On Optimal Steering to Achieve Exact Fairness
作者: Mohit Sharma, Amit Jayant Deshpande, Chiranjib Bhattacharyya, Rajiv Ratn Shah
分类: cs.LG, cs.AI
发布日期: 2025-09-19 (更新: 2025-10-24)
备注: Accepted for Presentation at Neurips 2025
💡 一句话要点
提出基于KL散度的最优特征分布引导方法,实现精确公平性并提升模型效用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 公平机器学习 分布引导 KL散度 理想分布 大型语言模型 偏差缓解 群体公平性
📋 核心要点
- 现有公平生成模型和表示引导方法缺乏对模型输出的可证明公平性保证,存在公平性与效用的权衡。
- 论文核心思想是寻找与理想分布最接近的分布,该理想分布能保证任何代价敏感风险最小化器的精确群体公平结果。
- 实验结果表明,该方法在合成和真实数据集上均能提升公平性,同时保持甚至提升模型效用。
📝 摘要(中文)
为了解决公平机器学习中“偏差输入,偏差输出”的问题,本文提出将数据或大型语言模型(LLM)的内部表示的特征分布引导至理想分布,以保证群体公平的结果。理想分布是指在该分布上,任何代价敏感风险的最小化器都能保证精确的群体公平结果(例如,人口统计均等、机会均等),即不存在公平性与效用之间的权衡。本文构建了一个优化程序,通过寻找KL散度下最接近的理想分布来实现最优引导,并为底层分布来自已知参数族(例如,正态分布、对数正态分布)的情况提供了高效算法。在合成和真实数据集上的实验表明,本文的最优引导技术在不降低效用的情况下提高了公平性(有时甚至提高了效用)。本文还展示了LLM表示的仿射引导,以减少多类分类中的偏差,例如,在Bios数据集中从简短传记预测职业。此外,本文引导LLM的内部表示朝着期望的输出,使其在不同群体中表现同样出色。
🔬 方法详解
问题定义:现有公平机器学习方法存在“偏差输入,偏差输出”的问题,即如果输入数据本身存在偏差,那么训练出来的模型也会存在偏差。现有的公平生成模型和表示引导方法虽然可以缓解这个问题,但是缺乏对模型输出的可证明公平性保证,并且往往需要在公平性和效用之间进行权衡。
核心思路:论文的核心思路是找到一个“理想分布”,在这个分布上训练的模型,无论使用什么样的代价敏感风险函数,都能保证精确的群体公平性。然后,通过优化方法,将原始数据或模型内部表示的分布引导到这个理想分布附近。这样,就可以在保证公平性的同时,尽可能地保留原始数据的有用信息。
技术框架:整体框架可以分为以下几个步骤:1. 定义理想分布:根据具体的公平性指标(如人口统计均等、机会均等),定义理想分布的数学形式。2. 构建优化程序:构建一个优化程序,目标是找到与原始分布在KL散度下最接近的理想分布。3. 设计高效算法:针对特定的分布族(如正态分布、对数正态分布),设计高效的优化算法。4. 应用于LLM:将该方法应用于LLM的内部表示,通过仿射变换等方式引导表示分布,从而减少偏差。
关键创新:论文的关键创新在于提出了“理想分布”的概念,并证明了在理想分布上训练的模型可以保证精确的群体公平性。此外,论文还针对常见的分布族,设计了高效的优化算法,使得该方法可以在实际应用中得到有效应用。与现有方法相比,该方法不再需要在公平性和效用之间进行权衡,而是可以同时提升公平性和效用。
关键设计:论文的关键设计包括:1. 理想分布的定义:根据不同的公平性指标,需要设计不同的理想分布。例如,对于人口统计均等,理想分布可以是每个群体的样本比例相同。2. KL散度的使用:KL散度用于衡量原始分布和理想分布之间的距离,选择KL散度是因为它具有良好的数学性质,并且可以方便地进行优化。3. 优化算法的设计:针对不同的分布族,需要设计不同的优化算法。例如,对于正态分布,可以使用梯度下降法进行优化。
🖼️ 关键图片
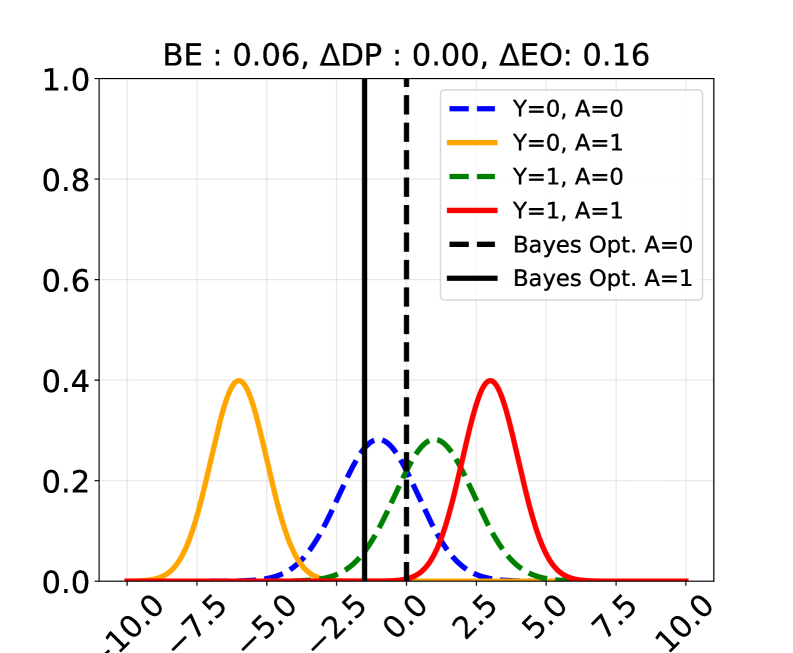
