DiffusionNFT: Online Diffusion Reinforcement with Forward Process
作者: Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, Ming-Yu Liu
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-09-19
💡 一句话要点
提出DiffusionNFT,通过前向过程进行在线扩散强化学习,提升生成质量和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 强化学习 在线学习 流匹配 图像生成
📋 核心要点
- 现有扩散模型在线强化学习方法依赖逆向过程,存在求解器限制和正向-逆向不一致等问题。
- DiffusionNFT通过流匹配在前向过程中直接优化扩散模型,避免了似然估计和逆向采样。
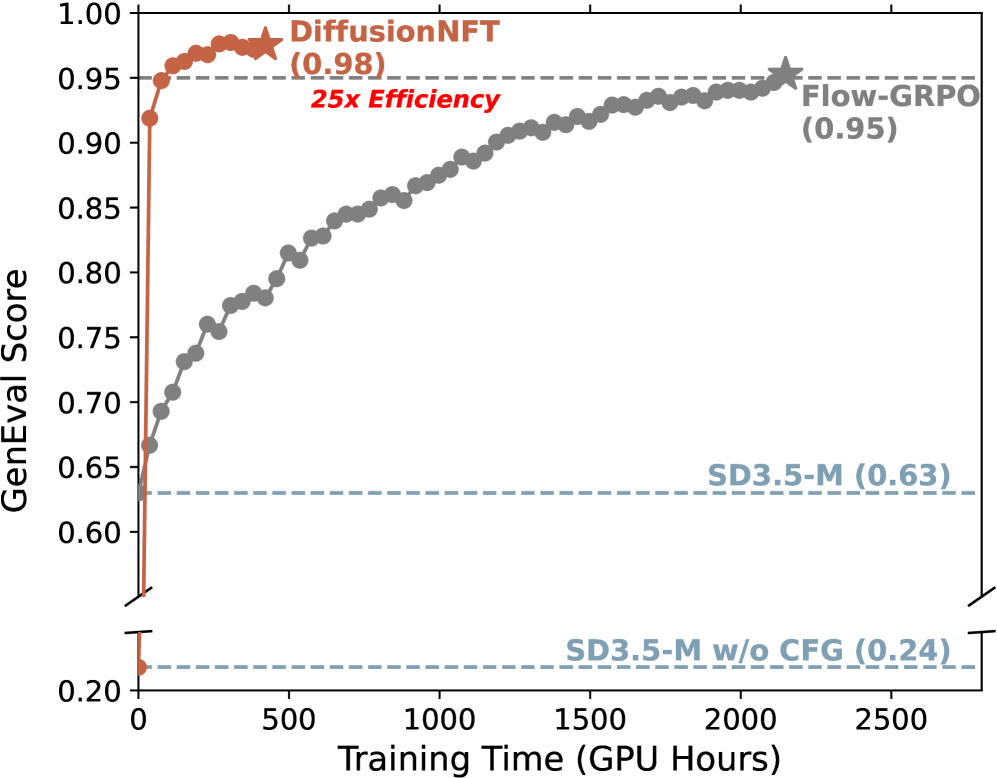
- 实验表明,DiffusionNFT比现有方法效率更高,且无需无分类器指导即可达到更好的性能。
📝 摘要(中文)
在线强化学习在后训练语言模型中至关重要,但由于难以处理的似然性,将其扩展到扩散模型仍然具有挑战性。现有工作离散化逆向采样过程以实现GRPO式训练,但继承了求解器限制、正向-逆向不一致以及与无分类器指导(CFG)集成复杂等根本缺陷。我们引入了Diffusion Negative-aware FineTuning (DiffusionNFT),这是一种新的在线强化学习范式,通过流匹配直接在前向过程中优化扩散模型。DiffusionNFT对比正向和负向生成来定义一个隐式的策略改进方向,自然地将强化信号融入到监督学习目标中。这种公式允许使用任意黑盒求解器进行训练,消除了对似然估计的需求,并且只需要干净的图像而不是采样轨迹来进行策略优化。在直接比较中,DiffusionNFT比FlowGRPO效率高出25倍,并且无需CFG。例如,DiffusionNFT在1k步内将GenEval分数从0.24提高到0.98,而FlowGRPO在超过5k步并采用额外的CFG时达到0.95。通过利用多个奖励模型,DiffusionNFT显著提高了SD3.5-Medium在每个测试基准上的性能。
🔬 方法详解
问题定义:论文旨在解决扩散模型在线强化学习中,由于逆向过程的复杂性导致的训练困难问题。现有方法如FlowGRPO依赖于离散化逆向采样过程,存在求解器限制、正向-逆向不一致以及与无分类器指导(CFG)集成复杂等问题,限制了其效率和性能。
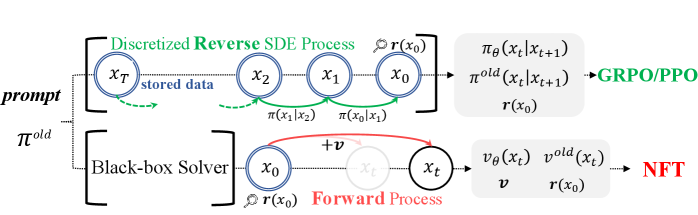
核心思路:DiffusionNFT的核心思路是通过流匹配直接在前向过程中优化扩散模型。它将强化学习信号融入到监督学习目标中,通过对比正向和负向生成来定义一个隐式的策略改进方向。这种方法避免了对逆向过程的依赖,从而消除了对似然估计的需求,并允许使用任意黑盒求解器进行训练。
技术框架:DiffusionNFT的整体框架包括以下几个主要步骤:1) 使用扩散模型生成图像;2) 使用奖励模型评估生成的图像;3) 根据奖励信号,通过流匹配在前向过程中优化扩散模型。关键在于定义一个损失函数,该函数能够根据奖励信号调整扩散模型的参数,使得模型倾向于生成更高奖励的图像。
关键创新:DiffusionNFT最重要的技术创新点在于它直接在前向过程中进行强化学习,而不是像现有方法那样依赖于逆向过程。这种方法避免了对似然估计的需求,并且可以与任意黑盒求解器一起使用。此外,DiffusionNFT通过对比正向和负向生成来定义策略改进方向,从而自然地将强化信号融入到监督学习目标中。
关键设计:DiffusionNFT的关键设计包括:1) 使用流匹配来定义前向过程的优化目标;2) 设计一个对比损失函数,该函数能够根据奖励信号区分正向和负向生成;3) 利用多个奖励模型来提高性能。具体的损失函数形式和网络结构细节在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片

