Multi-level Diagnosis and Evaluation for Robust Tabular Feature Engineering with Large Language Models
作者: Yebin Lim, Susik Yoon
分类: cs.LG, cs.AI
发布日期: 2025-09-20
备注: Accepted to Findings of EMNLP 2025
💡 一句话要点
提出多层次诊断评估框架,提升大语言模型在表格特征工程中的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 表格数据 特征工程 鲁棒性评估 多层次诊断 少样本学习 关键变量 决策边界
📋 核心要点
- 现有大语言模型在表格数据特征工程中表现出潜力,但生成结果的可变性导致其可靠性面临挑战。
- 论文提出多层次诊断评估框架,从关键变量、关系和决策边界值三个层面评估LLM的鲁棒性。
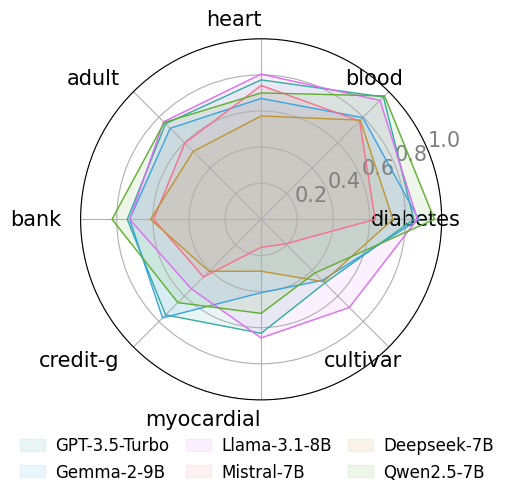
- 实验证明LLM鲁棒性因数据集而异,高质量LLM特征可显著提升少样本预测性能,最高达10.52%。
📝 摘要(中文)
本文提出了一种多层次诊断和评估框架,用于评估大语言模型(LLM)在表格数据特征工程中的鲁棒性。由于LLM生成输出的可变性,其可靠性一直备受关注。该框架侧重于三个主要因素:关键变量、关系以及预测目标类别的决策边界值,从而在不同领域评估LLM的鲁棒性。实验表明,LLM的鲁棒性在不同数据集上差异显著,高质量的LLM生成特征可以将少样本预测性能提高高达10.52%。这项工作为评估和增强LLM驱动的特征工程在各个领域的可靠性开辟了新的方向。
🔬 方法详解
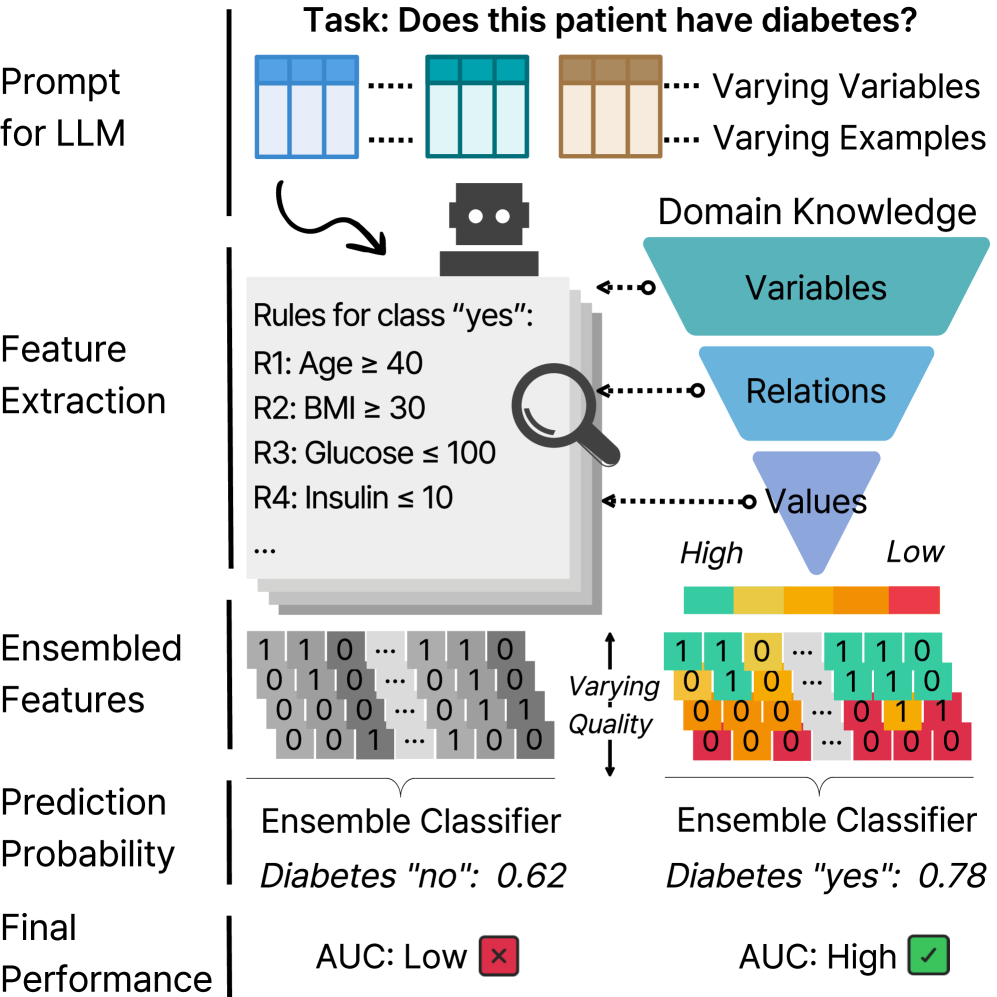
问题定义:现有方法利用大语言模型进行表格数据特征工程时,由于LLM生成结果的不确定性,导致特征工程的鲁棒性和可靠性难以保证。尤其是在不同领域的数据集上,LLM的表现差异很大,缺乏有效的评估和诊断工具来识别和解决这些问题。
核心思路:论文的核心思路是通过构建一个多层次的诊断和评估框架,从多个维度对LLM生成的特征进行分析,从而量化LLM在特征工程中的鲁棒性。该框架关注关键变量、变量关系以及决策边界值,这些因素直接影响模型的预测性能。通过诊断这些因素,可以识别LLM在哪些方面表现良好,哪些方面存在不足,从而指导后续的优化。
技术框架:该框架包含以下几个主要阶段:1) 特征生成:使用LLM生成候选特征;2) 关键变量诊断:识别对目标变量影响最大的特征;3) 关系诊断:分析特征之间的关系,例如线性相关性、非线性相关性等;4) 决策边界值诊断:评估LLM生成的特征在区分不同类别时的能力;5) 鲁棒性评估:综合以上诊断结果,评估LLM在特定数据集上的鲁棒性。
