RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
作者: Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, Zixiao Huang, Mingjie Wei, Yuqing Xie, Ke Yang, Bo Dai, Zhexuan Xu, Jiakun Du, Xiangyuan Wang, Xu Fu, Letong Shi, Zhihao Liu, Kang Chen, Weilin Liu, Gang Liu, Boxun Li, Jianlei Yang, Zhi Yang, Guohao Dai, Yu Wang
分类: cs.LG, cs.AI, cs.DC
发布日期: 2025-09-19 (更新: 2025-12-29)
备注: GitHub Repo: https://github.com/RLinf/RLinf
💡 一句话要点
RLinf:通过宏微观流转换实现灵活高效的大规模强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 大规模训练 系统优化 宏微观流转换 M2Flow 弹性流水线 自适应通信
📋 核心要点
- 现有强化学习系统难以兼顾灵活性和效率,导致硬件利用率低,训练速度慢。
- RLinf提出宏微观流转换(M2Flow)范式,自动分解和重组RL工作流程,优化执行效率。
- 实验表明,RLinf在推理和具身强化学习任务上,端到端训练吞吐量提升1.07-2.43倍。
📝 摘要(中文)
强化学习在推动通用人工智能、智能体智能和具身智能方面展现出巨大潜力。然而,强化学习工作流程固有的异构性和动态性通常导致现有系统上的硬件利用率低和训练速度慢。本文提出了RLinf,一个高性能的强化学习训练系统,其核心在于系统灵活性。为了最大化灵活性和效率,RLinf基于一种名为宏微观流转换(M2Flow)的新型强化学习系统设计范式构建,该范式在时间和空间维度上自动分解高级、易于组合的强化学习工作流程,并将它们重组为优化的执行流。在RLinf工作器的自适应通信能力的支持下,我们设计了上下文切换和弹性流水线来实现M2Flow转换,并采用剖析引导的调度策略来生成最优执行计划。在推理强化学习和具身强化学习任务上的大量评估表明,RLinf始终优于最先进的系统,在端到端训练吞吐量方面实现了1.07倍-2.43倍的加速。
🔬 方法详解
问题定义:现有强化学习系统在处理大规模、异构和动态的工作负载时,面临灵活性和效率之间的权衡问题。传统系统要么为了灵活性而牺牲效率,要么为了效率而限制了灵活性,无法充分利用硬件资源,导致训练速度缓慢。
核心思路:RLinf的核心思路是通过宏微观流转换(M2Flow)范式,将高级、易于组合的强化学习工作流程分解为更细粒度的任务,并根据硬件资源和任务依赖关系,将这些细粒度任务重新组合成优化的执行流。这种方法旨在在灵活性和效率之间取得平衡,从而提高硬件利用率和训练速度。
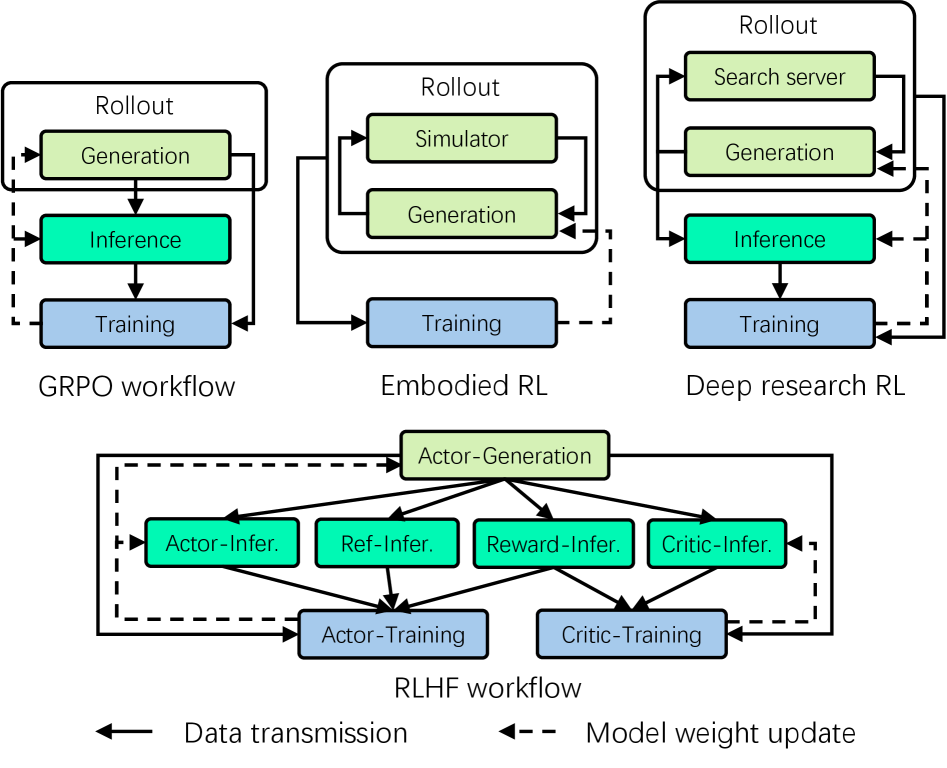
技术框架:RLinf的整体架构包含以下主要模块:1) 工作流程分解器:将高级RL工作流程分解为细粒度的任务。2) 任务调度器:根据任务依赖关系和硬件资源,生成优化的执行计划。3) 工作器节点:执行细粒度任务,并支持自适应通信和上下文切换。4) 弹性流水线:允许任务在不同的工作器节点之间流动,从而实现动态资源分配。
关键创新:RLinf的关键创新在于M2Flow范式,它允许系统在时间和空间维度上自动分解和重组RL工作流程。与传统的静态执行计划相比,M2Flow能够根据实际情况动态调整执行策略,从而更好地适应异构和动态的工作负载。此外,RLinf还引入了自适应通信和上下文切换机制,进一步提高了系统的灵活性和效率。
关键设计:RLinf的关键设计包括:1) 剖析引导的调度策略:通过对任务执行过程进行剖析,获取任务的资源需求和依赖关系,从而生成最优的执行计划。2) 自适应通信机制:根据任务之间的数据依赖关系,动态调整通信策略,减少通信开销。3) 弹性流水线:允许任务在不同的工作器节点之间流动,从而实现动态资源分配和负载均衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RLinf在推理强化学习和具身强化学习任务上均优于现有系统。具体而言,RLinf在端到端训练吞吐量方面实现了1.07倍-2.43倍的加速。这些结果表明,RLinf的M2Flow范式能够有效地提高强化学习的训练效率。
🎯 应用场景
RLinf具有广泛的应用前景,可用于加速各种强化学习任务的训练,包括游戏AI、机器人控制、自动驾驶、推荐系统等。通过提高训练效率和硬件利用率,RLinf可以降低强化学习的开发成本,并促进其在更多领域的应用。此外,RLinf的M2Flow范式也可以推广到其他类型的大规模计算任务中。
📄 摘要(原文)
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving $1.07\times-2.43\times$ speedup in end-to-end training throughput.