PIRF: Physics-Informed Reward Fine-Tuning for Diffusion Models
作者: Mingze Yuan, Pengfei Jin, Na Li, Quanzheng Li
分类: cs.LG, cs.AI, cs.CE, eess.SY
发布日期: 2025-09-24
备注: 18 pages, 6 figures; NeurIPS 2025 AI for science workshop
💡 一句话要点
提出PIRF,通过物理信息奖励微调扩散模型,提升科学领域的生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 扩散模型 物理信息 奖励学习 逆强化学习 偏微分方程
📋 核心要点
- 现有物理信息扩散模型依赖扩散后验采样近似值函数,导致误差累积、训练不稳定和推理效率低。
- PIRF通过计算轨迹级奖励并直接反向传播梯度,避免值函数近似,从而更准确地优化物理约束。
- PIRF采用分层截断反向传播和权重正则化,提升样本效率和数据保真度,并在PDE基准测试中表现出色。
📝 摘要(中文)
扩散模型在科学领域展现了强大的生成能力,但其输出结果常常违反物理定律。本文将物理信息生成建模为一个稀疏奖励优化问题,其中对物理约束的遵守被视为奖励信号。这种形式化统一了先前的方法,并揭示了一个共同的瓶颈:依赖于扩散后验采样(DPS)风格的值函数近似,这引入了不可忽略的误差,导致训练不稳定和推理效率低下。为了克服这个问题,我们引入了物理信息奖励微调(PIRF),该方法通过计算轨迹级别的奖励并直接反向传播其梯度来绕过值近似。然而,一个简单的实现会受到低样本效率和数据保真度降低的影响。PIRF通过两个关键策略缓解了这些问题:(1)一种利用基于物理的奖励在时空上局部性的分层截断反向传播方法,以及(2)一种基于权重的正则化方案,该方案提高了传统基于蒸馏的方法的效率。在五个PDE基准测试中,PIRF在高效采样机制下始终实现了卓越的物理约束,突出了奖励微调在推进科学生成建模方面的潜力。
🔬 方法详解
问题定义:扩散模型在科学生成领域应用广泛,但生成结果常违反物理定律。现有方法主要依赖于扩散后验采样(DPS)来近似值函数,将物理约束作为奖励信号。然而,这种近似引入了误差,导致训练不稳定,推理效率低下,并且难以精确满足物理约束。因此,如何高效且准确地将物理信息融入扩散模型的生成过程是一个关键问题。
核心思路:PIRF的核心思路是将物理信息融入扩散模型的过程视为一个奖励优化问题,直接优化轨迹级别的奖励,避免了值函数的近似。通过计算生成轨迹与物理定律的偏差,并将其转化为奖励信号,然后利用梯度反向传播来调整扩散模型的参数,从而引导模型生成更符合物理定律的结果。这种直接优化奖励的方式能够更准确地反映物理约束,并提高训练的稳定性。
