Optimizing Product Deduplication in E-Commerce with Multimodal Embeddings
作者: Aysenur Kulunk, Berk Taskin, M. Furkan Eseoglu, H. Bahadir Sahin
分类: cs.IR, cs.LG
发布日期: 2025-09-19 (更新: 2025-12-01)
备注: 8 pages, accepted to 2025 IEEE International Conference on Big Data, Industrial and Goverment Track
💡 一句话要点
提出一种基于多模态嵌入的电商产品去重方法,提升大规模商品识别精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商产品去重 多模态嵌入 BERT模型 Masked Autoencoders 向量数据库 相似性搜索 领域特定模型
📋 核心要点
- 传统电商产品去重方法依赖关键词匹配,忽略了产品标题的语义相似性,导致准确率低。
- 该方法结合BERT文本模型和Masked Autoencoders图像模型,提取多模态特征,并使用降维技术压缩嵌入。
- 实验表明,该方法在超过2亿件商品的数据集上,F1值达到0.90,优于第三方解决方案。
📝 摘要(中文)
本文提出了一种可扩展的多模态产品去重方法,专为电商领域设计,旨在解决重复商品列表导致的用户困扰和运营效率低下问题。该方法结合了基于BERT架构的领域特定文本模型和用于图像表示的Masked Autoencoders。两种架构都通过降维技术生成紧凑的128维嵌入,同时保持信息完整性。此外,还开发了一种新颖的决策模型,利用文本和图像向量。通过将这些特征提取机制与优化的向量数据库Milvus集成,该系统能够高效、高精度地在大规模产品目录(超过2亿件商品)中进行相似性搜索,且仅消耗100GB系统内存。实验结果表明,该匹配系统实现了0.90的宏平均F1分数,优于第三方解决方案的0.83。
🔬 方法详解
问题定义:电商平台存在大量重复商品列表,导致用户体验下降,运营成本增加。传统方法依赖于关键词匹配,无法有效识别语义相似但描述不同的商品,造成去重效果不佳。现有方法难以在大规模商品库上实现高效、准确的去重。
核心思路:利用多模态信息(文本和图像)进行产品表示,捕捉产品标题的语义信息和图像的视觉特征。通过学习领域相关的嵌入,提高相似产品的区分度。使用向量数据库加速相似性搜索,实现高效去重。
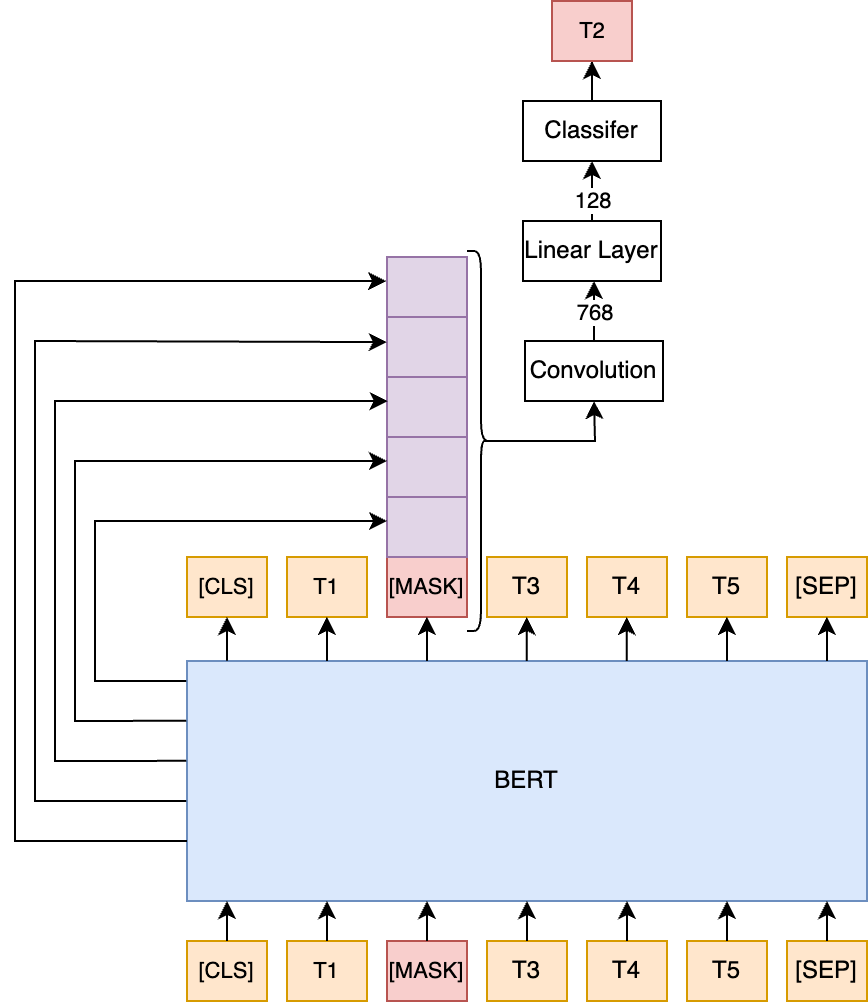
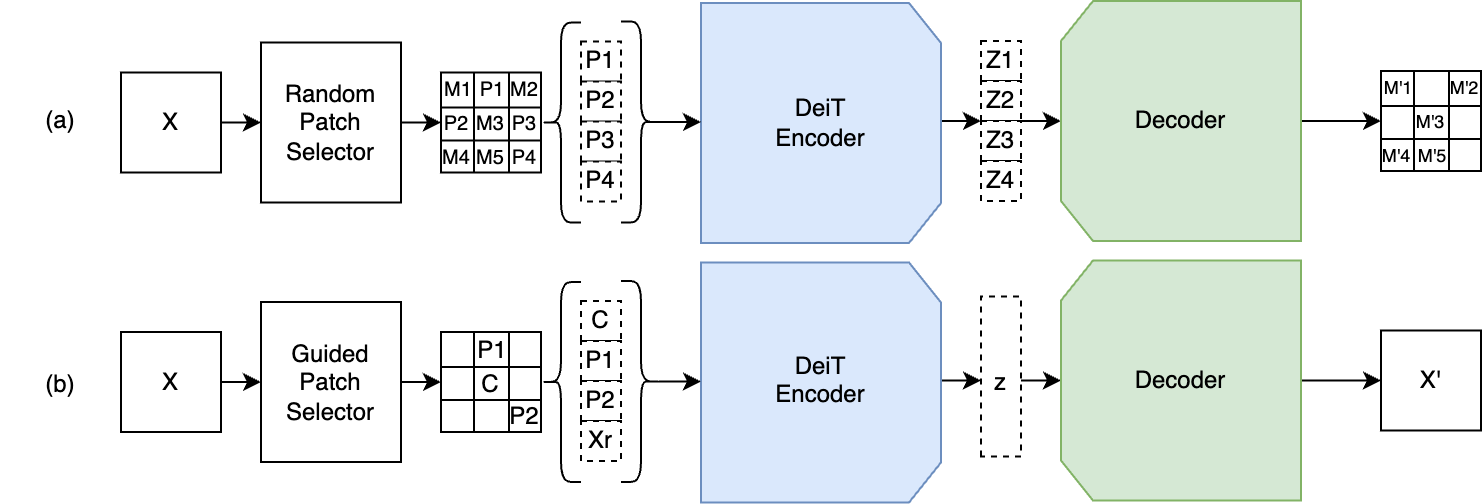
