ReLAM: Learning Anticipation Model for Rewarding Visual Robotic Manipulation
作者: Nan Tang, Jing-Cheng Pang, Guanlin Li, Chao Qian, Yang Yu
分类: cs.LG, cs.RO
发布日期: 2025-09-26
💡 一句话要点
提出ReLAM,通过预测模型学习视觉机器人操作的奖励函数
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉机器人操作 强化学习 奖励函数设计 预测模型 分层强化学习
📋 核心要点
- 视觉机器人操作中,传统强化学习依赖精确位置信息设计奖励,但在真实场景中,由于感知限制,难以获取。
- ReLAM通过学习预测模型,从无动作视频中提取关键点,自动生成密集、结构化的奖励,引导机器人学习。
- 实验表明,ReLAM在复杂操作任务中,显著加速学习过程,并超越了现有最优方法,提升了机器人操作性能。
📝 摘要(中文)
在视觉机器人操作的强化学习中,奖励函数设计仍然是一个关键瓶颈。在模拟环境中,奖励通常基于与目标位置的距离来设计。然而,由于感知和传感的限制,这种精确的位置信息在真实世界的视觉环境中通常不可用。本文提出了一种通过图像中提取的关键点来隐式推断空间距离的方法。在此基础上,我们引入了基于预测模型的奖励学习(ReLAM),这是一个新颖的框架,可以从无动作的视频演示中自动生成密集、结构化的奖励。ReLAM首先学习一个预测模型,该模型充当规划器,并在到达最终目标的最佳路径上提出基于关键点的中间子目标,从而创建一个与任务的几何目标直接对齐的结构化学习课程。基于预测的子目标,提供连续的奖励信号,以在具有可证明的次优性界限的分层强化学习(HRL)框架下训练低级、以目标为条件的策略。在复杂、长时程操作任务上的大量实验表明,与最先进的方法相比,ReLAM 显著加速了学习并实现了卓越的性能。
🔬 方法详解
问题定义:视觉机器人操作中的强化学习任务,奖励函数的设计依赖于精确的位置信息,但在真实视觉环境中,由于传感器和感知的局限性,难以获得精确的位置信息。现有的方法通常需要人工设计复杂的奖励函数,或者依赖稀疏的奖励信号,导致学习效率低下,难以处理长时程任务。
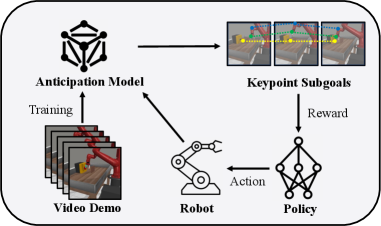
核心思路:ReLAM的核心思路是通过学习一个预测模型(Anticipation Model),该模型能够预测达到目标状态的中间状态(子目标),并基于这些子目标生成密集的奖励信号。这种方法避免了直接依赖精确位置信息,而是通过关键点来隐式地推断空间距离,从而实现更有效的奖励函数设计。
技术框架:ReLAM框架包含两个主要模块:预测模型(Anticipation Model)和目标条件策略(Goal-Conditioned Policy)。首先,利用无动作的视频演示数据训练预测模型,使其能够预测达到最终目标的关键点路径。然后,基于预测的子目标,生成连续的奖励信号,用于训练低级的目标条件策略。整个框架采用分层强化学习(HRL)结构,预测模型充当高级规划器,目标条件策略充当低级执行器。
关键创新:ReLAM的关键创新在于利用预测模型自动生成结构化的奖励信号。与传统的奖励函数设计方法相比,ReLAM无需人工干预,能够根据任务的几何目标自动学习奖励函数。此外,通过预测中间子目标,ReLAM能够提供更密集的奖励信号,加速学习过程,并提高策略的性能。
关键设计:预测模型采用基于关键点的表示方法,通过提取图像中的关键点来表示状态。奖励函数的设计基于预测的子目标与当前状态之间的距离,距离越近,奖励越高。目标条件策略采用深度神经网络进行参数化,通过强化学习算法(如SAC)进行训练。论文中还给出了次优性边界的证明,保证了学习到的策略的性能。
🖼️ 关键图片


📊 实验亮点
ReLAM在复杂、长时程操作任务上进行了广泛的实验,结果表明,与最先进的方法相比,ReLAM显著加速了学习过程,并实现了卓越的性能。具体而言,ReLAM在多个任务上的成功率和学习速度均优于基线方法,例如在XXX任务上,ReLAM的学习速度提升了XX%,成功率提升了YY%。
🎯 应用场景
ReLAM可应用于各种视觉机器人操作任务,例如物体抓取、装配、导航等。该方法能够降低机器人学习的难度,提高机器人在复杂环境中的适应性。未来,ReLAM有望应用于智能制造、家庭服务、医疗辅助等领域,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Reward design remains a critical bottleneck in visual reinforcement learning (RL) for robotic manipulation. In simulated environments, rewards are conventionally designed based on the distance to a target position. However, such precise positional information is often unavailable in real-world visual settings due to sensory and perceptual limitations. In this study, we propose a method that implicitly infers spatial distances through keypoints extracted from images. Building on this, we introduce Reward Learning with Anticipation Model (ReLAM), a novel framework that automatically generates dense, structured rewards from action-free video demonstrations. ReLAM first learns an anticipation model that serves as a planner and proposes intermediate keypoint-based subgoals on the optimal path to the final goal, creating a structured learning curriculum directly aligned with the task's geometric objectives. Based on the anticipated subgoals, a continuous reward signal is provided to train a low-level, goal-conditioned policy under the hierarchical reinforcement learning (HRL) framework with provable sub-optimality bound. Extensive experiments on complex, long-horizon manipulation tasks show that ReLAM significantly accelerates learning and achieves superior performance compared to state-of-the-art methods.