SCAN: Self-Denoising Monte Carlo Annotation for Robust Process Reward Learning
作者: Yuyang Ding, Xinyu Shi, Juntao Li, Xiaobo Liang, Zhaopeng Tu, Min Zhang
分类: cs.LG, cs.CL
发布日期: 2025-09-20 (更新: 2025-10-14)
备注: NeurIPS 2025. Project page: https://scan-prm.github.io/
💡 一句话要点
提出SCAN自降噪蒙特卡洛标注方法,用于稳健的过程奖励学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 蒙特卡洛方法 自降噪 弱监督学习 容错学习
📋 核心要点
- 人工标注过程奖励模型数据成本高、可扩展性差,而蒙特卡洛估计的合成数据噪声大,易过拟合。
- 提出SCAN框架,通过自降噪策略生成高质量合成数据,并采用容错学习方法训练稳健的PRM。
- 实验表明,SCAN仅用少量合成数据就能超越大规模人工标注数据集训练的模型,且推理成本更低。
📝 摘要(中文)
过程奖励模型(PRM)能够提供细粒度的、步骤级别的评估,从而促进大型语言模型(LLM)中更深层次的推理过程,并在数学推理等复杂任务中表现出有效性。然而,由于人工标注数据的高成本和有限的可扩展性,开发PRM具有挑战性。来自蒙特卡洛(MC)估计的合成数据是一种有前途的替代方案,但其噪声比率较高,可能导致过拟合并阻碍大规模训练。本文对来自MC估计的合成数据中的噪声分布进行了初步研究,发现标注模型由于其标注能力的限制,倾向于低估和高估步骤的正确性。基于这些见解,我们提出了一种高效的数据合成和容错学习框架——自降噪蒙特卡洛标注(SCAN)。实验结果表明,即使是轻量级模型(例如,15亿参数)也可以通过自降噪策略生成高质量的标注,使PRM能够以仅为原始MC估计6%的推理成本实现卓越的性能。通过我们稳健的学习策略,PRM可以有效地从这种弱监督中学习,在ProcessBench中实现了39.2 F1值的提升(从19.9到59.1)。尽管仅使用紧凑的合成数据集,我们的模型超越了强大的基线,包括那些在大型人工标注数据集(如PRM800K)上训练的模型。此外,随着我们扩大合成数据的规模,性能持续提高,突出了SCAN在可扩展、经济高效且稳健的PRM训练方面的潜力。
🔬 方法详解
问题定义:过程奖励模型(PRM)依赖于高质量的标注数据,但人工标注成本高昂且难以扩展。使用蒙特卡洛(MC)方法生成的合成数据虽然可以降低成本,但包含大量噪声,导致模型训练不稳定,容易过拟合,最终影响PRM的性能。现有方法难以在成本和数据质量之间取得平衡。
核心思路:论文的核心思路是通过自降噪策略来提高合成数据的质量,并设计容错学习方法来增强模型对噪声数据的鲁棒性。通过让模型自身参与到数据标注的降噪过程中,可以更有效地识别和纠正错误标注,从而提高合成数据的质量。同时,容错学习方法可以使模型在存在噪声的情况下,依然能够学习到有效的知识。
技术框架:SCAN框架主要包含两个阶段:数据合成和模型训练。在数据合成阶段,首先使用一个轻量级模型进行初步的蒙特卡洛标注,然后利用自降噪策略对标注结果进行修正,生成高质量的合成数据。在模型训练阶段,使用容错学习方法,利用合成数据训练PRM。
关键创新:SCAN的关键创新在于提出了自降噪的蒙特卡洛标注方法。传统的蒙特卡洛标注方法直接使用模型进行标注,容易受到模型自身偏差的影响,导致标注结果包含大量噪声。SCAN通过让模型自身参与到数据标注的降噪过程中,可以更有效地识别和纠正错误标注,从而提高合成数据的质量。
关键设计:自降噪策略的具体实现方式是,使用多个轻量级模型进行蒙特卡洛标注,然后通过投票或加权平均的方式对标注结果进行融合。容错学习方法可以使用各种鲁棒的损失函数,例如Huber Loss或Rank Loss,以减少噪声数据对模型训练的影响。论文中具体使用的参数设置和网络结构未明确给出,属于未知信息。
🖼️ 关键图片


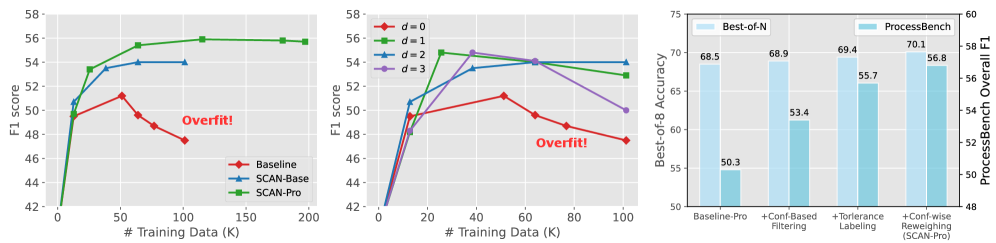
📊 实验亮点
SCAN在ProcessBench数据集上实现了显著的性能提升,F1值从19.9提高到59.1,提升幅度高达39.2。即使使用紧凑的合成数据集,SCAN也超越了在大型人工标注数据集(如PRM800K)上训练的强大基线。此外,随着合成数据规模的扩大,SCAN的性能持续提升,验证了其可扩展性。
🎯 应用场景
SCAN方法可应用于各种需要过程奖励模型的场景,例如数学推理、代码生成、策略游戏等。通过降低数据标注成本和提高模型训练的鲁棒性,SCAN可以促进PRM在更广泛领域的应用,并提升LLM在复杂任务中的表现。
📄 摘要(原文)
Process reward models (PRMs) offer fine-grained, step-level evaluations that facilitate deeper reasoning processes in large language models (LLMs), proving effective in complex tasks like mathematical reasoning. However, developing PRMs is challenging due to the high cost and limited scalability of human-annotated data. Synthetic data from Monte Carlo (MC) estimation is a promising alternative but suffers from a high noise ratio, which can cause overfitting and hinder large-scale training. In this work, we conduct a preliminary study on the noise distribution in synthetic data from MC estimation, identifying that annotation models tend to both underestimate and overestimate step correctness due to limitations in their annotation capabilities. Building on these insights, we propose Self-Denoising Monte Carlo Annotation (SCAN), an efficient data synthesis and noise-tolerant learning framework. Our key findings indicate that: (1) Even lightweight models (e.g., 1.5B parameters) can produce high-quality annotations through a self-denoising strategy, enabling PRMs to achieve superior performance with only 6% the inference cost required by vanilla MC estimation. (2) With our robust learning strategy, PRMs can effectively learn from this weak supervision, achieving a 39.2 F1 score improvement (from 19.9 to 59.1) in ProcessBench. Despite using only a compact synthetic dataset, our models surpass strong baselines, including those trained on large-scale human-annotated datasets such as PRM800K. Furthermore, performance continues to improve as we scale up the synthetic data, highlighting the potential of SCAN for scalable, cost-efficient, and robust PRM training.