Predicting Language Models' Success at Zero-Shot Probabilistic Prediction
作者: Kevin Ren, Santiago Cortes-Gomez, Carlos Miguel Patiño, Ananya Joshi, Ruiqi Lyu, Jingjing Tang, Alistair Turcan, Khurram Yamin, Steven Wu, Bryan Wilder
分类: cs.LG
发布日期: 2025-09-18
备注: EMNLP Findings 2025. We release our code at: https://github.com/kkr36/llm-eval/tree/camera-ready
💡 一句话要点
研究LLM在零样本概率预测中的性能,并提出无标签指标预测LLM在特定任务上的表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 零样本学习 概率预测 表格数据 性能预测
📋 核心要点
- 现有方法缺乏对LLM在零样本预测任务中性能的可靠评估,导致用户难以判断LLM是否适用于特定任务。
- 论文提出了一系列无需标注数据的指标,用于预测LLM在特定预测任务上的表现,从而帮助用户选择合适的LLM应用场景。
- 实验表明,所提出的指标能够有效预测LLM在各种表格预测任务中的性能,为LLM的应用提供了指导。
📝 摘要(中文)
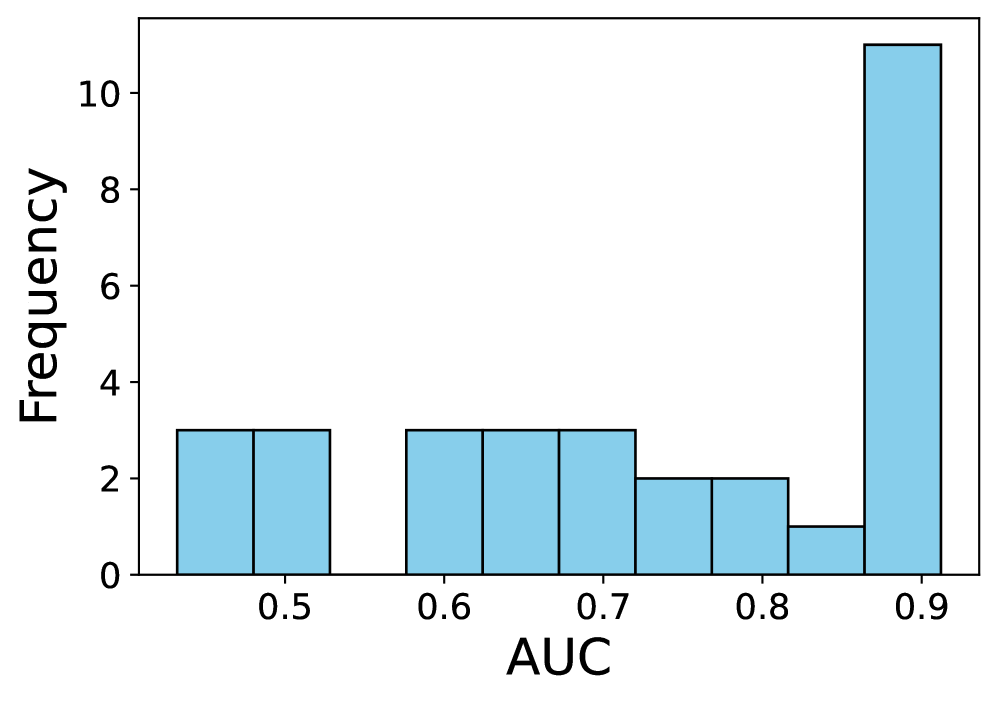
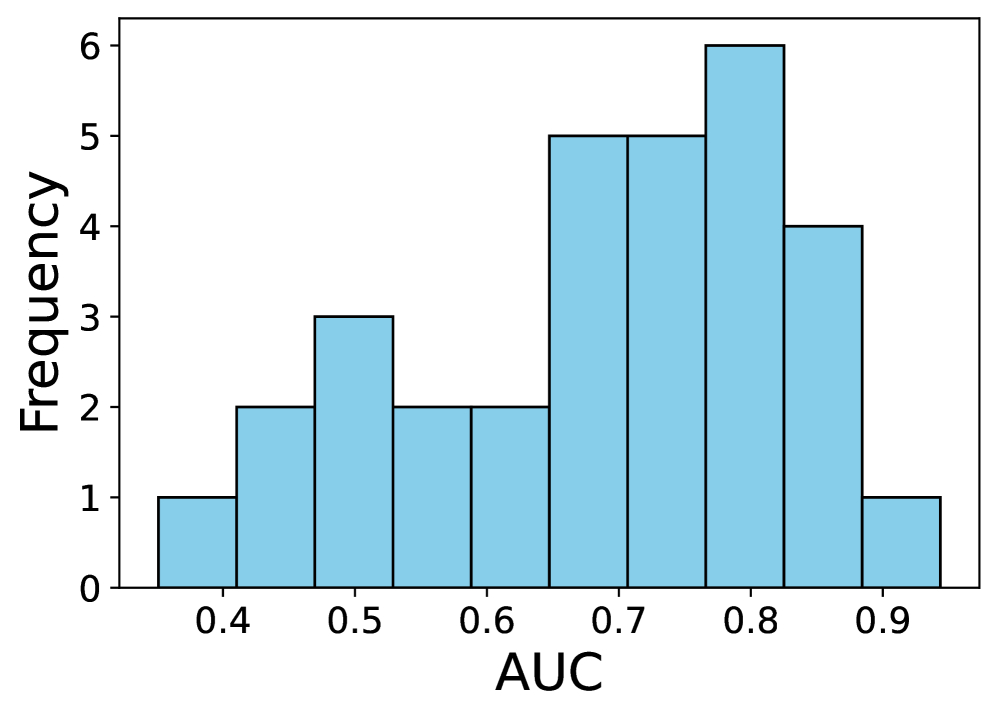
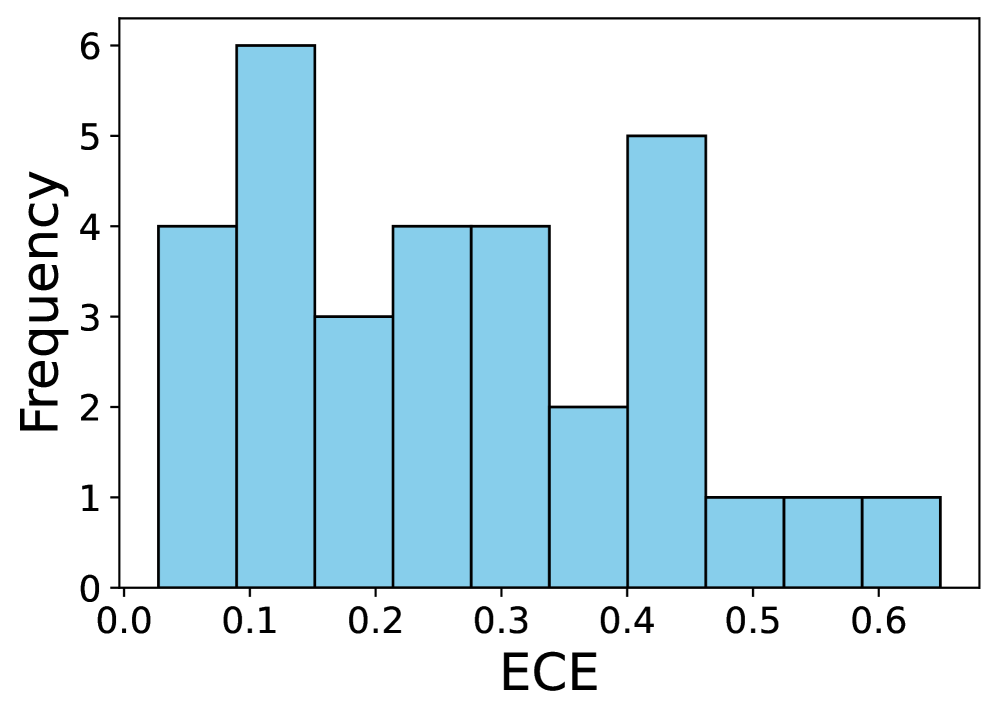
本文研究了大型语言模型(LLM)作为零样本模型,在生成个体层面特征(例如,作为风险模型或扩充调查数据集)方面的能力。核心问题是:用户在何种情况下可以确信LLM能够为其特定任务提供高质量的预测?为了解决这个问题,我们对LLM在各种表格预测任务中的零样本预测能力进行了大规模的实证研究。我们发现,LLM的性能变化很大,无论是在同一数据集内的任务之间,还是在不同的数据集之间。然而,当LLM在基本预测任务上表现良好时,其预测的概率成为个体层面准确性的更强信号。然后,我们构建了指标来预测LLM在任务层面的性能,旨在区分LLM可能表现良好的任务和它们可能不适合的任务。我们发现,其中一些指标(每个指标都在没有标签数据的情况下进行评估)产生了LLM在新任务上的预测性能的强烈信号。
