UI-S1: Advancing GUI Automation via Semi-online Reinforcement Learning
作者: Zhengxi Lu, Jiabo Ye, Fei Tang, Yongliang Shen, Haiyang Xu, Ziwei Zheng, Weiming Lu, Ming Yan, Fei Huang, Jun Xiao, Yueting Zhuang
分类: cs.LG, cs.AI
发布日期: 2025-09-15 (更新: 2025-09-24)
备注: 22 pages, 17 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出半在线强化学习UI-S1,提升GUI自动化Agent的多步交互能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: GUI自动化 强化学习 半在线学习 多步交互 用户界面 智能Agent
📋 核心要点
- 现有GUI自动化Agent面临离线RL缺乏轨迹奖励和在线RL奖励稀疏、成本高的难题。
- 提出半在线强化学习,在离线轨迹上模拟在线RL,利用Patch Module恢复轨迹差异,引入未来回报。
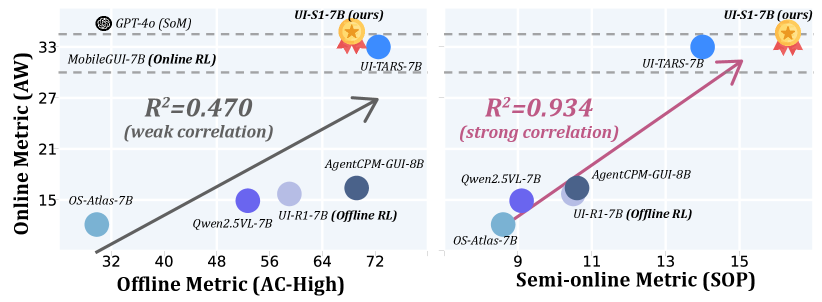
- 实验表明,该方法在四个动态基准测试中取得了SOTA性能,显著提升了GUI自动化效果。
📝 摘要(中文)
本文提出了一种新的半在线强化学习范式,旨在解决GUI自动化Agent在离线强化学习和在线强化学习之间面临的困境。离线强化学习虽然能在预收集的轨迹上稳定训练,但缺乏轨迹级别的奖励信号,难以执行多步任务;在线强化学习虽然能通过环境交互获取这些信号,但奖励稀疏且部署成本高昂。半在线强化学习通过在离线轨迹上模拟在线强化学习来解决这个问题。在每次rollout过程中,保留原始模型在多轮对话中的输出,并使用Patch Module自适应地恢复rollout轨迹与专家轨迹之间的差异。为了捕获长期训练信号,半在线强化学习将折现的未来回报引入奖励计算,并使用加权的步级和episode级优势来优化策略。此外,本文还提出了半在线性能(SOP)指标,该指标与真实的在线性能更吻合,可作为实际评估的有效代理。实验表明,半在线强化学习在四个动态基准测试中,在7B模型中实现了SOTA性能,并且相对于基线模型有显著提升(例如,在AndroidWorld上+12.0%,在AITW上+23.8%),证明了在离线训练效率和在线多轮推理之间架起桥梁的显著进展。
🔬 方法详解
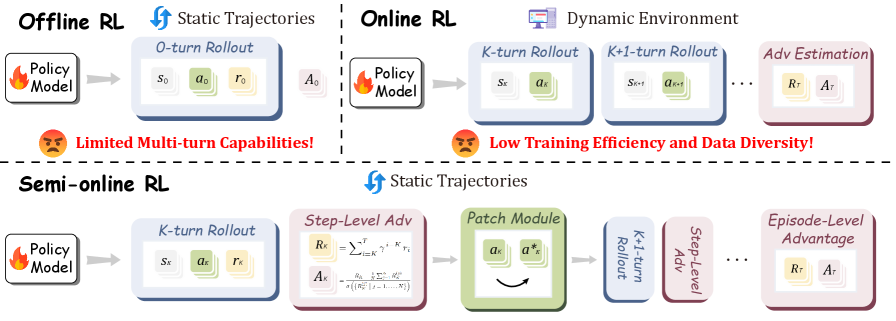
问题定义:现有的GUI自动化Agent在利用强化学习进行训练时,面临着离线强化学习和在线强化学习之间的两难选择。离线强化学习虽然可以利用预先收集好的轨迹进行训练,避免了与环境的直接交互,但由于缺乏轨迹级别的奖励信号,难以进行多步任务的执行和长期目标的优化。而在线强化学习虽然可以通过与环境的交互来获取奖励信号,但由于奖励的稀疏性和与真实环境交互的高成本,导致训练效率低下,难以实际部署。
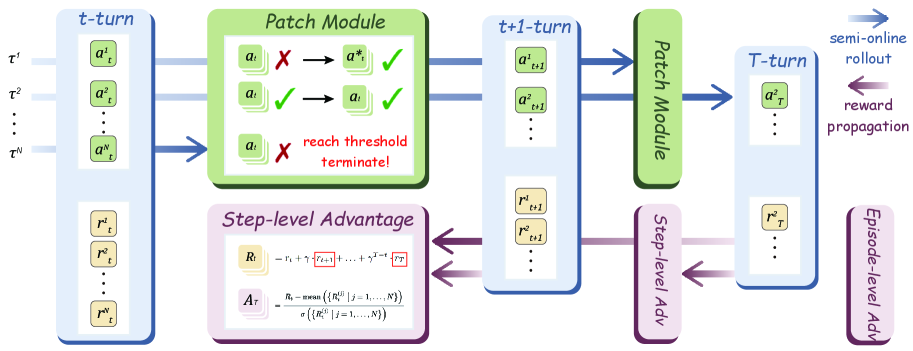
核心思路:本文的核心思路是在离线数据上模拟在线强化学习的过程,从而结合两者的优点。具体来说,就是在离线轨迹上进行rollout,并尽可能地保留原始模型的输出,同时引入一个Patch Module来修正rollout轨迹与专家轨迹之间的偏差。通过这种方式,可以在离线数据上获得类似在线强化学习的奖励信号,从而更好地进行多步任务的训练。
技术框架:整个框架主要包含以下几个模块:1)离线数据集:包含预先收集好的GUI交互轨迹;2)策略模型:用于生成GUI操作;3)Patch Module:用于修正rollout轨迹与专家轨迹的偏差;4)奖励函数:用于评估rollout轨迹的质量,包含步级奖励和episode级奖励;5)优化器:用于更新策略模型的参数。整个流程是:首先,从离线数据集中采样一个轨迹;然后,使用策略模型进行rollout,并使用Patch Module修正轨迹;接着,计算奖励函数,并使用优化器更新策略模型。
关键创新:本文最重要的技术创新点在于提出了半在线强化学习的范式,即在离线数据上模拟在线强化学习的过程。这种方法结合了离线强化学习的训练效率和在线强化学习的奖励信号,从而更好地进行多步任务的训练。此外,Patch Module的设计也是一个重要的创新点,它可以有效地修正rollout轨迹与专家轨迹之间的偏差,从而提高训练的稳定性。
