Fleming-R1: Toward Expert-Level Medical Reasoning via Reinforcement Learning
作者: Chi Liu, Derek Li, Yan Shu, Robin Chen, Derek Duan, Teng Fang, Bryan Dai
分类: cs.LG, cs.CL
发布日期: 2025-09-18
💡 一句话要点
Fleming-R1:通过强化学习实现专家级医学推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学推理 强化学习 大型语言模型 知识图谱 思维链 临床应用 可验证AI
📋 核心要点
- 现有医学AI模型在临床推理中面临挑战,需要兼顾准确性和推理过程的透明性。
- Fleming-R1通过RODS数据策略、CoT冷启动和RLVR框架,提升模型的可验证医学推理能力。
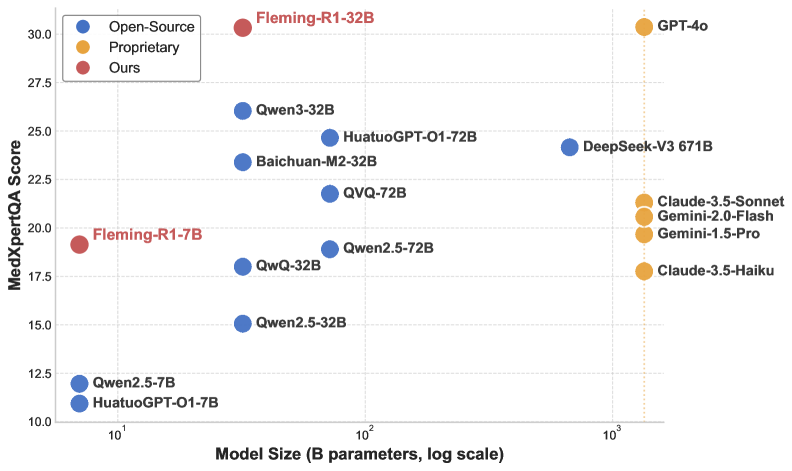
- 实验结果表明,Fleming-R1在多个医学基准测试中超越了大型基线模型,接近GPT-4o的性能。
📝 摘要(中文)
大型语言模型在医学应用中展现出潜力,但由于需要准确的答案和透明的推理过程,实现专家级临床推理仍然具有挑战性。为了解决这个问题,我们推出了Fleming-R1模型,该模型通过三个互补的创新设计来实现可验证的医学推理。首先,我们的面向推理的数据策略(RODS)将精心策划的医学问答数据集与知识图谱引导的合成相结合,以提高对代表性不足的疾病、药物和多跳推理链的覆盖率。其次,我们采用思维链(CoT)冷启动来从教师模型中提炼高质量的推理轨迹,从而建立稳健的推理先验。第三,我们使用群体相对策略优化实施了一个两阶段的基于可验证奖励的强化学习(RLVR)框架,该框架巩固了核心推理技能,同时通过自适应硬样本挖掘来针对持续存在的失败模式。在不同的医学基准测试中,Fleming-R1提供了显著的参数高效改进:7B变体超越了更大的基线模型,而32B模型实现了与GPT-4o接近的性能,并且始终优于强大的开源替代方案。这些结果表明,结构化数据设计、面向推理的初始化和可验证的强化学习可以将临床推理提升到超越简单准确性优化的水平。我们公开发布Fleming-R1,以促进医学AI中透明、可重复和可审计的进展,从而在高度敏感的临床环境中实现更安全的部署。
🔬 方法详解
问题定义:现有医学AI模型虽然在准确性上有所提升,但缺乏透明的推理过程,难以在临床环境中安全部署。模型需要能够解释其推理过程,并能处理各种复杂的医学知识,包括罕见疾病、药物相互作用和多跳推理。
核心思路:Fleming-R1的核心思路是通过结构化的数据设计、面向推理的初始化和可验证的强化学习来提升模型的临床推理能力。通过强化学习,模型可以学习到更有效的推理策略,并能针对特定的失败模式进行优化。
技术框架:Fleming-R1的技术框架包含三个主要组成部分:1) 面向推理的数据策略(RODS),用于生成高质量的医学知识数据;2) 思维链(CoT)冷启动,用于从教师模型中提炼推理轨迹;3) 基于可验证奖励的强化学习(RLVR)框架,用于优化模型的推理能力。RLVR框架采用两阶段训练,首先巩固核心推理技能,然后针对失败模式进行优化。
关键创新:Fleming-R1的关键创新在于其可验证的强化学习框架。传统的强化学习方法难以应用于医学领域,因为奖励信号往往难以定义。Fleming-R1通过使用可验证的奖励信号,例如答案的正确性和推理过程的合理性,来训练模型。此外,该模型还采用了自适应硬样本挖掘,以针对持续存在的失败模式进行优化。
关键设计:RODS数据策略使用知识图谱来指导数据的合成,从而提高对代表性不足的疾病、药物和多跳推理链的覆盖率。CoT冷启动使用教师模型生成高质量的推理轨迹,作为强化学习的初始策略。RLVR框架使用群体相对策略优化,以提高训练的稳定性和效率。具体的损失函数和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
Fleming-R1在多个医学基准测试中取得了显著的性能提升。7B变体超越了更大的基线模型,而32B模型实现了与GPT-4o接近的性能,并且始终优于强大的开源替代方案。这些结果表明,结构化数据设计、面向推理的初始化和可验证的强化学习可以有效提升医学AI模型的临床推理能力。
🎯 应用场景
Fleming-R1的潜在应用领域包括辅助诊断、治疗方案推荐、医学知识问答等。该研究的实际价值在于提高医学AI模型的可靠性和可解释性,从而使其能够在临床环境中安全部署。未来,该模型可以用于构建智能医疗助手,帮助医生做出更明智的决策,并提高医疗服务的质量和效率。
📄 摘要(原文)
While large language models show promise in medical applications, achieving expert-level clinical reasoning remains challenging due to the need for both accurate answers and transparent reasoning processes. To address this challenge, we introduce Fleming-R1, a model designed for verifiable medical reasoning through three complementary innovations. First, our Reasoning-Oriented Data Strategy (RODS) combines curated medical QA datasets with knowledge-graph-guided synthesis to improve coverage of underrepresented diseases, drugs, and multi-hop reasoning chains. Second, we employ Chain-of-Thought (CoT) cold start to distill high-quality reasoning trajectories from teacher models, establishing robust inference priors. Third, we implement a two-stage Reinforcement Learning from Verifiable Rewards (RLVR) framework using Group Relative Policy Optimization, which consolidates core reasoning skills while targeting persistent failure modes through adaptive hard-sample mining. Across diverse medical benchmarks, Fleming-R1 delivers substantial parameter-efficient improvements: the 7B variant surpasses much larger baselines, while the 32B model achieves near-parity with GPT-4o and consistently outperforms strong open-source alternatives. These results demonstrate that structured data design, reasoning-oriented initialization, and verifiable reinforcement learning can advance clinical reasoning beyond simple accuracy optimization. We release Fleming-R1 publicly to promote transparent, reproducible, and auditable progress in medical AI, enabling safer deployment in high-stakes clinical environments.