📋 核心要点
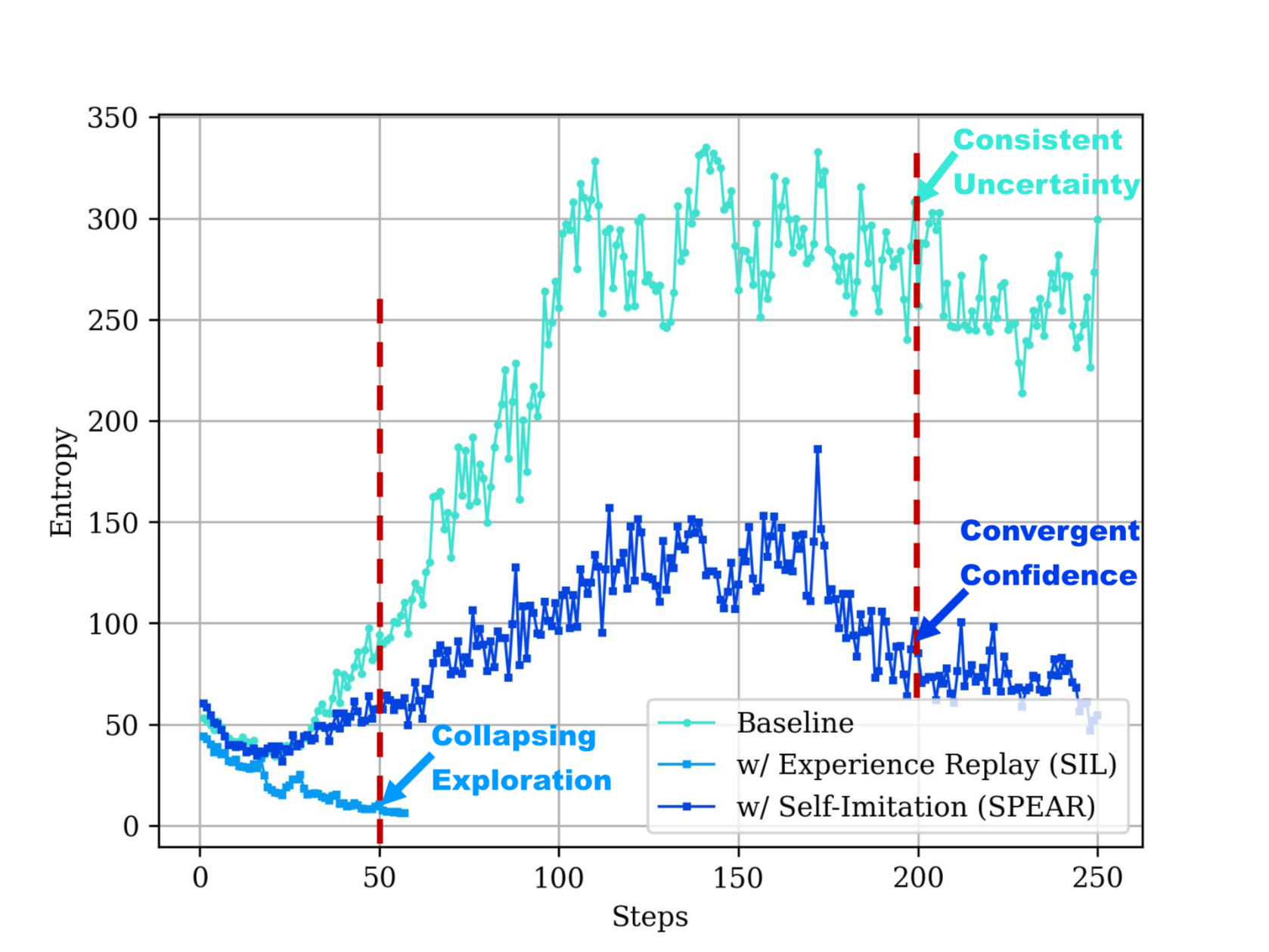
- 现有强化学习方法在Agent任务中,依赖策略熵促进探索,易导致多轮分布偏移和RL不稳定。
- SPEAR通过自模仿学习和课程调度,逐步调整策略熵,平衡探索与利用,避免熵坍塌或发散。
- 实验表明,SPEAR在多个Agent任务中显著提升了现有基线的成功率,且计算开销增加有限。
📝 摘要(中文)
强化学习是提升LLM在长时程、稀疏奖励Agent任务中战略性工具使用能力的主要范式,但面临探索-利用的根本挑战。现有研究通过策略熵来促进探索,但这种机械的熵最大化容易因多轮分布偏移导致RL不稳定。本文提出SPEAR,一种用于训练Agentic LLM的自模仿学习(SIL)方法,通过逐步调整策略熵来平衡探索-利用。SPEAR扩展了vanilla SIL,通过课程调度协调内在奖励塑造和自模仿,以加速探索和加强对成功策略的利用。结合工业RL优化技巧,SPEAR在ALFWorld和WebShop上分别将GRPO/GiGPO/Dr.BoT的成功率提高了16.1%/5.1%/8.6%和20.7%/11.8%/13.9%。在AIME24和AIME25上,SPEAR将Dr.BoT提升了3.8%和6.1%。这些收益仅带来10%-25%的额外理论复杂性,且实际运行时开销可忽略不计,证明了SPEAR的即插即用可扩展性。
🔬 方法详解
问题定义:论文旨在解决Agentic强化学习中探索-利用的难题,尤其是在长时程、稀疏奖励任务中。现有方法,如基于策略熵最大化的探索策略,容易导致多轮分布偏移,进而引起强化学习训练的不稳定性和性能下降。这些方法要么过早陷入局部最优(熵坍塌),要么无法有效利用已有的成功经验(发散)。