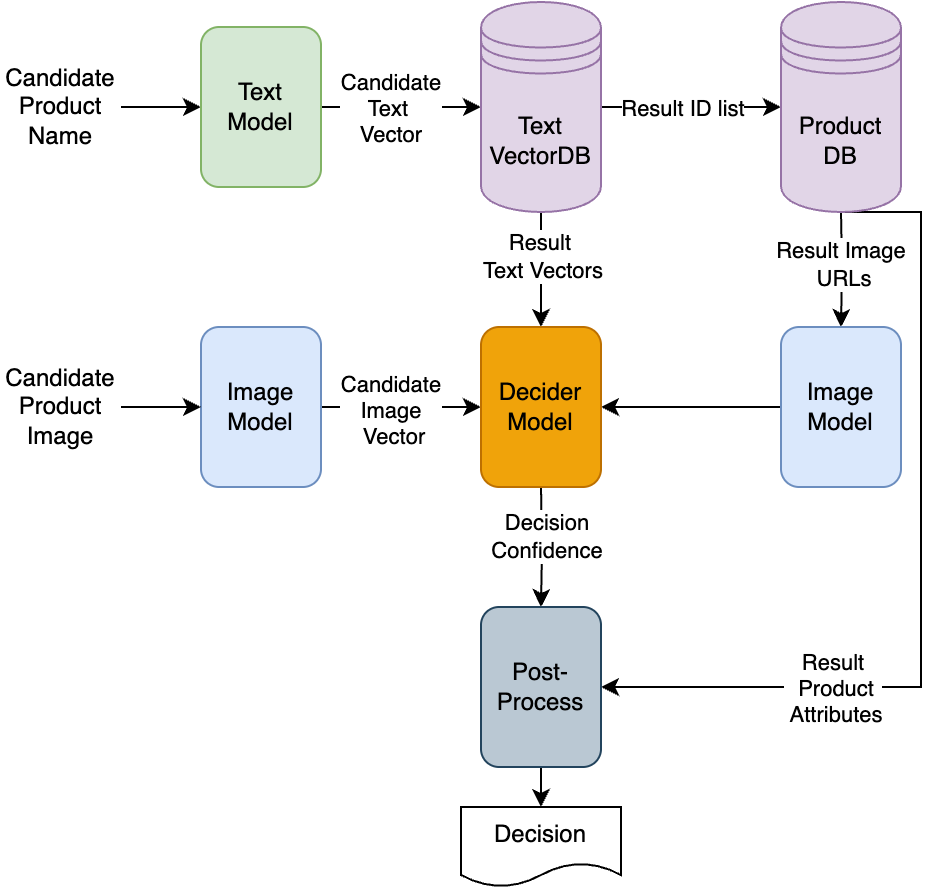
技术框架:该系统包含以下几个主要模块:1) 文本特征提取模块:使用基于BERT的领域特定文本模型提取产品标题的文本嵌入。2) 图像特征提取模块:使用Masked Autoencoders提取产品图像的视觉嵌入。3) 降维模块:对文本和图像嵌入进行降维,生成128维的紧凑向量。4) 决策模型:结合文本和图像向量,判断两个产品是否重复。5) 向量数据库:使用Milvus存储产品嵌入,加速相似性搜索。
关键创新:1) 结合文本和图像信息进行产品去重,充分利用了多模态数据。2) 使用领域特定的BERT模型,更好地捕捉电商产品的语义信息。3) 提出了一种新颖的决策模型,有效融合文本和图像特征。4) 利用向量数据库Milvus,实现了大规模商品的高效相似性搜索。
关键设计:1) 使用BERT模型进行文本特征提取,并在电商领域数据上进行预训练或微调,以适应领域特性。2) 使用Masked Autoencoders进行图像特征提取,学习图像的鲁棒表示。3) 使用降维技术(如PCA或Autoencoder)将嵌入维度降低到128维,减少计算量和存储空间。4) 决策模型可以使用简单的距离度量(如余弦相似度)或更复杂的机器学习模型(如分类器)来判断产品是否重复。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在超过2亿件商品的数据集上实现了0.90的宏平均F1分数,显著优于第三方解决方案的0.83。该系统仅消耗100GB系统内存,表明其具有良好的可扩展性和资源利用率。这些结果验证了该方法在实际电商环境中的有效性。
🎯 应用场景
该研究成果可应用于大规模电商平台的产品去重,提升用户体验,降低运营成本。此外,该方法也可扩展到其他领域,如搜索引擎、推荐系统等,用于识别相似或重复的内容。未来,可以探索更先进的多模态融合技术,进一步提高去重精度和效率。
📄 摘要(原文)
In large scale e-commerce marketplaces, duplicate product listings frequently cause consumer confusion and operational inefficiencies, degrading trust on the platform and increasing costs. Traditional keyword-based search methodologies falter in accurately identifying duplicates due to their reliance on exact textual matches, neglecting semantic similarities inherent in product titles. To address these challenges, we introduce a scalable, multimodal product deduplication designed specifically for the e-commerce domain. Our approach employs a domain-specific text model grounded in BERT architecture in conjunction with MaskedAutoEncoders for image representations. Both of these architectures are augmented with dimensionality reduction techniques to produce compact 128-dimensional embeddings without significant information loss. Complementing this, we also developed a novel decider model that leverages both text and image vectors. By integrating these feature extraction mechanisms with Milvus, an optimized vector database, our system can facilitate efficient and high-precision similarity searches across extensive product catalogs exceeding 200 million items with just 100GB of system RAM consumption. Empirical evaluations demonstrate that our matching system achieves a macro-average F1 score of 0.90, outperforming third-party solutions which attain an F1 score of 0.83. Our findings show the potential of combining domain-specific adaptations with state-of-the-art machine learning techniques to mitigate duplicate listings in large-scale e-commerce environments.