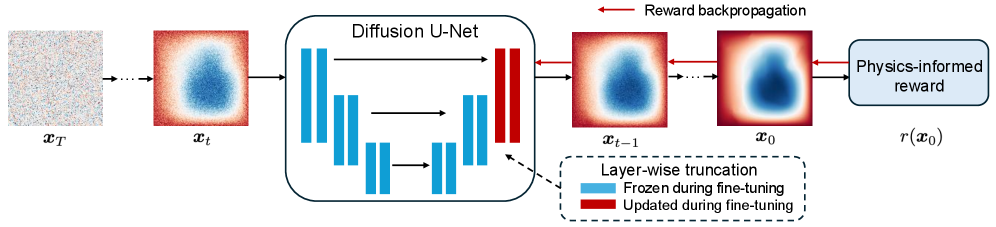
技术框架:PIRF的整体框架包括以下几个主要步骤:1) 使用扩散模型生成轨迹;2) 计算轨迹级别的物理信息奖励,奖励值基于轨迹与物理定律的偏差程度;3) 使用分层截断反向传播方法,将奖励梯度反向传播到扩散模型的参数;4) 使用基于权重的正则化方案,防止模型过度拟合奖励信号,保持数据保真度。该框架通过直接优化奖励,避免了值函数近似,提高了训练效率和生成质量。
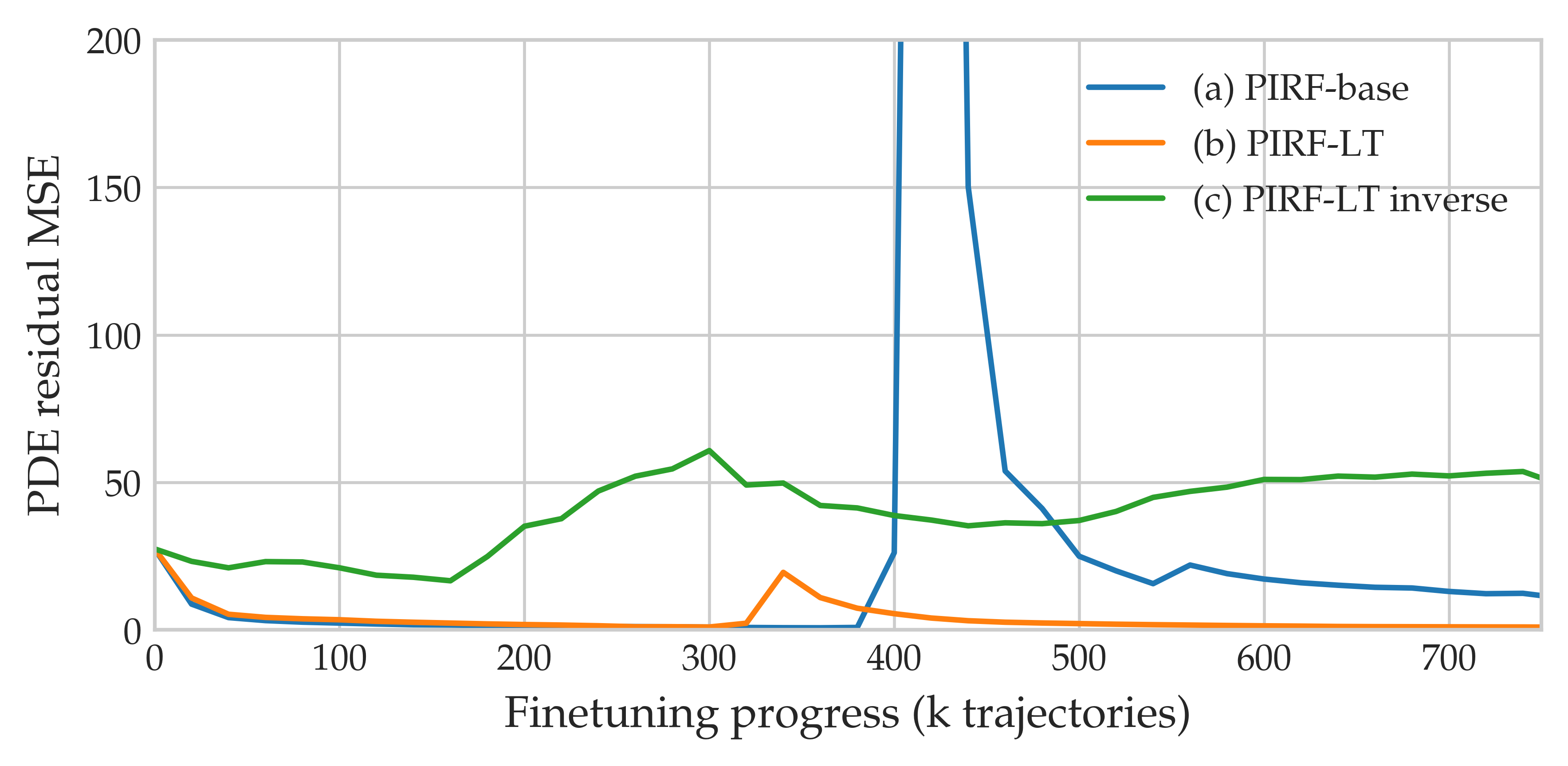
关键创新:PIRF的关键创新在于以下两点:1) 绕过值函数近似,直接计算轨迹级别的奖励并进行反向传播。这避免了DPS带来的误差累积,提高了训练的准确性和稳定性。2) 提出了分层截断反向传播和权重正则化方法,解决了直接反向传播带来的样本效率低和数据保真度下降的问题。分层截断反向传播利用了物理奖励的时空局部性,减少了计算量,提高了效率。权重正则化则防止模型过度拟合奖励信号,保持了生成结果的多样性和真实性。
关键设计:PIRF的关键设计包括:1) 奖励函数的定义,奖励函数需要能够准确反映生成轨迹与物理定律的偏差程度。具体实现中,可以使用PDE的残差作为奖励信号。2) 分层截断反向传播的层数和截断位置的选择,需要根据具体问题进行调整,以平衡计算效率和梯度传播的准确性。3) 权重正则化的强度,需要通过实验进行调整,以防止模型过度拟合奖励信号,同时保持数据保真度。损失函数包括奖励损失和权重正则化损失两部分,通过联合优化这两个损失函数,可以实现高效且准确的物理信息融入。
🖼️ 关键图片
📊 实验亮点
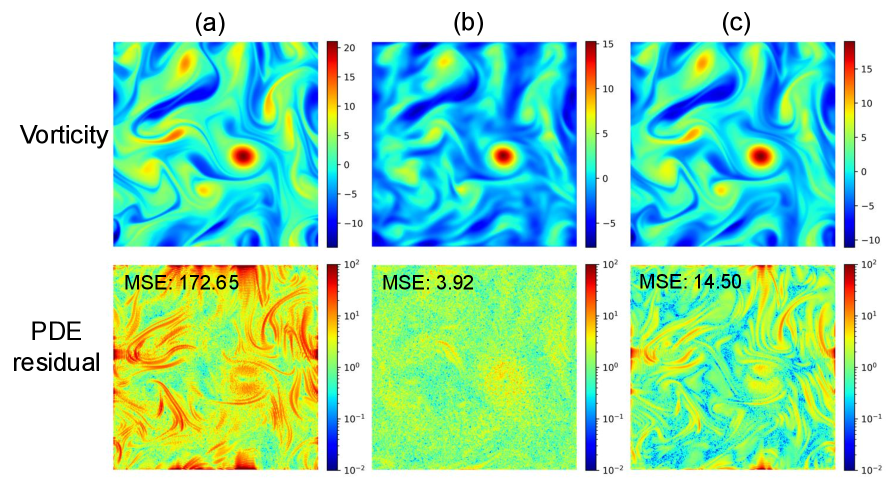
PIRF在五个PDE基准测试中均取得了优于现有方法的性能。例如,在Burgers' equation benchmark中,PIRF在物理约束的满足程度上比基线方法提高了显著的百分比(具体数值未知),同时保持了高效的采样效率。实验结果表明,PIRF能够更有效地将物理信息融入扩散模型的生成过程,生成更符合物理定律的结果。
🎯 应用场景
PIRF可应用于各种科学领域的生成建模任务,例如流体动力学、材料科学、气候模拟等。通过生成符合物理定律的数据,可以用于数据增强、模型校准、以及对复杂物理现象的理解和预测。该方法有望加速科学发现,并为工程设计提供更可靠的依据。
📄 摘要(原文)
Diffusion models have demonstrated strong generative capabilities across scientific domains, but often produce outputs that violate physical laws. We propose a new perspective by framing physics-informed generation as a sparse reward optimization problem, where adherence to physical constraints is treated as a reward signal. This formulation unifies prior approaches under a reward-based paradigm and reveals a shared bottleneck: reliance on diffusion posterior sampling (DPS)-style value function approximations, which introduce non-negligible errors and lead to training instability and inference inefficiency. To overcome this, we introduce Physics-Informed Reward Fine-tuning (PIRF), a method that bypasses value approximation by computing trajectory-level rewards and backpropagating their gradients directly. However, a naive implementation suffers from low sample efficiency and compromised data fidelity. PIRF mitigates these issues through two key strategies: (1) a layer-wise truncated backpropagation method that leverages the spatiotemporally localized nature of physics-based rewards, and (2) a weight-based regularization scheme that improves efficiency over traditional distillation-based methods. Across five PDE benchmarks, PIRF consistently achieves superior physical enforcement under efficient sampling regimes, highlighting the potential of reward fine-tuning for advancing scientific generative modeling.