核心思路:SPEAR的核心思路是利用自模仿学习(SIL)的框架,并引入课程调度机制,以实现探索和利用之间的渐进平衡。通过模仿自身过往的成功经验,Agent能够更有效地学习和利用已知的有效策略。同时,课程调度机制能够根据训练的阶段性进展,动态调整探索的强度,从而避免过度的探索或过早的收敛。
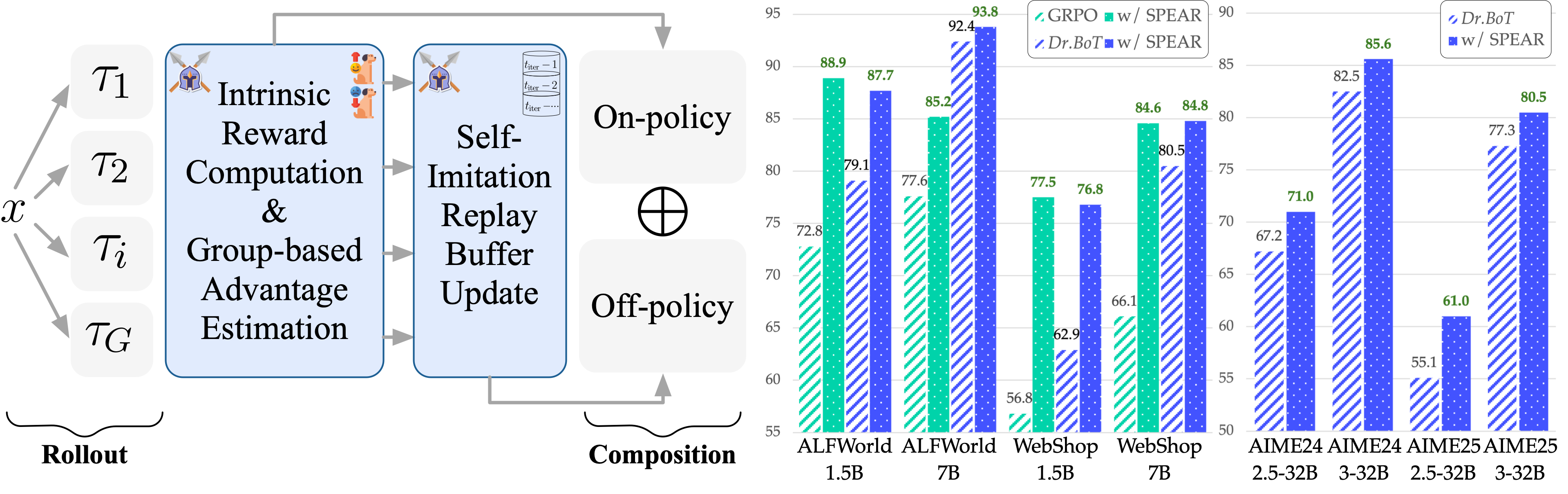
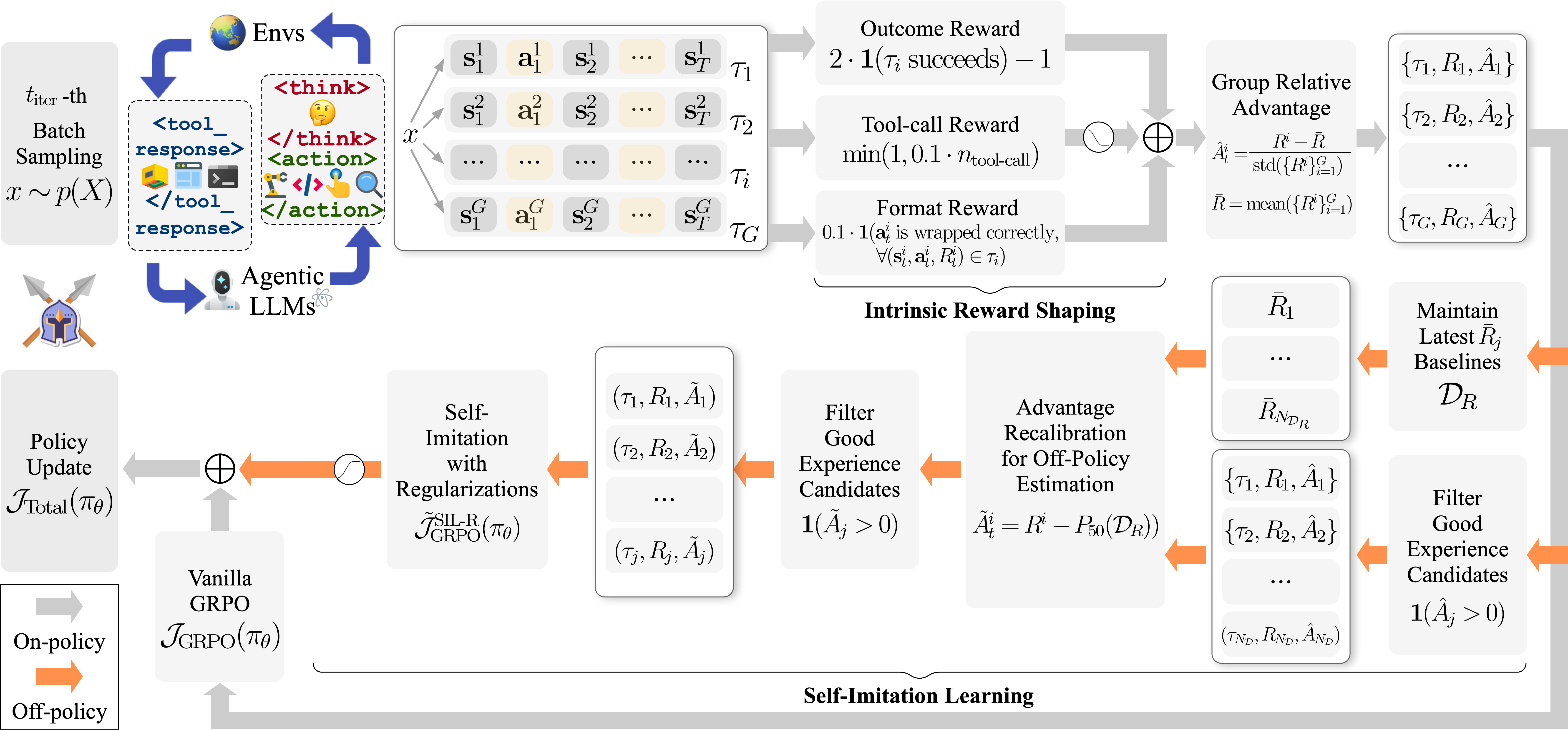
技术框架:SPEAR的技术框架主要包含以下几个阶段:1) 经验收集:Agent与环境交互,并将经验存储在回放缓冲区中。2) 奖励塑造:通过内在奖励函数,鼓励Agent进行探索,尤其是在训练初期。3) 自模仿学习:从回放缓冲区中采样成功经验,并使用这些经验来更新Agent的策略。4) 课程调度:根据训练的进展,动态调整内在奖励的权重和自模仿学习的强度。整体流程旨在引导Agent从频繁的工具交互开始,逐步过渡到对成功策略的强化利用。
关键创新:SPEAR的关键创新在于将自模仿学习与课程调度相结合,以实现探索和利用之间的动态平衡。与传统的自模仿学习方法相比,SPEAR能够根据训练的进展,自适应地调整探索的强度,从而避免了过度的探索或过早的收敛。此外,SPEAR还结合了工业界常用的强化学习优化技巧,以进一步提升性能。
关键设计:SPEAR的关键设计包括:1) 内在奖励函数的设计,用于鼓励Agent进行探索。2) 课程调度策略的设计,用于动态调整内在奖励的权重和自模仿学习的强度。3) 回放缓冲区的设计,用于存储Agent的经验,并从中采样成功经验。4) 损失函数的设计,用于结合自模仿学习和策略梯度更新Agent的策略。具体的参数设置和网络结构细节可能因不同的Agent任务而有所不同。
