Mind the Gap: Data Rewriting for Stable Off-Policy Supervised Fine-Tuning
作者: Shiwan Zhao, Xuyang Zhao, Jiaming Zhou, Aobo Kong, Qicheng Li, Yong Qin
分类: cs.LG, cs.CL
发布日期: 2025-09-18 (更新: 2025-09-19)
🔗 代码/项目: GITHUB
💡 一句话要点
提出数据重写框架,解决SFT中Off-Policy学习的分布偏移问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 监督微调 Off-Policy学习 数据重写 重要性采样 分布偏移
📋 核心要点
- SFT面临Off-Policy学习的挑战,即训练数据与目标策略存在分布差异,导致训练不稳定。
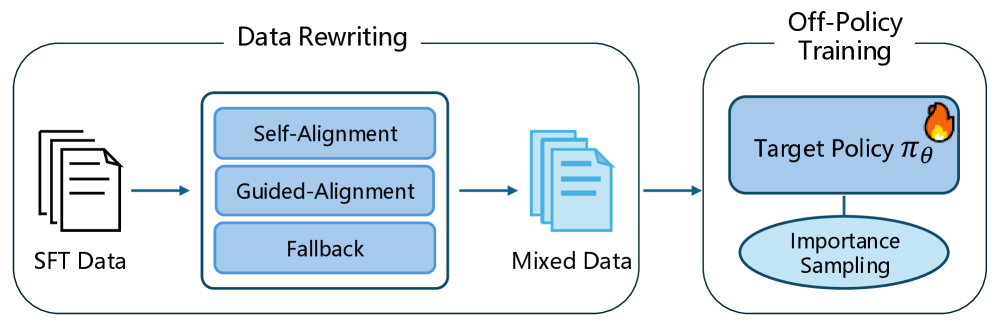
- 提出数据重写框架,通过引导模型重新解决错误答案,主动缩小训练数据与目标策略的差距。
- 实验表明,该方法在数学推理任务上显著优于传统SFT和现有最佳方法,提升了模型性能。
📝 摘要(中文)
大规模语言模型的监督微调(SFT)可以被视为一个Off-Policy学习问题,其中专家演示来自固定的行为策略,而训练旨在优化目标策略。重要性采样是校正这种分布不匹配的标准工具,但大的策略差距会导致权重倾斜、高方差和不稳定的优化。现有方法通过KL惩罚或裁剪来缓解这个问题,这些方法被动地限制更新,而不是主动地缩小差距。我们提出了一个简单而有效的数据重写框架,在训练前主动缩小策略差距。对于每个问题,正确的模型生成解决方案被保留为On-Policy数据,而错误的解决方案通过引导重新解决来重写,仅在需要时才回退到专家演示。这使训练分布与目标策略对齐,从而降低方差并提高稳定性。为了处理重写后的残余不匹配,我们还在训练期间应用重要性采样,形成一个两阶段方法,将数据级对齐与轻量级优化级校正相结合。在五个数学推理基准上的实验表明,相对于vanilla SFT和最先进的动态微调(DFT)方法,该方法具有一致且显著的优势。数据和代码将在https://github.com/NKU-HLT/Off-Policy-SFT发布。
🔬 方法详解
问题定义:论文关注的是大规模语言模型(LLM)的监督微调(SFT)过程中,由于训练数据(专家演示)与模型期望学习的目标策略之间存在分布差异,导致训练不稳定和性能下降的问题。现有的方法,如KL散度惩罚和梯度裁剪,虽然可以缓解这个问题,但本质上是被动地限制模型的更新,无法从根本上解决分布差异。
核心思路:论文的核心思路是通过数据重写,主动地将训练数据的分布向目标策略靠拢。具体来说,对于模型已经能够正确解决的问题,保留模型生成的答案;对于模型无法正确解决的问题,引导模型重新解决,或者回退到专家演示。这样,训练数据中就包含了更多模型能够理解和学习的“On-Policy”数据,从而缩小了分布差异。
技术框架:该方法包含两个主要阶段:数据重写阶段和训练阶段。在数据重写阶段,首先使用模型生成答案,然后判断答案是否正确。如果正确,则保留模型生成的答案;如果错误,则尝试引导模型重新解决,如果仍然无法解决,则使用专家演示。在训练阶段,使用重写后的数据进行SFT,并结合重要性采样来进一步校正残余的分布差异。
关键创新:该方法最重要的创新点在于主动地缩小训练数据与目标策略之间的差距。与现有方法被动地限制模型更新不同,该方法通过数据重写,直接改变了训练数据的分布,使其更接近目标策略。这种主动的策略能够更有效地解决Off-Policy学习中的分布偏移问题。
关键设计:数据重写阶段的关键在于如何判断模型生成的答案是否正确,以及如何引导模型重新解决。论文中使用了具体的数学推理任务作为实验对象,因此可以使用数学公式的正确性作为判断标准。引导模型重新解决的方法可以是提供更多的上下文信息或者使用更强的模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在五个数学推理基准上均取得了显著的性能提升,超过了vanilla SFT和当前最先进的动态微调(DFT)方法。具体提升幅度未知,但论文强调了“consistent and significant gains”,表明该方法具有较强的泛化能力和实用价值。
🎯 应用场景
该研究成果可广泛应用于需要通过专家数据进行模型微调的场景,尤其是在专家数据与模型目标策略存在较大差异的情况下。例如,可以应用于机器人控制、对话系统、代码生成等领域,提高模型训练的稳定性和性能,降低对高质量专家数据的依赖。
📄 摘要(原文)
Supervised fine-tuning (SFT) of large language models can be viewed as an off-policy learning problem, where expert demonstrations come from a fixed behavior policy while training aims to optimize a target policy. Importance sampling is the standard tool for correcting this distribution mismatch, but large policy gaps lead to skewed weights, high variance, and unstable optimization. Existing methods mitigate this issue with KL penalties or clipping, which passively restrict updates rather than actively reducing the gap. We propose a simple yet effective data rewriting framework that proactively shrinks the policy gap before training. For each problem, correct model-generated solutions are kept as on-policy data, while incorrect ones are rewritten through guided re-solving, falling back to expert demonstrations only when needed. This aligns the training distribution with the target policy, reducing variance and improving stability. To handle residual mismatch after rewriting, we additionally apply importance sampling during training, forming a two-stage approach that combines data-level alignment with lightweight optimization-level correction. Experiments on five mathematical reasoning benchmarks show consistent and significant gains over both vanilla SFT and the state-of-the-art Dynamic Fine-Tuning (DFT) approach. Data and code will be released at https://github.com/NKU-HLT/Off-Policy-SFT.