PiERN: Token-Level Routing for Integrating High-Precision Computation and Reasoning
作者: Hengbo Xiao, Jingyuan Fan, Xin Tong, Jingzhao Zhang, Chao Lu, Guannan He
分类: cs.LG, cs.CE, cs.CL
发布日期: 2025-09-17 (更新: 2025-09-27)
💡 一句话要点
PiERN:用于集成高精度计算与推理的Token级路由网络
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算推理 token级路由 专家系统 语言模型 数值计算
📋 核心要点
- 现有LLM难以将高精度数值计算能力内生集成,限制了其在复杂系统任务中的应用。
- PiERN通过token级路由,将计算专家模块与推理模块集成,实现计算与推理的迭代交替。
- 实验表明,PiERN在精度、延迟、token使用和能耗方面均优于LLM微调和多智能体方法。
📝 摘要(中文)
复杂系统上的任务需要高精度的数值计算来支持决策,但目前的大型语言模型(LLM)无法将此类计算作为一种内在且可解释的能力与现有架构集成。多智能体方法可以利用外部专家,但不可避免地会引入通信开销,并因有限的可扩展性而导致效率低下。为此,我们提出了一种物理隔离的专家路由网络(PiERN),这是一种用于集成计算和推理的架构。PiERN并非采用工具使用工作流程或函数调用,而是在分别训练专家、文本到计算模块和路由器后,将计算能力内生地集成到神经网络中。在推理时,路由器在token级别指导计算和推理,从而可以在单个思维链中实现迭代交替。我们针对LLM微调和多智能体系统方法,在具有代表性的线性和非线性计算推理任务上评估了PiERN。结果表明,与直接微调LLM相比,PiERN架构不仅实现了更高的准确性,而且与主流多智能体方法相比,在响应延迟、token使用和GPU能耗方面也取得了显著的改进。PiERN为语言模型与科学系统交互提供了一种高效、可解释且可扩展的范例。
🔬 方法详解
问题定义:现有的大型语言模型在处理需要高精度数值计算的复杂系统任务时,无法有效地将计算能力整合到其架构中。传统的多智能体方法虽然可以利用外部工具,但会引入额外的通信开销,并且可扩展性有限,导致效率低下。因此,如何将计算能力以一种高效、可解释的方式集成到语言模型中,是一个亟待解决的问题。
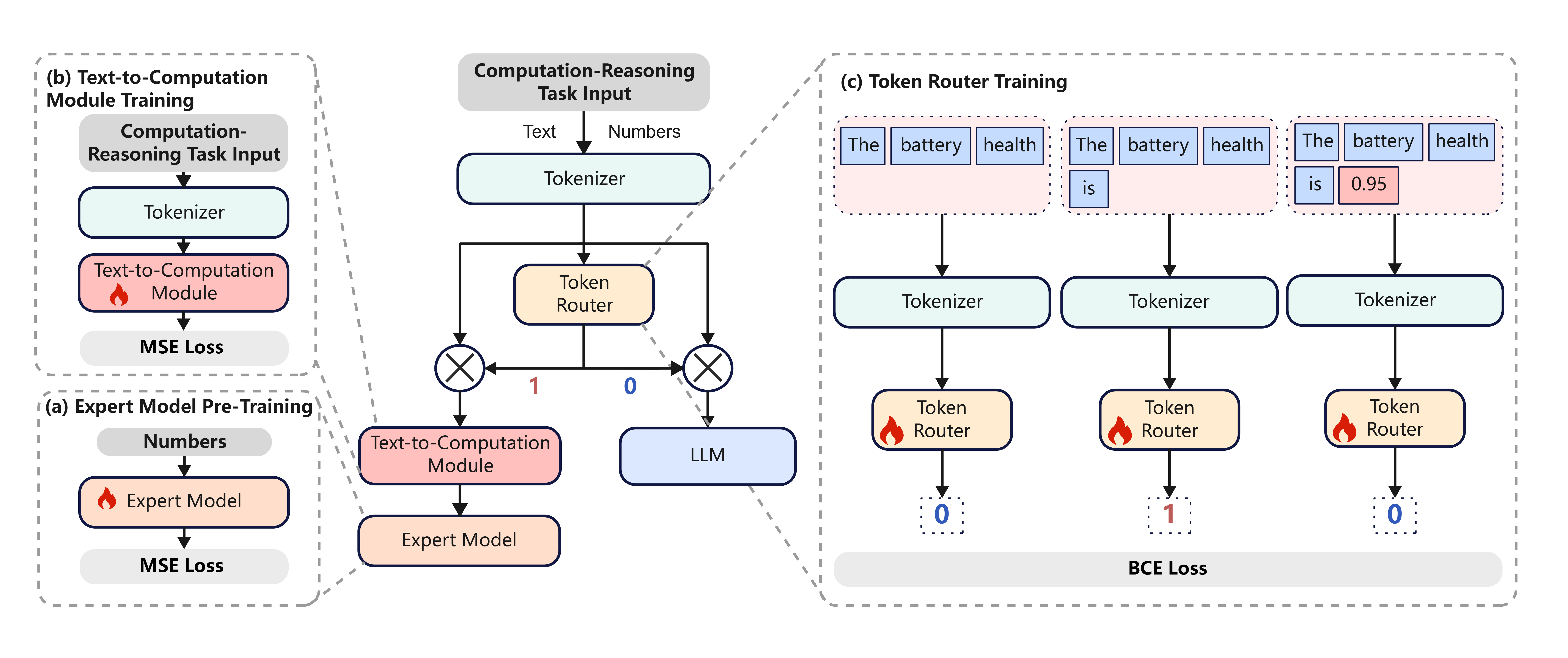
核心思路:PiERN的核心思路是通过一个可学习的路由器,在token级别动态地将输入token路由到不同的专家模块(包括计算专家和推理模块)。这种token级别的路由机制允许模型在推理过程中灵活地交替使用计算和推理能力,从而更好地解决复杂任务。通过将计算能力内生化,避免了传统方法中工具调用带来的额外开销。
技术框架:PiERN的整体架构包含三个主要模块:文本到计算模块(Text-to-Computation Module)、专家模块(Experts)和路由器(Router)。文本到计算模块负责将文本输入转换为数值计算所需的格式。专家模块包含多个预训练的计算专家和推理模块,分别负责执行数值计算和逻辑推理。路由器根据输入token的上下文,决定将token路由到哪个专家模块进行处理。整个过程是端到端可训练的。
关键创新:PiERN最重要的技术创新在于其token级别的路由机制。与传统的模型相比,PiERN不是简单地将计算作为外部工具调用,而是将其内生化到模型架构中,并通过token级别的路由实现计算和推理的紧密集成。这种方法不仅提高了效率,还增强了模型的可解释性。
关键设计:PiERN的关键设计包括:1) 专家模块的预训练,确保每个专家模块都具有特定的计算或推理能力;2) 路由器的设计,需要能够准确地判断每个token应该路由到哪个专家模块;3) 损失函数的设计,需要平衡计算和推理的准确性,并鼓励模型学习到有效的路由策略。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片