🔬 方法详解
问题定义:论文旨在解决如何预测大型语言模型(LLM)在零样本概率预测任务中的表现,特别是在表格数据预测任务中。现有方法缺乏一种有效的机制来评估LLM在特定任务上的适用性,导致用户难以判断LLM是否能够提供高质量的预测。LLM在不同任务和数据集上的表现差异很大,需要一种方法来区分LLM可能表现良好的任务和可能不适合的任务。
核心思路:论文的核心思路是构建一系列无需标注数据的指标,这些指标能够反映LLM在特定任务上的表现潜力。通过分析LLM在无标签数据上的行为,例如预测概率的分布和一致性,来预测其在有标签数据上的预测准确性。这种方法旨在提供一种快速且经济的方式来评估LLM的适用性,而无需进行昂贵的有标签数据收集和模型训练。
技术框架:论文的技术框架主要包括以下几个阶段:1) 大规模实证研究:对LLM在各种表格预测任务中的零样本预测能力进行评估,发现LLM性能的高度可变性。2) 指标构建:构建一系列无需标注数据的指标,用于预测LLM在任务层面的性能。这些指标可能包括LLM预测概率的统计特征、一致性度量等。3) 性能预测:使用构建的指标来预测LLM在新的、未见过的任务上的预测性能。4) 评估验证:通过实验验证指标的预测能力,评估其区分LLM适用任务和不适用任务的能力。
关键创新:论文的关键创新在于提出了一系列无需标注数据的指标,用于预测LLM在零样本概率预测任务中的表现。这些指标的评估不需要任何有标签数据,因此可以快速且经济地评估LLM在特定任务上的适用性。与现有方法相比,该方法避免了昂贵的有标签数据收集和模型训练,为LLM的应用提供了更便捷的评估方式。
关键设计:论文的关键设计包括:1) 指标的选择:选择合适的指标来反映LLM的预测能力,例如预测概率的分布、一致性等。2) 指标的评估方法:设计合适的评估方法来验证指标的预测能力,例如使用相关性分析、分类器等。3) 实验设置:设计合理的实验设置,包括选择合适的表格预测任务、LLM模型等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的无需标注数据的指标能够有效预测LLM在各种表格预测任务中的性能。这些指标能够区分LLM可能表现良好的任务和可能不适合的任务,为LLM的应用提供了指导。具体性能数据和对比基线在论文中进行了详细描述(具体数值未知)。
🎯 应用场景
该研究成果可应用于各种需要利用LLM进行零样本预测的场景,例如风险评估、市场调研、用户画像等。通过使用论文提出的指标,用户可以快速评估LLM在特定任务上的适用性,从而选择合适的LLM应用场景,提高预测的准确性和效率。该研究还有助于推动LLM在实际应用中的普及和发展。
📄 摘要(原文)
Recent work has investigated the capabilities of large language models (LLMs) as zero-shot models for generating individual-level characteristics (e.g., to serve as risk models or augment survey datasets). However, when should a user have confidence that an LLM will provide high-quality predictions for their particular task? To address this question, we conduct a large-scale empirical study of LLMs' zero-shot predictive capabilities across a wide range of tabular prediction tasks. We find that LLMs' performance is highly variable, both on tasks within the same dataset and across different datasets. However, when the LLM performs well on the base prediction task, its predicted probabilities become a stronger signal for individual-level accuracy. Then, we construct metrics to predict LLMs' performance at the task level, aiming to distinguish between tasks where LLMs may perform well and where they are likely unsuitable. We find that some of these metrics, each of which are assessed without labeled data, yield strong signals of LLMs' predictive performance on new tasks.