Foundation Models as World Models: A Foundational Study in Text-Based GridWorlds
作者: Remo Sasso, Michelangelo Conserva, Dominik Jeurissen, Paulo Rauber
分类: cs.LG, cs.AI
发布日期: 2025-09-19
备注: 20 pages, 9 figures. Accepted for presentation at the 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Workshop on Embodied World Models for Decision Making
💡 一句话要点
提出基于Foundation Model的世界模型与智能体,提升文本网格世界中的强化学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Foundation Model 世界模型 强化学习 文本网格世界 样本效率
📋 核心要点
- 现有强化学习方法在高效模拟器中表现出色,但在真实世界应用中,由于交互成本高昂,样本效率成为瓶颈。
- 本文提出利用Foundation Model的先验知识和推理能力,分别构建Foundation World Model和Foundation Agent,以提高强化学习的样本效率。
- 实验表明,LLM的改进能提升FWM和FA的性能,FA在简单环境中表现优异,FWM与强化学习智能体的结合在复杂环境中潜力巨大。
📝 摘要(中文)
本文研究了如何将预训练的Foundation Model(FM)集成到强化学习框架中,以提高样本效率。针对交互成本高的现实世界应用,本文提出了两种策略:一是利用FM的先验知识构建Foundation World Model(FWM),通过模拟交互训练和评估智能体;二是利用FM的推理能力构建Foundation Agent(FA)进行决策。在文本网格世界环境中,实验结果表明,LLM的改进可以转化为更好的FWM和FA。基于当前LLM的FA可以为足够简单的环境提供优秀的策略。FWM与强化学习智能体的结合在具有部分可观测性和随机性的复杂环境中具有很大的潜力。
🔬 方法详解
问题定义:现有强化学习方法在解决序列决策问题时,需要大量的样本进行训练,尤其是在真实世界环境中,与环境的交互成本非常高昂。因此,如何提高强化学习的样本效率是一个重要的挑战。现有方法难以有效利用预训练模型中的知识,导致需要从头开始学习,效率低下。
核心思路:本文的核心思路是利用Foundation Model (FM) 强大的先验知识和推理能力,将其融入到强化学习框架中。具体来说,本文探索了两种方法:一是将FM作为世界模型,用于模拟环境,从而降低与真实环境交互的成本;二是将FM作为智能体,直接利用其推理能力进行决策。
技术框架:本文的技术框架包含两个主要部分:Foundation World Model (FWM) 和 Foundation Agent (FA)。FWM利用FM学习环境的动态模型,然后使用该模型生成模拟环境,用于训练强化学习智能体。FA则直接利用FM的推理能力,根据当前状态和目标,生成行动策略。整个流程包括:1) 使用文本描述环境;2) FWM学习环境动态;3) 使用FWM进行强化学习训练;或者 1) 使用文本描述环境;2) FA根据环境描述和当前状态生成动作。
关键创新:本文的关键创新在于将Foundation Model引入到强化学习框架中,并探索了两种不同的集成方式:作为世界模型和作为智能体。这种方法能够有效地利用FM的先验知识和推理能力,从而提高强化学习的样本效率。此外,本文还提出了在文本网格世界环境中评估这些方法的方案,为后续研究提供了基准。
关键设计:在FWM中,关键在于如何有效地利用FM学习环境的动态模型。这可能涉及到设计合适的prompt,以及使用合适的损失函数来训练FM。在FA中,关键在于如何将环境状态和目标有效地编码为文本,并输入到FM中,以及如何将FM的输出解码为可执行的动作。具体的参数设置、损失函数、网络结构等细节取决于所使用的具体FM。
