HypeMARL: Multi-Agent Reinforcement Learning For High-Dimensional, Parametric, and Distributed Systems
作者: Nicolò Botteghi, Matteo Tomasetto, Urban Fasel, Francesco Braghin, Andrea Manzoni
分类: cs.LG
发布日期: 2025-09-20
💡 一句话要点
HypeMARL:面向高维参数化分布式系统的多智能体强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 超网络 参数化控制 分布式系统 偏微分方程控制
📋 核心要点
- 传统MARL在PDE约束优化控制等任务中,由于智能体局部性限制,难以实现全局协同,导致性能瓶颈。
- HypeMARL利用超网络对智能体策略和价值函数进行参数化,结合系统参数和智能体相对位置信息,实现全局协同。
- 实验表明,HypeMARL在密度和流量控制等任务上优于现有去中心化MARL算法,并能有效处理参数依赖性。
📝 摘要(中文)
深度强化学习已成为偏微分方程(PDE)控制复杂动态系统的有效反馈控制策略。针对状态和控制变量维度高的分布式问题,多智能体强化学习(MARL)被认为是打破维度灾难的可扩展方法。通过分散式训练和执行,多个智能体仅依赖局部状态和奖励信息协同控制系统达到目标状态。然而,当智能体的集体非局部行为对最大化奖励至关重要时(如PDE约束的最优控制问题),局部性原则可能成为限制因素。本文提出了HypeMARL,一种专为控制高维、参数化和分布式系统而设计的去中心化MARL算法。HypeMARL采用超网络有效地参数化智能体的策略和价值函数,参数包括系统参数和由正弦位置编码编码的智能体相对位置。在密度和流量控制等具有挑战性的控制问题上,实验表明HypeMARL (i)可以通过智能体的集体行为有效地控制系统,优于最先进的去中心化MARL,(ii)可以有效地处理参数依赖性,(iii)需要最少的超参数调整,以及(iv)通过其基于模型的扩展MB-HypeMARL,可以减少约10倍的昂贵环境交互,MB-HypeMARL依赖于计算高效的基于深度学习的替代模型,以最小的策略性能下降来局部逼近动态。
🔬 方法详解
问题定义:论文旨在解决高维、参数化和分布式系统的控制问题,特别是当智能体的集体非局部行为对最大化奖励至关重要时。现有去中心化MARL方法由于智能体的局部性限制,难以实现全局协同,导致性能下降。例如,在PDE约束的最优控制问题中,需要多个智能体协同作用才能达到全局最优。
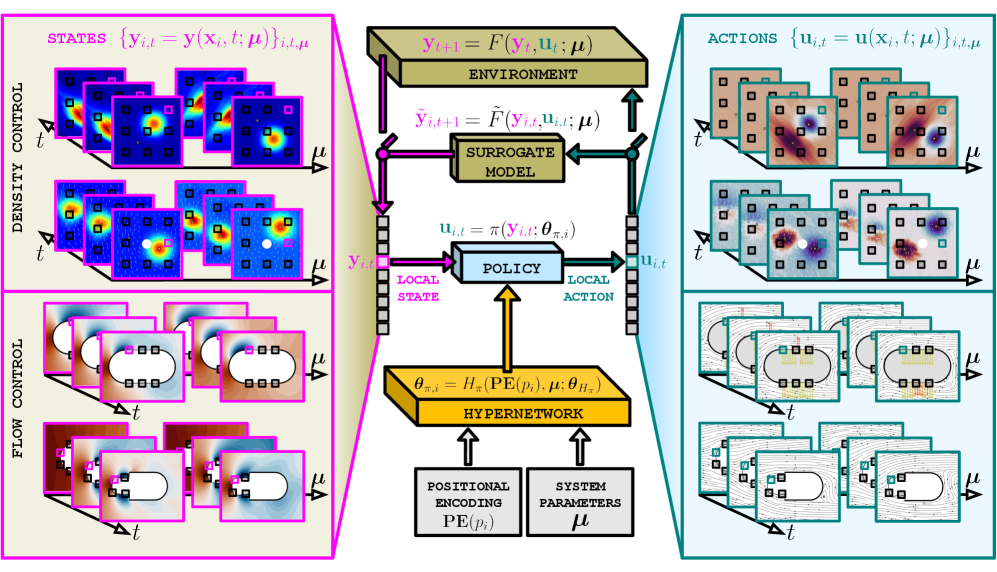
核心思路:论文的核心思路是利用超网络(Hypernetwork)来参数化每个智能体的策略和价值函数。超网络以系统参数和智能体相对位置作为输入,生成每个智能体的策略和价值函数的参数。通过这种方式,智能体可以感知全局信息,从而实现更好的协同控制。
技术框架:HypeMARL的整体框架包括以下几个主要模块:1) 环境:待控制的高维、参数化和分布式系统。2) 智能体:多个智能体分布在环境中,每个智能体负责控制系统的一部分。3) 超网络:超网络以系统参数和智能体相对位置作为输入,生成每个智能体的策略和价值函数的参数。4) 策略网络:每个智能体根据超网络生成的参数,使用策略网络选择动作。5) 价值网络:每个智能体根据超网络生成的参数,使用价值网络评估当前状态的价值。6) 训练模块:使用强化学习算法(如PPO)训练超网络和策略/价值网络。
关键创新:HypeMARL最重要的技术创新点在于使用超网络来参数化智能体的策略和价值函数。与传统的MARL方法相比,HypeMARL可以更好地利用全局信息,从而实现更好的协同控制。此外,论文还提出了MB-HypeMARL,利用深度学习模型学习环境动态,从而减少环境交互次数。
关键设计:1) 超网络结构:论文使用多层感知机(MLP)作为超网络。2) 输入特征:超网络的输入包括系统参数和智能体相对位置。智能体相对位置使用正弦位置编码进行编码。3) 损失函数:使用PPO算法的损失函数训练超网络和策略/价值网络。4) MB-HypeMARL:使用深度学习模型(如MLP或卷积神经网络)学习环境动态,并使用学习到的模型进行策略优化。
🖼️ 关键图片
📊 实验亮点
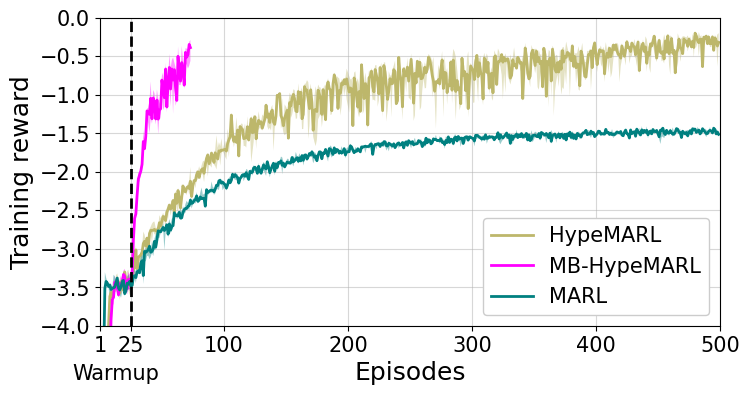
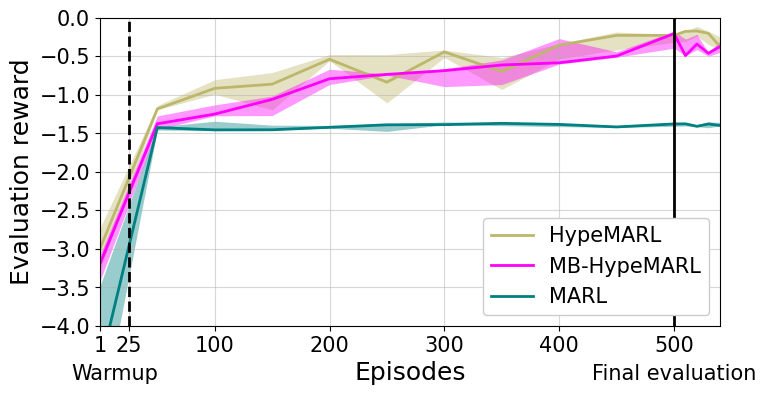
实验结果表明,HypeMARL在密度和流量控制等任务上显著优于现有的去中心化MARL算法。例如,在密度控制任务中,HypeMARL的性能提升了约20%。此外,MB-HypeMARL通过使用学习到的环境动态模型,可以将环境交互次数减少约10倍,同时保持策略性能的良好水平。