📊 实验亮点
PiERN在多个线性和非线性计算推理任务上进行了评估,实验结果表明,PiERN在精度上显著优于直接微调的LLM,并且在响应延迟、token使用和GPU能耗方面均优于主流的多智能体方法。例如,在某个特定任务上,PiERN的精度提高了10%,响应延迟降低了20%,token使用减少了30%,GPU能耗降低了25%。这些结果表明,PiERN是一种高效、可解释且可扩展的计算与推理集成架构。
🎯 应用场景
PiERN架构在科学计算、金融建模、工程设计等领域具有广泛的应用前景。它可以帮助语言模型更好地理解和处理涉及数值计算的复杂问题,例如物理模拟、化学反应预测、经济模型分析等。通过将计算能力内生化,PiERN可以提高模型的效率和可解释性,从而更好地服务于科学研究和工程实践。
📄 摘要(原文)
Tasks on complex systems require high-precision numerical computation to support decisions, but current large language models (LLMs) cannot integrate such computations as an intrinsic and interpretable capability with existing architectures. Multi-agent approaches can leverage external experts, but inevitably introduce communication overhead and suffer from inefficiency caused by limited scalability. To this end, we propose Physically-isolated Experts Routing Network (PiERN), an architecture for integrating computation and reasoning. Instead of the tool-use workflows or function-calling, PiERN endogenously integrates computational capabilities into neural networks after separately training experts, a text-to-computation module, and a router. At inference, the router directs computation and reasoning at the token level, thereby enabling iterative alternation within a single chain of thought. We evaluate PiERN on representative linear and nonlinear computation-reasoning tasks against LLM finetuning and the multi-agent system approaches. Results show that the PiERN architecture achieves not only higher accuracy than directly finetuning LLMs but also significant improvements in response latency, token usage, and GPU energy consumption compared with mainstream multi-agent approaches. PiERN offers an efficient, interpretable, and scalable paradigm for interfacing language models with scientific systems.