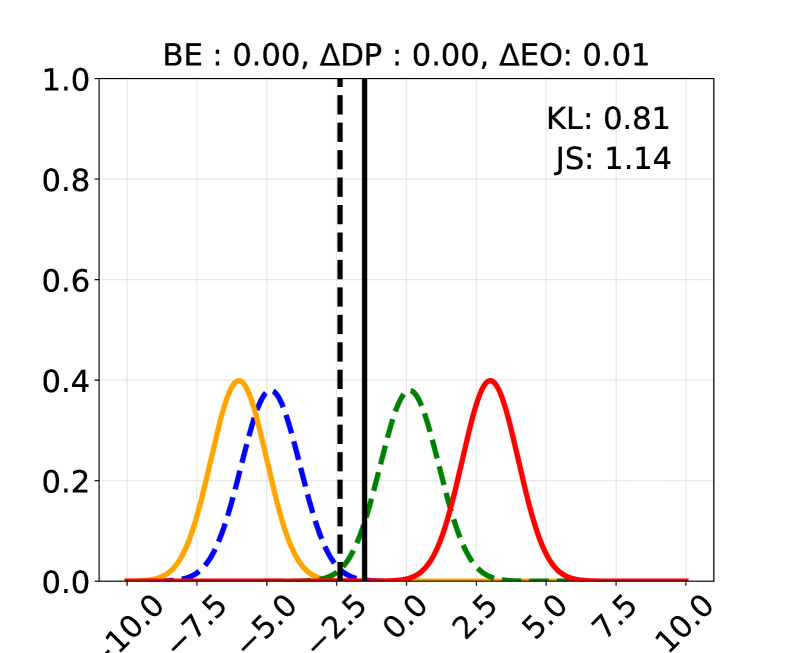
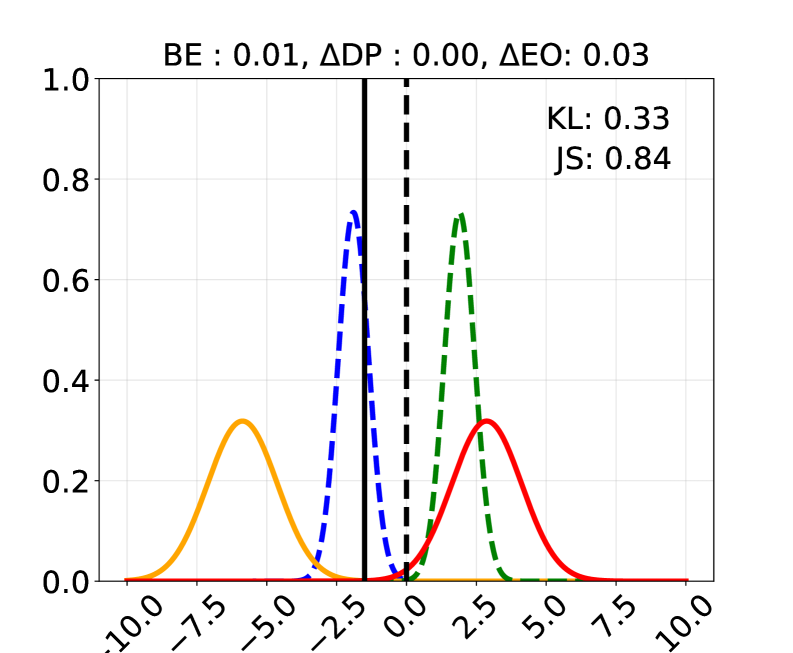
📊 实验亮点
实验结果表明,该方法在合成和真实数据集上均能有效提升公平性,同时保持甚至提升模型效用。例如,在Bios数据集上,通过仿射引导LLM表示,可以显著减少职业预测中的偏差。此外,该方法还可以应用于LLM的内部表示,使其在不同群体中表现同样出色,进一步验证了该方法的有效性和泛化能力。
🎯 应用场景
该研究成果可广泛应用于各种需要公平性的机器学习场景,例如信用评分、招聘、教育资源分配等。通过引导数据或模型表示的分布,可以减少算法偏差,提高决策的公平性,从而避免对特定群体造成歧视。此外,该方法还可以应用于大型语言模型,减少其在生成文本、对话等任务中的偏见,提升用户体验。
📄 摘要(原文)
To fix the 'bias in, bias out' problem in fair machine learning, it is important to steer feature distributions of data or internal representations of Large Language Models (LLMs) to ideal ones that guarantee group-fair outcomes. Previous work on fair generative models and representation steering could greatly benefit from provable fairness guarantees on the model output. We define a distribution as ideal if the minimizer of any cost-sensitive risk on it is guaranteed to have exact group-fair outcomes (e.g., demographic parity, equal opportunity)-in other words, it has no fairness-utility trade-off. We formulate an optimization program for optimal steering by finding the nearest ideal distribution in KL-divergence, and provide efficient algorithms for it when the underlying distributions come from well-known parametric families (e.g., normal, log-normal). Empirically, our optimal steering techniques on both synthetic and real-world datasets improve fairness without diminishing utility (and sometimes even improve utility). We demonstrate affine steering of LLM representations to reduce bias in multi-class classification, e.g., occupation prediction from a short biography in Bios dataset (De-Arteaga et al.). Furthermore, we steer internal representations of LLMs towards desired outputs so that it works equally well across different groups.