关键设计:在奖励函数的设计上,本文引入了折现的未来回报,从而更好地捕获长期训练信号。此外,本文还使用了加权的步级和episode级优势来优化策略,从而更好地平衡短期奖励和长期目标。Patch Module的具体实现可以采用Transformer等模型,其目标是最小化rollout轨迹与专家轨迹之间的差异。在训练过程中,可以采用Adam等优化器来更新策略模型的参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的半在线强化学习方法在四个动态基准测试中,在7B模型中实现了SOTA性能。例如,在AndroidWorld数据集上,相比于基线模型,性能提升了12.0%;在AITW数据集上,性能提升了23.8%。这些结果表明,该方法能够有效地提升GUI自动化Agent的多步交互能力。
🎯 应用场景
该研究成果可广泛应用于各种GUI自动化场景,例如移动应用测试、网页自动化、智能助手等。通过提升Agent的多步交互能力,可以实现更复杂的自动化任务,例如自动完成购物流程、自动填写表单等。该技术还有潜力应用于机器人领域,提升机器人与用户交互的自然性和智能化水平。
📄 摘要(原文)
Graphical User Interface (GUI) agents have demonstrated remarkable progress in automating complex user interface interactions through reinforcement learning. However, current approaches face a fundamental dilemma: offline RL enables stable training on pre-collected trajectories, but struggles with multi-step task execution for lack of trajectory-level reward signals; online RL captures these signals through environment interaction, but suffers from sparse rewards and prohibitive deployment costs. To address it, we present Semi-online Reinforcement Learning, a novel paradigm that simulates online RL on offline trajectories. During each rollout process, we preserve the original model output within the multi-turn dialogue, where a Patch Module adaptively recovers the divergence between rollout and expert trajectories. To capture long-term training signals, Semi-online RL introduces discounted future returns into the reward computation and optimizes the policy with weighted step-level and episode-level advantages. We further introduce Semi-Online Performance (SOP), a metric that aligns better with true online performance, serving as a practical and effective proxy for real-world evaluation. Experiments show that ours Semi-online RL achieves SOTA performance among 7B models across four dynamic benchmarks, with significant gains over the base model (e.g., +12.0% on AndroidWorld, +23.8% on AITW), demonstrating significant progress in bridging the gap between offline training efficiency and online multi-turn reasoning. The code is available at https://github.com/X-PLUG/MobileAgent/tree/main/UI-S1.