Federated Learning with Ad-hoc Adapter Insertions: The Case of Soft-Embeddings for Training Classifier-as-Retriever
作者: Marijan Fofonjka, Shahryar Zehtabi, Alireza Behtash, Tyler Mauer, David Stout
分类: cs.LG
发布日期: 2025-09-20
备注: 22 pages, 7 figures, 3 tables
💡 一句话要点
提出一种基于联邦学习和Ad-hoc适配器插入的检索增强生成方法,用于资源受限的边缘设备。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 适配器网络 检索增强生成 边缘计算 分类器检索 差分隐私 小型语言模型
📋 核心要点
- 现有检索增强生成模型(RAG)应用于新领域时,需要更新大型语言模型,计算和内存开销巨大,边缘设备难以承受。
- 该论文提出一种新颖的编码器架构,通过在小型语言模型中插入适配器网络,学习增强的soft embeddings,降低计算需求。
- 通过联邦学习和差分隐私,实现在边缘设备上对soft embeddings和分类器检索器的在线微调,并进行了理论分析和实验验证。
📝 摘要(中文)
本文提出了一种新颖的编码器架构,旨在解决现有检索增强生成(RAG)解决方案在应用于新知识领域时,需要更新预训练大型语言模型(LLM)的问题。该架构使用一个满足边缘设备内存约束的冻结小型语言模型(SLM),并在SLM的Transformer块之前插入一个小型适配器网络。该可训练适配器获取新语料库的token embeddings,并学习生成增强的soft embeddings,与完全微调相比,更新所需的计算能力显著降低。此外,本文还提出了一种新的检索机制,通过将分类器头连接到SLM编码器,训练该分类器学习输入embeddings与其对应文档之间的相似性映射。最后,为了实现在边缘设备上在线微调(i)编码器soft embeddings和(ii)分类器作为检索器,本文采用联邦学习(FL)和差分隐私(DP),以实现高效、保护隐私且产品级的训练解决方案。本文对该方法进行了理论分析,在一般平滑非凸损失函数下,建立了梯度方差较小情况下的收敛保证。通过大量的数值实验,证明了(i)获得soft embeddings以增强编码器的有效性,(ii)训练分类器以改进检索器,以及(iii)联邦学习在加速方面的作用。
🔬 方法详解
问题定义:现有检索增强生成(RAG)系统在面对新的知识领域时,需要对预训练的大型语言模型(LLM)进行微调,这带来了巨大的计算和内存开销,使得在资源受限的边缘设备上部署变得不可行。现有方法要么无法适应新领域,要么需要高昂的计算成本。
核心思路:本文的核心思路是利用小型语言模型(SLM)满足边缘设备的资源限制,并通过插入适配器网络来增强SLM的表示能力。适配器网络学习将新语料库的token embeddings转换为增强的soft embeddings,从而使SLM能够更好地理解和检索新领域的知识。同时,采用联邦学习和差分隐私,保证了数据隐私和训练效率。
技术框架:整体框架包含以下几个主要模块:1) 冻结的小型语言模型(SLM):作为基础编码器,保持不变以节省计算资源。2) 适配器网络:插入到SLM的Transformer块之前,学习生成增强的soft embeddings。3) 分类器头:连接到SLM编码器,用于学习输入embeddings与其对应文档之间的相似性映射,实现分类器作为检索器。4) 联邦学习(FL):用于在多个边缘设备上协同训练适配器网络和分类器头,同时保护数据隐私。5) 差分隐私(DP):进一步增强数据隐私保护。
关键创新:该论文的关键创新在于:1) 提出了一种基于适配器插入的轻量级编码器架构,能够在资源受限的边缘设备上进行高效的知识迁移。2) 提出了一种新的检索机制,通过训练分类器来学习输入embeddings与文档之间的相似性映射,提高了检索的准确性。3) 结合联邦学习和差分隐私,实现了在保护数据隐私的前提下,对编码器和检索器进行在线微调。
关键设计:适配器网络的设计是关键。它通常是一个小型的前馈神经网络,插入到SLM的每个Transformer块之前。损失函数包括分类损失(用于训练分类器头)和可能的正则化项。联邦学习采用标准的FedAvg算法,并结合差分隐私机制,例如添加高斯噪声到梯度或参数更新中。具体的参数设置(如适配器网络的大小、学习率、噪声水平等)需要根据具体任务进行调整。
🖼️ 关键图片


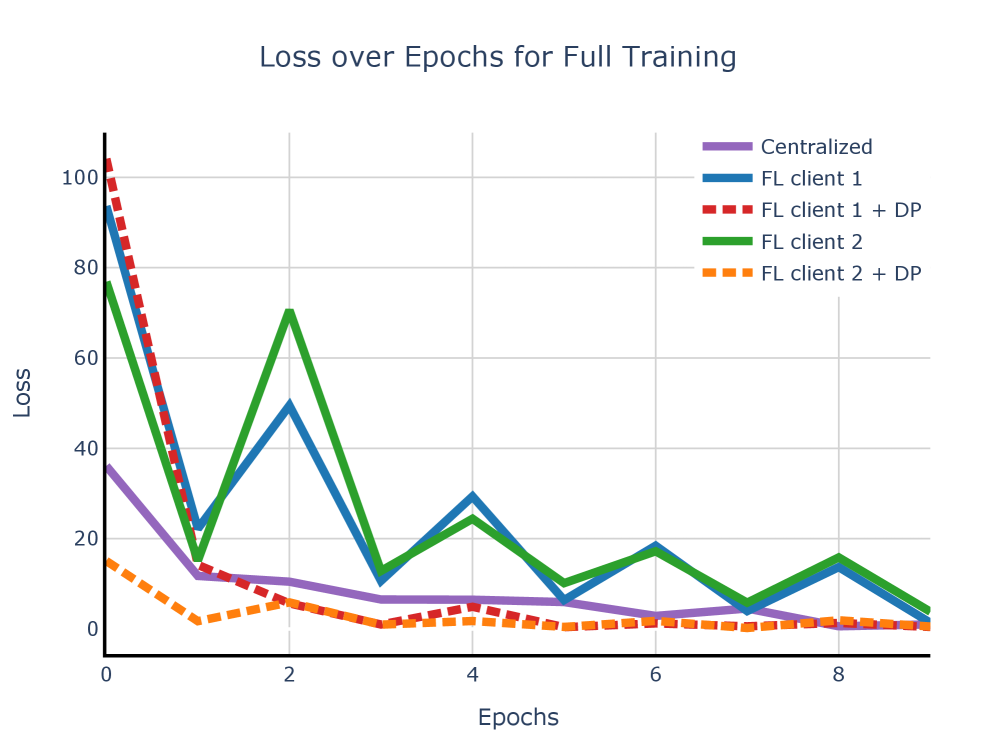
