Bayesian Ego-graph Inference for Networked Multi-Agent Reinforcement Learning
作者: Wei Duan, Jie Lu, Junyu Xuan
分类: cs.MA, cs.LG
发布日期: 2025-09-20 (更新: 2025-12-16)
备注: Accepted at NeurIPS 2025 https://openreview.net/forum?id=3qeTs05bRL
💡 一句话要点
提出BayesG,通过贝叶斯推断学习稀疏交互结构,解决网络化多智能体强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 网络化学习 贝叶斯推断 图神经网络 变分推断
📋 核心要点
- 现有Networked-MARL方法依赖静态邻域,难以适应动态异构环境,中心化方法又不适用于实际去中心化系统。
- BayesG通过贝叶斯变分推断学习稀疏的、上下文感知的交互结构,每个智能体基于采样的自我图进行决策。
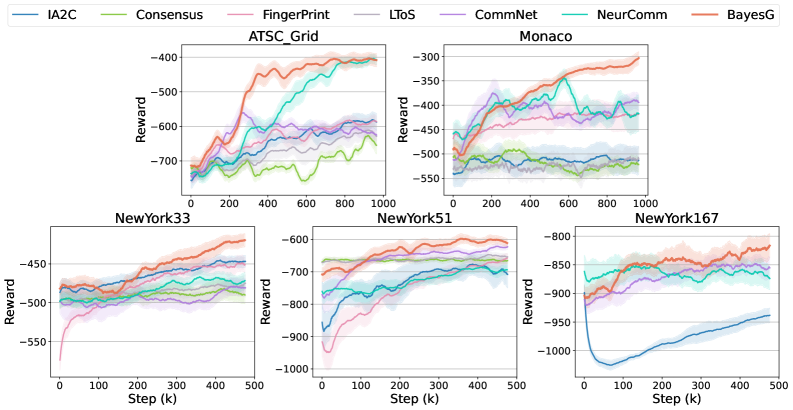
- 实验表明,BayesG在交通控制任务中优于现有MARL基线,展现出良好的可扩展性、效率和性能。
📝 摘要(中文)
在网络化多智能体强化学习(Networked-MARL)中,去中心化的智能体必须在局部可观测性和固定物理图上的受限通信下行动。现有方法通常假设静态邻域,限制了对动态或异构环境的适应性。虽然中心化框架可以学习动态图,但它们对全局状态访问和中心化基础设施的依赖在实际去中心化系统中是不切实际的。我们提出了一种基于随机图的网络化MARL策略,其中每个智能体根据其局部物理邻域上的采样子图来决定其决策。在此基础上,我们引入了BayesG,一个去中心化的actor框架,它通过贝叶斯变分推断学习稀疏的、上下文感知的交互结构。每个智能体在其自我图上运行,并采样一个潜在的通信掩码来指导消息传递和策略计算。变分分布使用证据下界(ELBO)目标与策略一起进行端到端训练,使智能体能够共同学习交互拓扑和决策策略。BayesG在具有多达167个智能体的大规模交通控制任务中优于强大的MARL基线,展示了卓越的可扩展性、效率和性能。
🔬 方法详解
问题定义:论文旨在解决网络化多智能体强化学习中,智能体如何在局部观测和受限通信条件下,学习动态、异构环境下的最优策略的问题。现有方法主要痛点在于依赖静态邻域,无法有效适应环境变化,而中心化方法又难以在实际去中心化系统中应用。
核心思路:论文的核心思路是让每个智能体学习一个稀疏的、上下文感知的交互结构,从而动态地调整其通信和决策策略。通过贝叶斯变分推断,智能体可以学习一个潜在的通信掩码,用于指导消息传递和策略计算。这种方法允许智能体根据当前环境动态地选择重要的邻居进行交互,从而提高学习效率和适应性。
技术框架:BayesG是一个去中心化的actor框架。每个智能体维护一个自我图,该图表示其局部物理邻域。智能体首先从一个变分分布中采样一个潜在的通信掩码,该掩码决定了哪些邻居参与消息传递。然后,智能体使用这个掩码来过滤来自邻居的消息,并将过滤后的消息传递给其策略网络。策略网络根据接收到的消息和自身的局部观测来生成动作。整个框架通过最大化证据下界(ELBO)进行端到端训练。
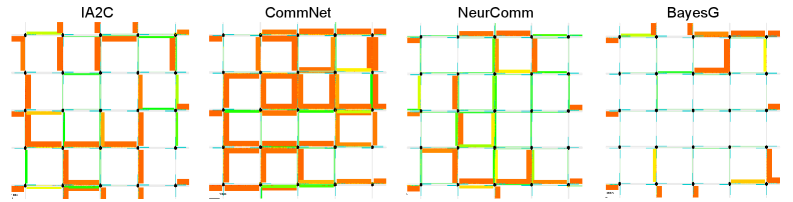
关键创新:最重要的技术创新点在于使用贝叶斯变分推断来学习稀疏的交互结构。与现有方法相比,BayesG不需要预先定义静态邻域,而是可以根据环境动态地学习哪些邻居是重要的。这种方法可以提高学习效率和适应性,尤其是在动态和异构环境中。
关键设计:变分分布通常使用高斯分布或范畴分布来建模。损失函数包括两部分:一是策略网络的强化学习损失,二是变分分布的KL散度损失。KL散度损失用于鼓励变分分布接近一个先验分布,从而实现稀疏性。网络结构方面,可以使用图神经网络(GNN)来进行消息传递和策略计算。关键参数包括变分分布的参数、GNN的层数和隐藏层大小,以及强化学习算法的学习率等。
🖼️ 关键图片
📊 实验亮点
BayesG在具有多达167个智能体的大规模交通控制任务中,显著优于现有的MARL基线方法。实验结果表明,BayesG能够学习到更有效的交互结构,从而提高整体性能和可扩展性。具体性能数据在论文中有详细展示,证明了其在复杂环境下的优越性。
🎯 应用场景
该研究成果可应用于大规模交通控制、机器人协作、传感器网络等领域。通过学习动态交互结构,智能体能够更好地适应复杂环境,提高协作效率和系统性能。未来,该方法有望推广到更广泛的分布式决策问题中,例如智能电网、社交网络等。
📄 摘要(原文)
In networked multi-agent reinforcement learning (Networked-MARL), decentralized agents must act under local observability and constrained communication over fixed physical graphs. Existing methods often assume static neighborhoods, limiting adaptability to dynamic or heterogeneous environments. While centralized frameworks can learn dynamic graphs, their reliance on global state access and centralized infrastructure is impractical in real-world decentralized systems. We propose a stochastic graph-based policy for Networked-MARL, where each agent conditions its decision on a sampled subgraph over its local physical neighborhood. Building on this formulation, we introduce BayesG, a decentralized actor-framework that learns sparse, context-aware interaction structures via Bayesian variational inference. Each agent operates over an ego-graph and samples a latent communication mask to guide message passing and policy computation. The variational distribution is trained end-to-end alongside the policy using an evidence lower bound (ELBO) objective, enabling agents to jointly learn both interaction topology and decision-making strategies. BayesG outperforms strong MARL baselines on large-scale traffic control tasks with up to 167 agents, demonstrating superior scalability, efficiency, and performance.