关键创新:该论文的关键创新在于提出了一个多层次的诊断和评估框架,能够系统地评估LLM在表格数据特征工程中的鲁棒性。与以往的研究只关注LLM的生成能力不同,该框架更关注LLM生成特征的质量和可靠性。通过对关键变量、关系和决策边界值的诊断,可以深入了解LLM的优势和不足,从而指导后续的优化。
关键设计:在关键变量诊断方面,可以使用特征重要性评估方法,例如基于树模型的特征重要性或基于梯度的方法。在关系诊断方面,可以使用相关性分析、互信息等方法。在决策边界值诊断方面,可以使用分类性能指标,例如准确率、精确率、召回率等。此外,还可以设计特定的损失函数来惩罚LLM生成的不鲁棒特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM的鲁棒性在不同数据集上差异显著。高质量的LLM生成特征可以将少样本预测性能提高高达10.52%。这表明,通过有效的诊断和评估,可以充分发挥LLM在特征工程中的潜力,显著提升模型性能。
🎯 应用场景
该研究成果可应用于金融、医疗、电商等多个领域,提升表格数据分析的自动化程度和模型预测的准确性。通过诊断和评估LLM在特征工程中的鲁棒性,可以更好地利用LLM的潜力,降低模型部署的风险,并为未来的LLM驱动的特征工程研究提供指导。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have shown promise in feature engineering for tabular data, but concerns about their reliability persist, especially due to variability in generated outputs. We introduce a multi-level diagnosis and evaluation framework to assess the robustness of LLMs in feature engineering across diverse domains, focusing on the three main factors: key variables, relationships, and decision boundary values for predicting target classes. We demonstrate that the robustness of LLMs varies significantly over different datasets, and that high-quality LLM-generated features can improve few-shot prediction performance by up to 10.52%. This work opens a new direction for assessing and enhancing the reliability of LLM-driven feature engineering in various domains.