Learning from Observation: A Survey of Recent Advances
作者: Returaj Burnwal, Hriday Mehta, Nirav Pravinbhai Bhatt, Balaraman Ravindran
分类: cs.LG, cs.AI, cs.RO, stat.ML
发布日期: 2025-09-20
💡 一句话要点
综述学习自观察模仿学习:回顾最新进展与未来方向
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 学习自观察 状态模仿 强化学习 离线强化学习 机器人 行为克隆 逆强化学习
📋 核心要点
- 传统模仿学习依赖专家动作信息,但在许多实际场景中,获取专家动作非常困难,限制了其应用。
- 本文提出一个学习自观察(LfO)的通用框架,用于分析和分类现有LfO方法,并连接相关领域。
- 该综述识别了LfO领域中的开放性问题,并为未来的研究方向提供了建议,具有重要的指导意义。
📝 摘要(中文)
模仿学习(IL)算法提供了一种有效的训练智能体的方法,通过模仿专家的行为而无需奖励函数。IL算法通常需要访问专家演示中的状态和动作信息。虽然专家动作可以提供详细的指导,但对于专家动作难以获得的实际应用,要求这样的动作信息可能是不切实际的。为了解决这个限制,学习自观察(LfO)或仅状态模仿学习(SOIL)的概念最近受到了关注,其中模仿者只能访问专家状态访问信息。在本文中,我们提出了一个LfO框架,并使用它来调查和分类现有的LfO方法,包括它们的轨迹构建、假设和算法设计选择。本综述还联系了几个相关领域,如离线强化学习、基于模型的强化学习和分层强化学习。最后,我们使用我们的框架来识别开放问题,并提出未来的研究方向。
🔬 方法详解
问题定义:论文旨在解决模仿学习中对专家动作信息依赖的问题。传统的模仿学习算法需要同时获取专家的状态和动作信息,但在许多实际场景中,获取专家的动作信息非常困难或成本高昂。例如,在医疗机器人手术中,虽然可以观察到医生的手术过程(状态),但很难精确记录医生的每一个动作细节。因此,如何仅通过观察专家状态来学习策略,成为了一个重要的研究问题。
核心思路:论文的核心思路是构建一个统一的框架来分析和分类现有的学习自观察(LfO)方法。通过这个框架,可以清晰地了解不同LfO方法的轨迹构建方式、假设条件以及算法设计选择。此外,该框架还旨在连接LfO与离线强化学习、基于模型的强化学习和分层强化学习等相关领域,从而促进跨领域的研究和借鉴。
技术框架:论文提出的LfO框架主要包含以下几个关键模块: 1. 轨迹构建:如何从专家状态序列中构建可供学习的轨迹数据。 2. 假设条件:不同LfO方法对环境和专家行为做出的假设。 3. 算法设计:具体算法的设计,包括目标函数、优化方法等。 通过这个框架,可以将现有的LfO方法进行分类和比较,从而更好地理解它们的优缺点和适用场景。
关键创新:该论文的主要创新在于提出了一个统一的LfO框架,用于分析和分类现有的LfO方法。这个框架不仅可以帮助研究人员更好地理解现有方法,还可以促进新方法的开发。此外,该论文还强调了LfO与相关领域(如离线强化学习)的联系,为未来的研究方向提供了新的思路。
关键设计:论文并没有提出具体的算法设计,而是在框架下分析了现有算法的关键设计选择,例如: * 轨迹对齐方法:如何将模仿者的状态与专家的状态进行对齐,以便进行学习。 * 逆强化学习的应用:如何从专家状态序列中推断出奖励函数,然后使用强化学习算法进行学习。 * 生成对抗网络的应用:如何使用GAN来生成与专家状态相似的状态,从而扩充训练数据。
🖼️ 关键图片
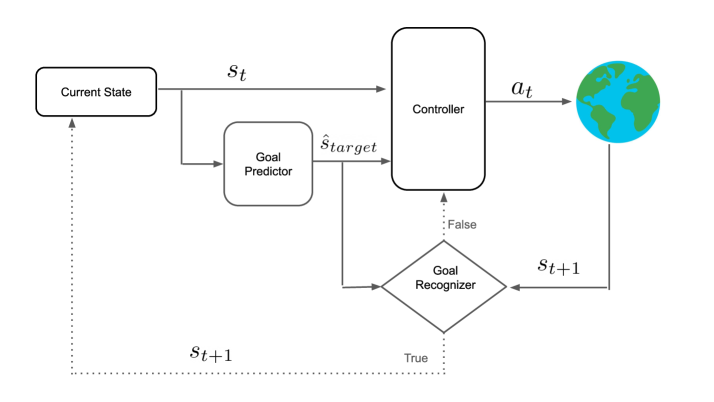

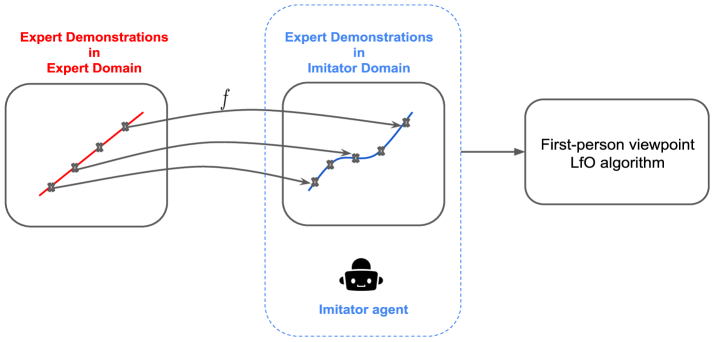
📊 实验亮点
该论文是一篇综述性文章,没有具体的实验结果。其亮点在于对现有学习自观察(LfO)方法进行了系统的分类和分析,并提出了一个统一的框架。该框架可以帮助研究人员更好地理解现有方法,并为未来的研究方向提供了新的思路。此外,该论文还强调了LfO与相关领域(如离线强化学习)的联系,为跨领域的研究提供了借鉴。
🎯 应用场景
学习自观察模仿学习在机器人控制、自动驾驶、医疗机器人等领域具有广泛的应用前景。例如,可以利用该技术训练机器人模仿人类专家的操作,而无需记录人类专家的具体动作。这可以大大降低训练成本,并提高机器人的智能化水平。此外,该技术还可以用于从历史数据中学习策略,例如,从历史交通数据中学习自动驾驶策略。
📄 摘要(原文)
Imitation Learning (IL) algorithms offer an efficient way to train an agent by mimicking an expert's behavior without requiring a reward function. IL algorithms often necessitate access to state and action information from expert demonstrations. Although expert actions can provide detailed guidance, requiring such action information may prove impractical for real-world applications where expert actions are difficult to obtain. To address this limitation, the concept of learning from observation (LfO) or state-only imitation learning (SOIL) has recently gained attention, wherein the imitator only has access to expert state visitation information. In this paper, we present a framework for LfO and use it to survey and classify existing LfO methods in terms of their trajectory construction, assumptions and algorithm's design choices. This survey also draws connections between several related fields like offline RL, model-based RL and hierarchical RL. Finally, we use our framework to identify open problems and suggest future research directions.