Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
作者: Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, Dong Yu
分类: cs.LG, cs.CL
发布日期: 2025-09-18 (更新: 2025-10-01)
🔗 代码/项目: GITHUB
💡 一句话要点
EVOL-RL:一种无标签自进化语言模型框架,通过多数投票选择和新颖性驱动变异实现模型提升。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自进化学习 无监督学习 语言模型 强化学习 新颖性奖励 多数投票 领域泛化
📋 核心要点
- 现有自提升方法依赖置信度等自我确认信号生成奖励,易导致模型过度自信和熵崩溃,降低推理能力。
- EVOL-RL框架模仿进化原则,结合多数投票(稳定性)和新颖性奖励(探索),平衡选择与变异。
- 实验表明,EVOL-RL显著提升了模型在AIME25上的pass@n指标,并增强了领域外泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地采用基于可验证奖励的强化学习(RLVR)进行训练,但实际部署需要模型能够在没有标签或外部评判的情况下自我改进。现有的自我改进方法主要依赖于自我确认信号(例如,置信度、熵或一致性)来生成奖励。这种依赖驱使模型倾向于过度自信、多数人支持的解决方案,导致熵崩溃,从而降低pass@n和推理复杂度。为了解决这个问题,我们提出了EVOL-RL,一个无标签框架,它反映了通过平衡选择和变异的进化原则。具体而言,EVOL-RL保留多数投票的答案作为稳定性的锚点,但增加了一个新颖性感知奖励,该奖励通过每个采样解的推理与其他并发生成的响应的差异程度来评分。这种多数人支持稳定性+新颖性支持探索的规则反映了变异-选择原则:选择防止漂移,而新颖性防止崩溃。评估结果表明,EVOL-RL始终优于仅多数人的基线;例如,在无标签AIME24上训练将Qwen3-4B-Base AIME25的pass@1从基线的4.6%提升到16.4%,pass@16从18.5%提升到37.9%。EVOL-RL不仅防止了领域内多样性崩溃,还提高了领域外泛化能力(从数学推理到更广泛的任务,例如GPQA、MMLU-Pro和BBEH)。
🔬 方法详解
问题定义:现有的大型语言模型自提升方法,过度依赖模型自身的置信度、一致性等信号作为奖励,导致模型倾向于选择多数派答案,从而陷入“信息茧房”,降低了模型的多样性和解决复杂问题的能力,最终导致性能下降。
核心思路:EVOL-RL的核心思路是借鉴生物进化中的“选择+变异”原则。通过多数投票机制来保证模型的稳定性,防止模型性能漂移;同时,引入新颖性奖励,鼓励模型探索不同的推理路径,避免模型陷入局部最优解,从而提升模型的整体性能和泛化能力。
技术框架:EVOL-RL框架主要包含以下几个阶段:1) 模型生成多个候选答案;2) 对候选答案进行多数投票,选择得票最多的答案作为锚点;3) 计算每个候选答案的新颖性得分,新颖性得分越高,说明该答案的推理路径与其他答案的差异越大;4) 将多数投票结果和新颖性得分结合起来,作为模型的奖励信号,用于训练模型。
关键创新:EVOL-RL的关键创新在于引入了新颖性奖励,鼓励模型探索不同的推理路径。与传统的自提升方法不同,EVOL-RL不仅仅关注模型自身的置信度,更关注模型推理过程的多样性。这种新颖性奖励机制可以有效地避免模型陷入局部最优解,从而提升模型的整体性能。
关键设计:新颖性奖励的设计是EVOL-RL的关键。论文中,新颖性奖励通过计算每个候选答案的推理路径与其他答案的差异程度来确定。具体的计算方法可以使用各种文本相似度度量方法,例如余弦相似度、编辑距离等。此外,多数投票的权重和新颖性奖励的权重也需要进行仔细调整,以平衡稳定性和探索之间的关系。
🖼️ 关键图片
