MatchFixAgent: Language-Agnostic Autonomous Repository-Level Code Translation Validation and Repair
作者: Ali Reza Ibrahimzada, Brandon Paulsen, Reyhaneh Jabbarvand, Joey Dodds, Daniel Kroening
分类: cs.SE, cs.LG
发布日期: 2025-09-19 (更新: 2025-12-18)
💡 一句话要点
提出MatchFixAgent,实现语言无关的仓库级代码翻译验证与修复
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码翻译 等价性验证 代码修复 大型语言模型 多智能体系统
📋 核心要点
- 现有代码翻译验证与修复方法工程开销大,且依赖不充分的测试集,导致验证不准确和修复效果差。
- MatchFixAgent采用多智能体架构,将等价性验证分解为子任务,利用LLM进行语义分析、测试生成和错误修复。
- 实验表明,MatchFixAgent在验证准确性和修复能力上均优于现有方法,且具有更好的语言无关性。
📝 摘要(中文)
代码翻译是将源代码从一种编程语言(PL)转换为另一种编程语言。验证翻译的功能等价性以及必要时进行修复是代码翻译中的关键步骤。现有的自动化验证和修复方法难以推广到多种编程语言,因为工程开销高,并且它们依赖于现有且通常不足的测试套件,这导致了错误的等价性声明和无效的翻译修复。我们开发了MatchFixAgent,这是一个基于大型语言模型(LLM)的、与编程语言无关的框架,用于翻译的等价性验证和修复。MatchFixAgent具有多智能体架构,该架构将等价性验证划分为几个子任务,以确保对翻译进行彻底和一致的语义分析。然后,它将此分析反馈给测试智能体以编写和执行测试。在观察到测试失败后,修复智能体尝试修复翻译错误。最终的(非)等价性决策由裁决智能体做出,该智能体考虑了语义分析和测试执行结果。
🔬 方法详解
问题定义:代码翻译旨在将代码从一种编程语言转换成另一种编程语言,但如何保证翻译后的代码与原始代码在功能上等价是一个关键问题。现有的自动化验证和修复方法通常依赖于特定编程语言的工具和技术,难以推广到多种编程语言。此外,这些方法往往依赖于已有的测试用例,而这些测试用例可能覆盖不全面,导致验证结果不准确,修复效果不佳。
核心思路:MatchFixAgent的核心思路是利用大型语言模型(LLM)的强大语义理解和生成能力,构建一个与编程语言无关的自动化验证和修复框架。通过将验证过程分解为多个子任务,并由不同的智能体协同完成,可以更全面、更准确地分析翻译后的代码,并生成有效的测试用例来检测潜在的错误。当检测到错误时,修复智能体可以利用LLM的生成能力自动修复翻译后的代码。
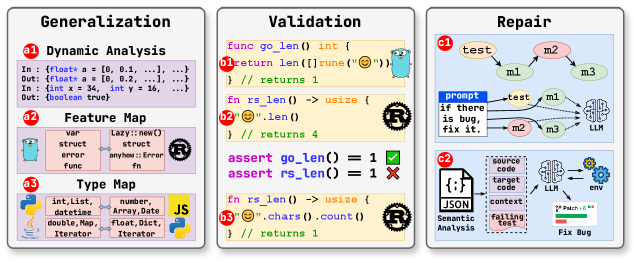
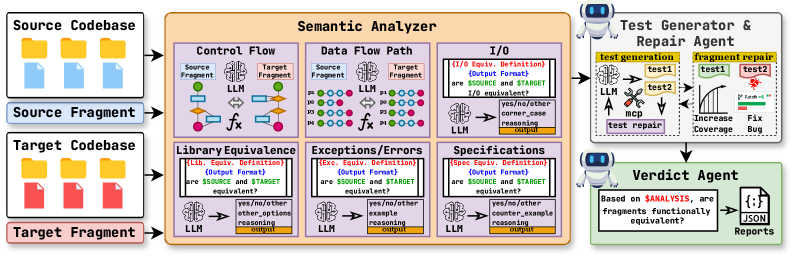
技术框架:MatchFixAgent采用多智能体架构,主要包含以下几个模块:语义分析智能体、测试智能体、修复智能体和裁决智能体。语义分析智能体负责分析原始代码和翻译后代码的语义信息,提取关键特征。测试智能体根据语义分析结果生成测试用例,并执行这些测试用例来检测翻译后的代码是否存在错误。修复智能体在检测到错误时,尝试修改翻译后的代码以修复错误。裁决智能体综合考虑语义分析结果和测试执行结果,最终判断翻译后的代码是否与原始代码等价。
关键创新:MatchFixAgent最重要的技术创新点在于其与编程语言无关的设计。通过利用LLM的通用语义理解和生成能力,MatchFixAgent可以处理多种编程语言的代码翻译验证和修复任务,而无需针对每种编程语言进行专门的开发和配置。此外,MatchFixAgent的多智能体架构可以更全面、更准确地分析翻译后的代码,并生成更有效的测试用例,从而提高验证的准确性和修复的效果。
关键设计:MatchFixAgent的关键设计包括:(1) 如何利用LLM提取代码的语义特征;(2) 如何根据语义特征生成有效的测试用例;(3) 如何利用LLM修改代码以修复错误;(4) 如何综合考虑语义分析结果和测试执行结果做出最终的等价性判断。论文中可能涉及prompt的设计,以及各个agent之间的协作方式等细节。
🖼️ 关键图片

📊 实验亮点
MatchFixAgent在包含6种编程语言对的2219个翻译对上进行了评估。实验结果表明,MatchFixAgent能够对99.2%的翻译对给出(非)等价性判断,与先前工作相比,在72.8%的翻译对上结果一致。在结果不一致的情况下,MatchFixAgent的判断有60.7%是正确的。此外,MatchFixAgent能够修复50.6%的非等价翻译,而先前工作仅能修复18.5%。