🖼️ 关键图片
📊 实验亮点
SPEAR在ALFWorld和WebShop等多个Agent任务中取得了显著的性能提升。具体而言,SPEAR将GRPO/GiGPO/Dr.BoT在ALFWorld上的成功率分别提高了16.1%/5.1%/8.6%,在WebShop上的成功率分别提高了20.7%/11.8%/13.9%。此外,SPEAR在AIME24和AIME25上也将Dr.BoT的性能分别提升了3.8%和6.1%。这些结果表明,SPEAR能够有效地提升Agentic强化学习的性能,且计算开销增加有限。
🎯 应用场景
SPEAR具有广泛的应用前景,可应用于各种需要智能体进行长期决策和规划的任务中,例如机器人控制、游戏AI、自动驾驶、智能客服等。通过提升智能体在复杂环境中的探索和利用能力,SPEAR能够帮助智能体更有效地完成任务,并提高其适应性和鲁棒性。该研究的实际价值在于降低了Agentic强化学习的训练难度,使其更容易应用于实际场景。
📄 摘要(原文)
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent's own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL, where a replay buffer stores good experience for off-policy update, by gradually steering the policy entropy across stages. Specifically, the proposed curriculum scheduling harmonizes intrinsic reward shaping and self-imitation to 1) expedite exploration via frequent tool interactions at the beginning, and 2) strengthen exploitation of successful tactics upon convergence towards familiarity with the environment. We also combine bag-of-tricks of industrial RL optimizations for a strong baseline Dr.BoT to demonstrate our effectiveness. In ALFWorld and WebShop, SPEAR increases the success rates of GRPO/GiGPO/Dr.BoT by up to 16.1%/5.1%/8.6% and 20.7%/11.8%/13.9%, respectively. In AIME24 and AIME25, SPEAR boosts Dr.BoT by up to 3.8% and 6.1%, respectively. Such gains incur only 10%-25% extra theoretical complexity and negligible runtime overhead in practice, demonstrating the plug-and-play scalability of SPEAR.