📊 实验亮点
DiffusionNFT在实验中表现出显著的性能提升。例如,在GenEval指标上,DiffusionNFT在1k步内将分数从0.24提高到0.98,而FlowGRPO需要超过5k步并使用额外的CFG才能达到0.95。此外,DiffusionNFT还显著提高了SD3.5-Medium在各个测试基准上的性能,证明了其有效性。
🎯 应用场景
DiffusionNFT可应用于图像生成、文本生成等领域,通过强化学习提升生成内容质量和用户满意度。例如,可以用于个性化图像生成、创意内容生成、以及AI艺术创作等场景,具有广泛的应用前景和商业价值。
📄 摘要(原文)
Online reinforcement learning (RL) has been central to post-training language models, but its extension to diffusion models remains challenging due to intractable likelihoods. Recent works discretize the reverse sampling process to enable GRPO-style training, yet they inherit fundamental drawbacks, including solver restrictions, forward-reverse inconsistency, and complicated integration with classifier-free guidance (CFG). We introduce Diffusion Negative-aware FineTuning (DiffusionNFT), a new online RL paradigm that optimizes diffusion models directly on the forward process via flow matching. DiffusionNFT contrasts positive and negative generations to define an implicit policy improvement direction, naturally incorporating reinforcement signals into the supervised learning objective. This formulation enables training with arbitrary black-box solvers, eliminates the need for likelihood estimation, and requires only clean images rather than sampling trajectories for policy optimization. DiffusionNFT is up to $25\times$ more efficient than FlowGRPO in head-to-head comparisons, while being CFG-free. For instance, DiffusionNFT improves the GenEval score from 0.24 to 0.98 within 1k steps, while FlowGRPO achieves 0.95 with over 5k steps and additional CFG employment. By leveraging multiple reward models, DiffusionNFT significantly boosts the performance of SD3.5-Medium in every benchmark tested.