Information Geometry of Variational Bayes
作者: Mohammad Emtiyaz Khan
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-09-19
💡 一句话要点
揭示信息几何与变分贝叶斯的联系,利用自然梯度优化大规模语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 变分贝叶斯 信息几何 自然梯度 贝叶斯学习规则 大规模语言模型
📋 核心要点
- 变分贝叶斯(VB)方法在求解复杂贝叶斯推断问题时面临计算挑战,尤其是在高维参数空间中。
- 论文核心思想是揭示VB与信息几何的内在联系,强调VB求解过程本质上需要自然梯度的估计或计算。
- 通过贝叶斯学习规则(BLR)算法,简化贝叶斯规则,并实现大规模语言模型的VB算法。
📝 摘要(中文)
本文强调了信息几何与变分贝叶斯(VB)之间的一个根本联系,并讨论了其对机器学习的影响。在特定条件下,VB解总是需要估计或计算自然梯度。我们通过使用Khan和Rue (2023)提出的名为贝叶斯学习规则(BLR)的自然梯度下降算法,展示了这一事实的几个结果。这些结果包括(i)将贝叶斯规则简化为自然梯度的加法,(ii)推广了基于梯度的算法中使用的二次代理函数,以及(iii)大规模语言模型的VB算法的大规模实现。这种联系及其结果都不是全新的,但我们进一步强调了信息几何和贝叶斯这两个领域的共同起源,希望促进这两个领域交叉的更多工作。
🔬 方法详解
问题定义:变分贝叶斯(VB)旨在通过寻找近似后验分布来简化贝叶斯推断,但其在高维参数空间中的计算复杂度是一个主要瓶颈。现有的VB方法在处理大规模数据集和复杂模型时,往往面临计算效率低下的问题,需要更有效的优化策略。
核心思路:论文的核心思路是揭示信息几何与VB之间的深刻联系,指出VB的求解过程本质上与自然梯度的计算密切相关。通过利用信息几何的理论,可以更有效地进行VB优化,并简化相关的计算过程。这种联系为设计更高效的VB算法提供了新的视角。
技术框架:论文主要基于Khan和Rue提出的贝叶斯学习规则(BLR)算法,该算法是一种自然梯度下降算法。整体框架包括:1) 建立VB与信息几何的联系,证明VB求解需要自然梯度;2) 利用BLR算法进行自然梯度下降,简化贝叶斯规则;3) 将BLR算法应用于大规模语言模型的VB算法实现。
关键创新:论文的关键创新在于强调了信息几何与VB的内在联系,并利用自然梯度下降算法(BLR)来优化VB。这种方法不仅简化了贝叶斯规则,还推广了梯度方法中使用的二次代理函数,为大规模VB算法的实现提供了可能。
关键设计:论文的关键设计包括:1) 使用自然梯度代替传统梯度进行优化,利用Fisher信息矩阵来调整梯度方向;2) 将贝叶斯规则简化为自然梯度的加法形式,降低计算复杂度;3) 针对大规模语言模型,设计高效的VB算法实现,充分利用BLR算法的优势。
🖼️ 关键图片

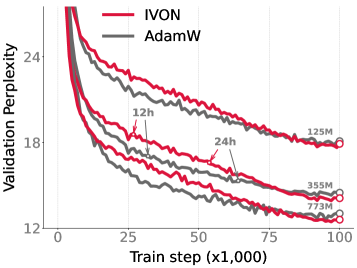
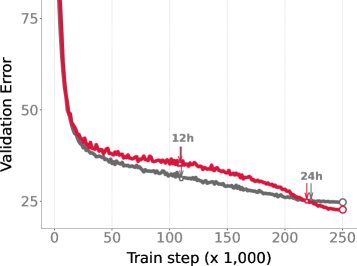
📊 实验亮点
论文通过贝叶斯学习规则(BLR)算法,简化了贝叶斯规则的计算,并成功应用于大规模语言模型的变分贝叶斯算法实现。虽然论文没有提供具体的性能数据,但强调了该方法在大规模模型上的应用潜力,为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于大规模机器学习模型的贝叶斯推断,例如大型语言模型、深度神经网络等。通过更高效的变分贝叶斯方法,可以提升模型训练速度、降低计算成本,并提高模型的泛化能力。未来,该方法有望在自然语言处理、计算机视觉等领域得到广泛应用。
📄 摘要(原文)
We highlight a fundamental connection between information geometry and variational Bayes (VB) and discuss its consequences for machine learning. Under certain conditions, a VB solution always requires estimation or computation of natural gradients. We show several consequences of this fact by using the natural-gradient descent algorithm of Khan and Rue (2023) called the Bayesian Learning Rule (BLR). These include (i) a simplification of Bayes' rule as addition of natural gradients, (ii) a generalization of quadratic surrogates used in gradient-based methods, and (iii) a large-scale implementation of VB algorithms for large language models. Neither the connection nor its consequences are new but we further emphasize the common origins of the two fields of information geometry and Bayes with a hope to facilitate more work at the intersection of the two fields.