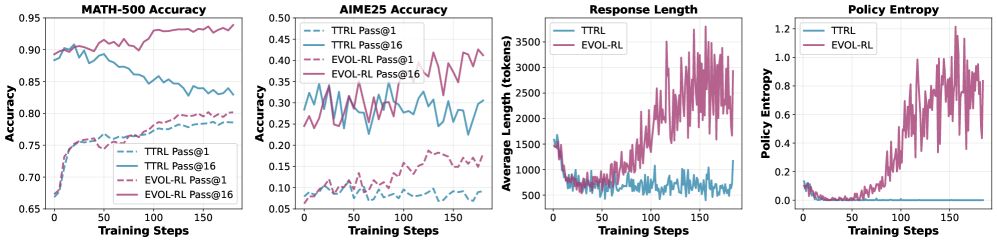

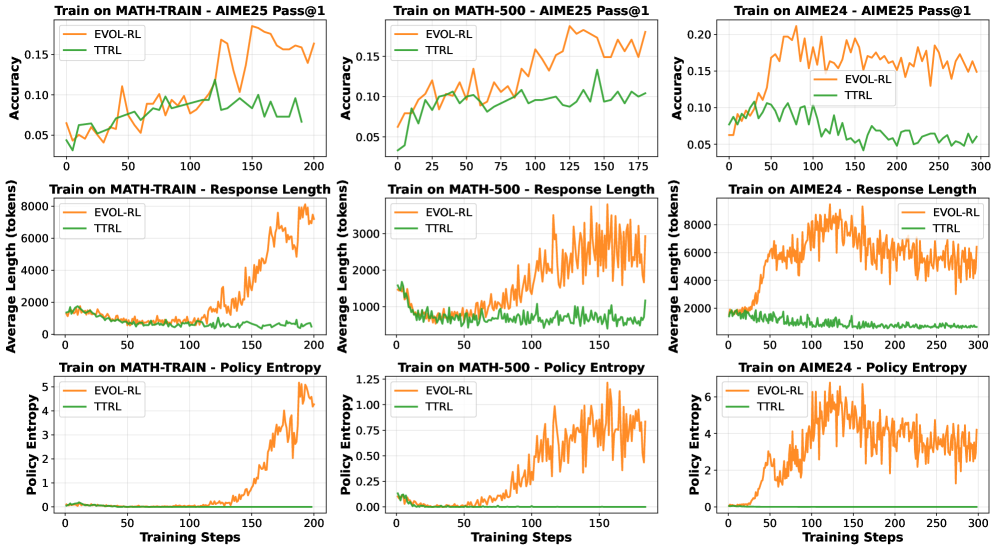
📊 实验亮点
EVOL-RL在AIME24数据集上进行训练,并在AIME25数据集上进行测试,结果表明EVOL-RL显著提升了Qwen3-4B-Base模型的性能。具体而言,pass@1指标从基线的4.6%提升到16.4%,pass@16指标从18.5%提升到37.9%。此外,EVOL-RL还提高了模型在GPQA、MMLU-Pro和BBEH等领域外数据集上的泛化能力。
🎯 应用场景
EVOL-RL框架具有广泛的应用前景,可以应用于各种需要语言模型进行自我改进的场景,例如智能客服、自动写作、机器翻译等。该框架尤其适用于缺乏人工标注数据的场景,可以帮助模型在没有人工干预的情况下不断提升性能,降低模型训练成本。
📄 摘要(原文)
Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing self-improvement approaches primarily rely on self-confirmation signals (e.g., confidence, entropy, or consistency) to generate rewards. This reliance drives models toward over-confident, majority-favored solutions, causing an entropy collapse that degrades pass@n and reasoning complexity. To address this, we propose EVOL-RL, a label-free framework that mirrors the evolutionary principle of balancing selection with variation. Concretely, EVOL-RL retains the majority-voted answer as an anchor for stability, but adds a novelty-aware reward that scores each sampled solution by how different its reasoning is from other concurrently generated responses. This majority-for-stability + novelty-for-exploration rule mirrors the variation-selection principle: selection prevents drift, while novelty prevents collapse. Evaluation results show that EVOL-RL consistently outperforms the majority-only baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from baseline's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents in-domain diversity collapse but also improves out-of-domain generalization (from math reasoning to broader tasks, e.g., GPQA, MMLU-Pro, and BBEH). The code is available at: https://github.com/YujunZhou/EVOL-RL.