From Parameters to Performance: A Data-Driven Study on LLM Structure and Development
作者: Suqing Wang, Zuchao Li, Luohe Shi, Bo Du, Hai Zhao, Yun Li, Qianren Wang
分类: cs.LG, cs.AI
发布日期: 2025-09-14
备注: Accepted by EMNLP 2025
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
构建大规模LLM结构-性能数据集,揭示模型结构对性能的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型结构 性能评估 数据挖掘 可解释性
📋 核心要点
- 现有LLM研究缺乏对模型结构与性能之间关系的系统性、数据驱动的分析,阻碍了模型优化。
- 论文构建大规模数据集,涵盖多种开源LLM结构及其性能,通过数据挖掘分析结构配置对性能的影响。
- 研究通过实验验证了不同结构选择对性能的影响,并利用可解释性技术佐证,为LLM优化提供数据驱动的指导。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域取得了显著成功,推动了重要的技术进步和创新。尽管模型规模和能力迅速增长,但关于结构配置如何影响性能的系统性、数据驱动的研究仍然稀缺。为了弥补这一差距,我们提出了一个大规模数据集,其中包含各种开源LLM结构及其在多个基准测试中的性能。利用该数据集,我们进行了一项系统的、数据挖掘驱动的分析,以验证和量化结构配置与性能之间的关系。我们的研究首先回顾了LLM的历史发展以及对未来潜在趋势的探索。然后,我们分析了各种结构选择如何影响跨基准测试的性能,并使用机制可解释性技术进一步证实了我们的发现。通过提供数据驱动的LLM优化见解,我们的工作旨在指导未来模型的有针对性的开发和应用。我们将会在https://huggingface.co/datasets/DX0369/LLM-Structure-Performance-Dataset 上发布我们的数据集。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)研究主要集中在模型规模的扩大和训练数据的增加上,而忽略了模型结构对性能的潜在影响。缺乏系统性的数据驱动分析,使得模型设计和优化缺乏理论指导,难以针对特定任务选择合适的模型结构。现有方法难以量化不同结构配置对性能的影响,阻碍了LLM的进一步发展。
核心思路:论文的核心思路是通过构建一个大规模的LLM结构-性能数据集,然后利用数据挖掘技术,系统地分析和量化不同结构配置对模型性能的影响。通过这种数据驱动的方法,可以揭示LLM结构与性能之间的内在关系,为未来的模型设计和优化提供指导。这种方法避免了主观猜测和经验主义,更加客观和科学。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:收集各种开源LLM的结构信息和在多个基准测试上的性能数据,构建大规模数据集。2) 数据预处理:对收集到的数据进行清洗、整理和标准化,确保数据的质量和一致性。3) 数据分析:利用数据挖掘技术,分析不同结构配置与模型性能之间的关系,例如,Transformer层数、注意力机制类型、激活函数等对性能的影响。4) 结果验证:使用机制可解释性技术,进一步验证数据分析的结果,确保结论的可靠性。
关键创新:该论文的关键创新在于构建了一个大规模的LLM结构-性能数据集,并利用数据挖掘技术对该数据集进行了系统性的分析。这是首次尝试通过数据驱动的方法来研究LLM结构与性能之间的关系,为LLM的研究提供了一个新的视角。与现有方法相比,该方法更加客观和科学,可以避免主观猜测和经验主义。
关键设计:数据集包含了多种开源LLM的结构信息,例如Transformer层数、注意力机制类型、激活函数等。性能数据则包括在多个基准测试上的结果,例如语言建模、文本分类、问答等。数据分析过程中,使用了多种数据挖掘技术,例如回归分析、聚类分析、关联规则挖掘等。同时,还使用了机制可解释性技术,例如注意力可视化、梯度分析等,来验证数据分析的结果。
🖼️ 关键图片
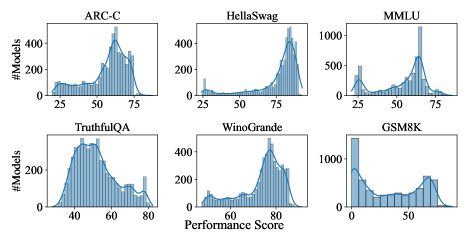
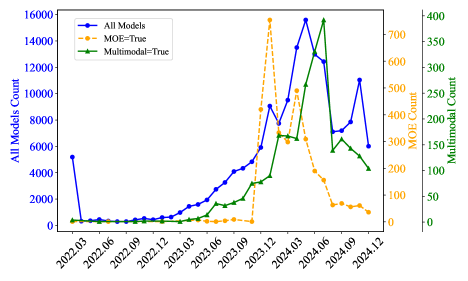

📊 实验亮点
该研究构建了一个大规模的LLM结构-性能数据集,涵盖多种开源LLM及其在多个基准测试上的性能。通过数据挖掘分析,揭示了模型结构对性能的显著影响,例如Transformer层数、注意力机制等。研究结果为LLM优化提供了数据驱动的指导,并利用可解释性技术验证了结论的可靠性。
🎯 应用场景
该研究成果可应用于指导未来LLM的设计和优化,帮助研究人员和工程师选择合适的模型结构,提高模型性能。此外,该数据集也可用于开发新的LLM评估指标和方法,促进LLM领域的进一步发展。该研究还有助于理解LLM内部的工作机制,为开发更智能、更可靠的LLM奠定基础。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable success across various domains, driving significant technological advancements and innovations. Despite the rapid growth in model scale and capability, systematic, data-driven research on how structural configurations affect performance remains scarce. To address this gap, we present a large-scale dataset encompassing diverse open-source LLM structures and their performance across multiple benchmarks. Leveraging this dataset, we conduct a systematic, data mining-driven analysis to validate and quantify the relationship between structural configurations and performance. Our study begins with a review of the historical development of LLMs and an exploration of potential future trends. We then analyze how various structural choices impact performance across benchmarks and further corroborate our findings using mechanistic interpretability techniques. By providing data-driven insights into LLM optimization, our work aims to guide the targeted development and application of future models. We will release our dataset at https://huggingface.co/datasets/DX0369/LLM-Structure-Performance-Dataset