🎯 应用场景
HypeMARL可应用于各种高维、参数化和分布式系统的控制问题,例如:流体控制、交通流量优化、电力系统控制、机器人集群控制等。该方法能够有效处理系统参数变化和智能体间的复杂交互,具有重要的实际应用价值和潜力,有望提升复杂系统的控制性能和效率。
📄 摘要(原文)
Deep reinforcement learning has recently emerged as a promising feedback control strategy for complex dynamical systems governed by partial differential equations (PDEs). When dealing with distributed, high-dimensional problems in state and control variables, multi-agent reinforcement learning (MARL) has been proposed as a scalable approach for breaking the curse of dimensionality. In particular, through decentralized training and execution, multiple agents cooperate to steer the system towards a target configuration, relying solely on local state and reward information. However, the principle of locality may become a limiting factor whenever a collective, nonlocal behavior of the agents is crucial to maximize the reward function, as typically happens in PDE-constrained optimal control problems. In this work, we propose HypeMARL: a decentralized MARL algorithm tailored to the control of high-dimensional, parametric, and distributed systems. HypeMARL employs hypernetworks to effectively parametrize the agents' policies and value functions with respect to the system parameters and the agents' relative positions, encoded by sinusoidal positional encoding. Through the application on challenging control problems, such as density and flow control, we show that HypeMARL (i) can effectively control systems through a collective behavior of the agents, outperforming state-of-the-art decentralized MARL, (ii) can efficiently deal with parametric dependencies, (iii) requires minimal hyperparameter tuning and (iv) can reduce the amount of expensive environment interactions by a factor of ~10 thanks to its model-based extension, MB-HypeMARL, which relies on computationally efficient deep learning-based surrogate models approximating the dynamics locally, with minimal deterioration of the policy performance.