Quantum Reinforcement Learning with Dynamic-Circuit Qubit Reuse and Grover-Based Trajectory Optimization
作者: Thet Htar Su, Shaswot Shresthamali, Masaaki Kondo
分类: quant-ph, cs.LG
发布日期: 2025-09-19
💡 一句话要点
提出一种基于动态电路量子比特复用和Grover搜索的量子强化学习框架。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子强化学习 动态电路 量子比特复用 Grover搜索 量子马尔可夫决策过程
📋 核心要点
- 传统强化学习在处理大规模状态空间时面临维度灾难,量子强化学习旨在利用量子计算的优势解决此问题。
- 该论文提出了一种完全量子化的强化学习框架,利用量子叠加和Grover搜索加速策略优化,并采用动态电路技术减少量子比特需求。
- 实验结果表明,该框架在降低量子比特需求的同时保持了轨迹保真度,并在实际量子硬件上验证了其可行性。
📝 摘要(中文)
本文提出了一个完整的量子强化学习框架,该框架集成了量子马尔可夫决策过程、基于动态电路的量子比特复用和基于Grover算法的轨迹优化。该框架将状态、动作、奖励和转移完全编码在量子域中,通过叠加实现状态-动作序列的并行探索,并消除了经典子程序。动态电路操作(包括中间电路测量和重置)允许在多个智能体-环境交互中重复使用相同的物理量子比特,从而将量子比特需求从7*T减少到7(对于T个时间步),同时保持逻辑连续性。量子算术计算轨迹回报,并应用Grover搜索到这些评估轨迹的叠加态,以放大测量具有最高回报的轨迹的概率,从而加速识别最优策略。仿真表明,基于动态电路的实现保持了轨迹保真度,同时相对于静态设计减少了66%的量子比特使用量。在IBM Heron类量子硬件上的实验部署证实,该框架在当前量子处理器的约束范围内运行,并验证了在噪声中等规模量子条件下完全量子多步强化学习的可行性。该框架提高了量子强化学习在大型顺序决策任务中的可扩展性和实际应用。
🔬 方法详解
问题定义:传统的量子强化学习方法通常需要大量的量子比特来存储状态和动作信息,这限制了其在实际量子硬件上的应用。此外,经典强化学习算法在处理大规模状态空间时存在维度灾难问题。因此,如何降低量子比特需求,并充分利用量子计算的优势来加速强化学习过程是一个关键挑战。
核心思路:该论文的核心思路是利用动态电路技术实现量子比特的复用,从而显著减少量子比特的需求量。同时,利用Grover搜索算法加速最优轨迹的搜索过程。通过将状态、动作、奖励和转移完全编码在量子域中,实现端到端的量子强化学习,避免了经典子程序的瓶颈。
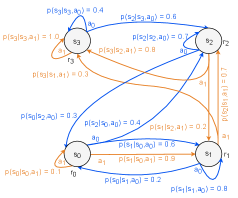
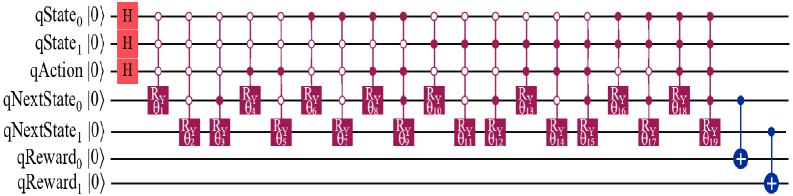
技术框架:该框架包含以下主要模块:1) 量子马尔可夫决策过程(QMDP):将状态、动作、奖励和转移概率编码为量子态和量子算符。2) 动态电路量子比特复用:通过中间电路测量和重置操作,在不同的时间步重复使用相同的物理量子比特。3) 量子算术:使用量子电路计算轨迹的回报值。4) Grover搜索:在所有轨迹的叠加态上应用Grover搜索,以放大具有最高回报的轨迹的概率。
关键创新:该论文最重要的技术创新点在于动态电路量子比特复用技术。传统的量子算法通常需要为每个量子比特分配一个物理量子比特,而该技术允许在不同的时间步重复使用相同的物理量子比特,从而显著降低了量子比特的需求量。这使得在当前的噪声中等规模量子(NISQ)设备上实现更复杂的量子强化学习算法成为可能。
关键设计:动态电路的设计是关键。通过在每个时间步结束时测量量子比特的状态,并根据测量结果重置量子比特,可以在下一个时间步重复使用这些量子比特。此外,Grover搜索的迭代次数需要根据轨迹的数量进行调整,以保证能够以较高的概率找到最优轨迹。论文中具体参数设置和量子电路的细节未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
仿真结果表明,基于动态电路的实现相对于静态设计减少了66%的量子比特使用量,同时保持了轨迹保真度。在IBM Heron类量子硬件上的实验部署验证了该框架在实际量子硬件上的可行性,并证实了在噪声中等规模量子条件下进行完全量子多步强化学习的可能性。具体的性能数据和对比基线未在摘要中详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要进行序列决策的领域,例如机器人控制、资源调度、金融交易和游戏AI。通过利用量子计算的优势,可以加速策略学习过程,并找到更优的策略。尤其是在状态空间巨大的复杂环境中,量子强化学习有望超越经典强化学习算法的性能。
📄 摘要(原文)
A fully quantum reinforcement learning framework is developed that integrates a quantum Markov decision process, dynamic circuit-based qubit reuse, and Grover's algorithm for trajectory optimization. The framework encodes states, actions, rewards, and transitions entirely within the quantum domain, enabling parallel exploration of state-action sequences through superposition and eliminating classical subroutines. Dynamic circuit operations, including mid-circuit measurement and reset, allow reuse of the same physical qubits across multiple agent-environment interactions, reducing qubit requirements from 7*T to 7 for T time steps while preserving logical continuity. Quantum arithmetic computes trajectory returns, and Grover's search is applied to the superposition of these evaluated trajectories to amplify the probability of measuring those with the highest return, thereby accelerating the identification of the optimal policy. Simulations demonstrate that the dynamic-circuit-based implementation preserves trajectory fidelity while reducing qubit usage by 66 percent relative to the static design. Experimental deployment on IBM Heron-class quantum hardware confirms that the framework operates within the constraints of current quantum processors and validates the feasibility of fully quantum multi-step reinforcement learning under noisy intermediate-scale quantum conditions. This framework advances the scalability and practical application of quantum reinforcement learning for large-scale sequential decision-making tasks.