📊 实验亮点
实验结果表明,通过插入适配器网络和训练分类器,可以有效提高检索的准确性。同时,联邦学习能够加速模型训练,并在保护数据隐私的前提下,实现与中心化训练相近的性能。具体的性能提升数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要知识快速适应和资源受限的场景,例如:边缘计算环境下的智能问答系统、移动设备上的本地知识检索、以及需要保护用户隐私的个性化推荐系统。该方法能够降低模型更新的成本,并提高边缘设备的智能化水平,具有广阔的应用前景。
📄 摘要(原文)
When existing retrieval-augmented generation (RAG) solutions are intended to be used for new knowledge domains, it is necessary to update their encoders, which are taken to be pretrained large language models (LLMs). However, fully finetuning these large models is compute- and memory-intensive, and even infeasible when deployed on resource-constrained edge devices. We propose a novel encoder architecture in this work that addresses this limitation by using a frozen small language model (SLM), which satisfies the memory constraints of edge devices, and inserting a small adapter network before the transformer blocks of the SLM. The trainable adapter takes the token embeddings of the new corpus and learns to produce enhanced soft embeddings for it, while requiring significantly less compute power to update than full fine-tuning. We further propose a novel retrieval mechanism by attaching a classifier head to the SLM encoder, which is trained to learn a similarity mapping of the input embeddings to their corresponding documents. Finally, to enable the online fine-tuning of both (i) the encoder soft embeddings and (ii) the classifier-as-retriever on edge devices, we adopt federated learning (FL) and differential privacy (DP) to achieve an efficient, privacy-preserving, and product-grade training solution. We conduct a theoretical analysis of our methodology, establishing convergence guarantees under mild assumptions on gradient variance when deployed for general smooth nonconvex loss functions. Through extensive numerical experiments, we demonstrate (i) the efficacy of obtaining soft embeddings to enhance the encoder, (ii) training a classifier to improve the retriever, and (iii) the role of FL in achieving speedup.