🎯 应用场景
MatchFixAgent可应用于各种代码翻译场景,例如遗留系统迁移、跨平台应用开发和代码库现代化。它能够自动化验证和修复翻译后的代码,降低人工成本,提高翻译质量,加速软件开发过程。该研究的未来影响在于推动代码翻译技术的进步,促进不同编程语言之间的互操作性。
📄 摘要(原文)
Code translation transforms source code from one programming language (PL) to another. Validating the functional equivalence of translation and repairing, if necessary, are critical steps in code translation. Existing automated validation and repair approaches struggle to generalize to many PLs due to high engineering overhead, and they rely on existing and often inadequate test suites, which results in false claims of equivalence and ineffective translation repair. We develop MatchFixAgent, a large language model (LLM)-based, PL-agnostic framework for equivalence validation and repair of translations. MatchFixAgent features a multi-agent architecture that divides equivalence validation into several sub-tasks to ensure thorough and consistent semantic analysis of the translation. Then it feeds this analysis to test agent to write and execute tests. Upon observing a test failure, the repair agent attempts to fix the translation bug. The final (in)equivalence decision is made by the verdict agent, considering semantic analyses and test execution results. We compare MatchFixAgent's validation and repair results with four repository-level code translation techniques. We use 2,219 translation pairs from their artifacts, which cover 6 PL pairs, and are collected from 24 GitHub projects totaling over 900K lines of code. Our results demonstrate that MatchFixAgent produces (in)equivalence verdicts for 99.2% of translation pairs, with the same equivalence validation result as prior work on 72.8% of them. When MatchFixAgent's result disagrees with prior work, we find that 60.7% of the time MatchFixAgent's result is actually correct. In addition, we show that MatchFixAgent can repair 50.6% of inequivalent translation, compared to prior work's 18.5%. This demonstrates that MatchFixAgent is far more adaptable to many PL pairs than prior work, while producing highly accurate validation results.