🖼️ 关键图片

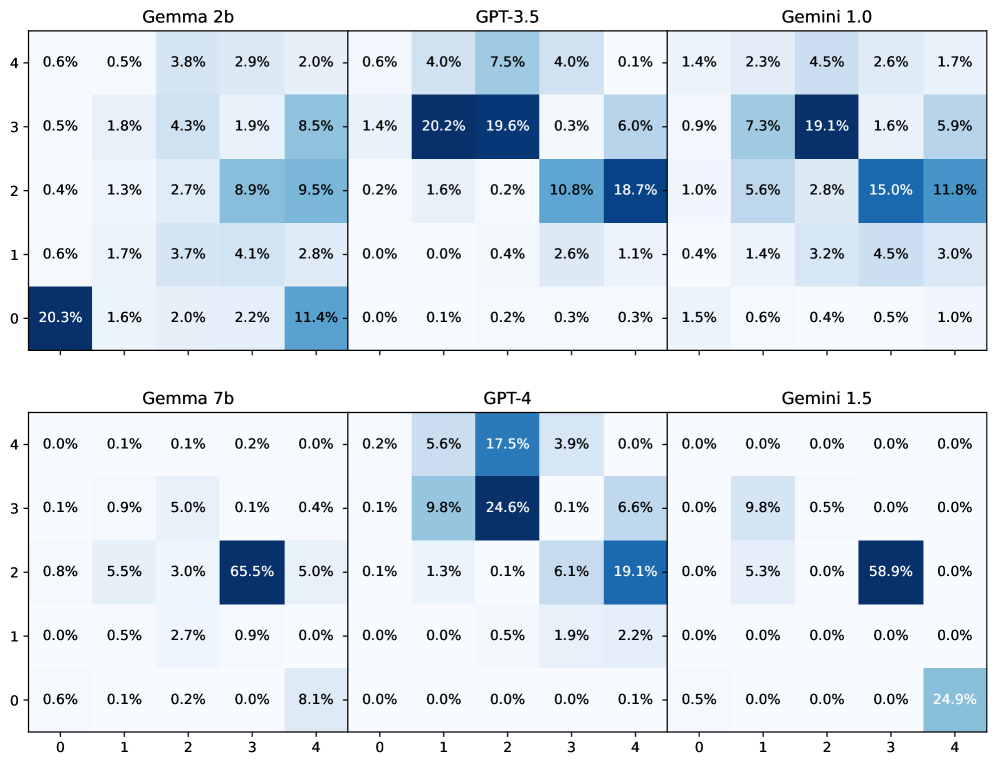

📊 实验亮点
实验结果表明,随着LLM的改进,FWM和FA的性能也随之提升。在足够简单的环境中,基于当前LLM的FA已经可以提供优秀的策略。此外,FWM与强化学习智能体的结合在具有部分可观测性和随机性的复杂环境中表现出巨大的潜力,预示着未来研究方向。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域。通过利用预训练模型的知识,可以降低训练成本,提高智能体的泛化能力。未来,可以将该方法扩展到更复杂的环境和任务中,例如,在真实机器人平台上进行实验,或者在更复杂的模拟环境中进行训练。
📄 摘要(原文)
While reinforcement learning from scratch has shown impressive results in solving sequential decision-making tasks with efficient simulators, real-world applications with expensive interactions require more sample-efficient agents. Foundation models (FMs) are natural candidates to improve sample efficiency as they possess broad knowledge and reasoning capabilities, but it is yet unclear how to effectively integrate them into the reinforcement learning framework. In this paper, we anticipate and, most importantly, evaluate two promising strategies. First, we consider the use of foundation world models (FWMs) that exploit the prior knowledge of FMs to enable training and evaluating agents with simulated interactions. Second, we consider the use of foundation agents (FAs) that exploit the reasoning capabilities of FMs for decision-making. We evaluate both approaches empirically in a family of grid-world environments that are suitable for the current generation of large language models (LLMs). Our results suggest that improvements in LLMs already translate into better FWMs and FAs; that FAs based on current LLMs can already provide excellent policies for sufficiently simple environments; and that the coupling of FWMs and reinforcement learning agents is highly promising for more complex settings with partial observability and stochastic elements.