Self-Evolving LLMs via Continual Instruction Tuning
作者: Jiazheng Kang, Le Huang, Cheng Hou, Zhe Zhao, Zhenxiang Yan, Ting Bai
分类: cs.LG, cs.AI
发布日期: 2025-09-14 (更新: 2025-10-15)
💡 一句话要点
提出MoE-CL框架,通过持续指令调优实现LLM在工业场景下的自进化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 指令调优 混合专家模型 对抗学习 参数高效 灾难性遗忘 工业应用
📋 核心要点
- 现有持续学习方法在LLM上应用时,容易发生灾难性遗忘,导致模型在新任务上训练后,在旧任务上的性能显著下降。
- MoE-CL框架采用双专家结构,包括任务专属专家和共享专家,并利用对抗学习,使共享专家学习泛化知识,专属专家保留任务细节。
- 在MTL5和Tencent3基准测试中,MoE-CL表现出色。在腾讯视频内容审核的A/B测试中,人工审核成本降低了15.3%。
📝 摘要(中文)
大型语言模型(LLM)需要在实际工业环境中不断学习,以适应多样化和不断演进的任务,这需要自进化来在动态数据分布下改进知识。然而,现有的持续学习(CL)方法,如重放和参数隔离,通常会遭受灾难性遗忘:在新任务上训练会因过度拟合新分布和削弱泛化能力而降低先前任务的性能。我们提出了MoE-CL,一个参数高效的对抗式混合专家框架,用于LLM的工业级、自进化持续指令调优。MoE-CL使用双专家设计:(1)每个任务一个专用的LoRA专家,通过参数独立性来保留特定于任务的知识,从而减轻遗忘;(2)一个共享的LoRA专家,以实现跨任务迁移。为了防止通过共享路径传递与任务无关的噪声,我们在GAN中集成了一个任务感知判别器。判别器鼓励共享专家在顺序训练期间仅传递任务对齐的信息。通过对抗学习,共享专家获得模仿判别器的广义表示,而专用专家保留特定于任务的细节,从而平衡知识保留和跨任务泛化,从而支持自进化。在公共MTL5基准和工业腾讯3基准上的大量实验验证了MoE-CL在持续指令调优方面的有效性。在腾讯视频平台上内容合规审查的实际A/B测试中,MoE-CL降低了15.3%的人工审查成本。这些结果表明,MoE-CL适用于大规模工业部署,其中持续适应和稳定迁移至关重要。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在工业场景下持续学习时遇到的灾难性遗忘问题。现有方法如重放和参数隔离,无法很好地平衡新知识学习和旧知识保留,导致模型在新任务上训练后,在旧任务上的表现急剧下降。
核心思路:论文的核心思路是利用混合专家模型(MoE)结合对抗学习,实现知识的有效保留和跨任务迁移。通过为每个任务分配专属专家,避免参数覆盖导致的遗忘;同时,利用共享专家学习通用知识,并通过对抗学习机制,确保共享专家传递的信息与当前任务相关,从而提高泛化能力。
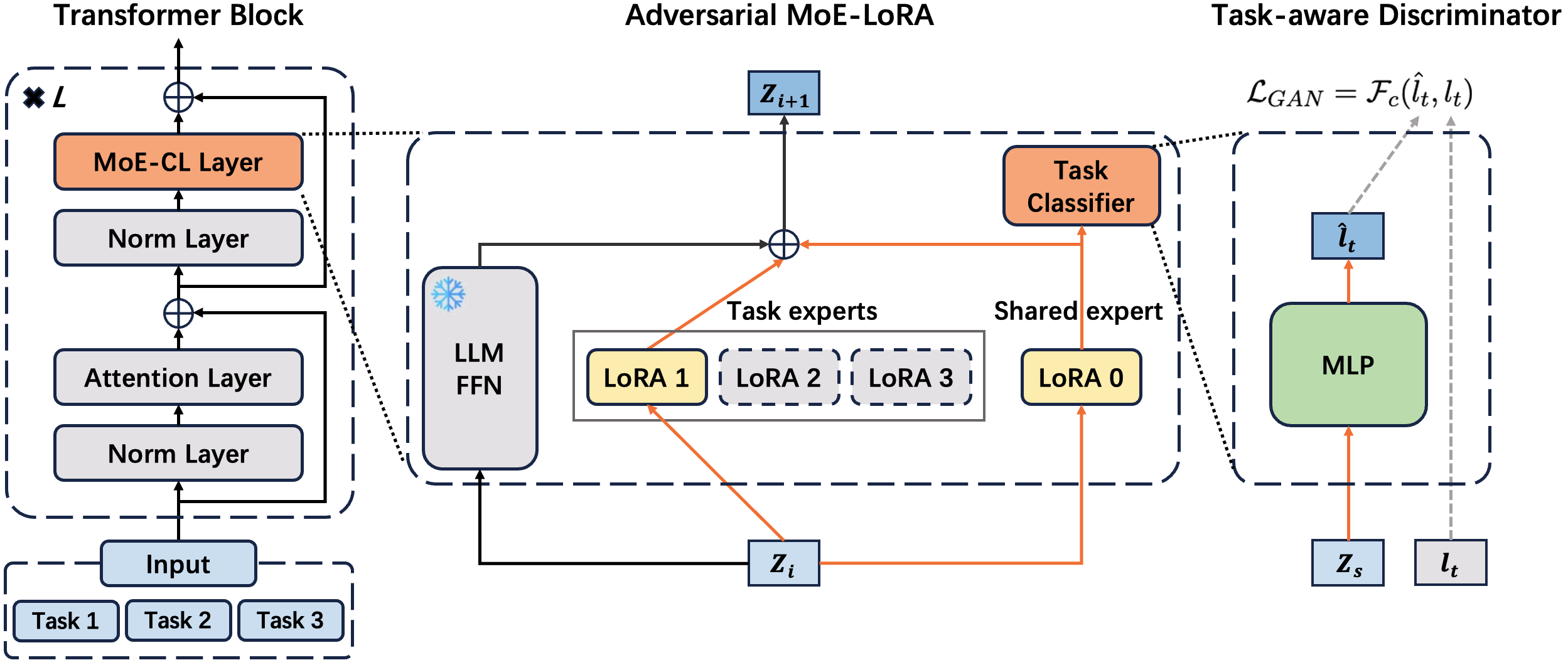
技术框架:MoE-CL框架包含以下主要模块:1) 任务专属LoRA专家:每个任务对应一个LoRA模块,负责存储该任务的特定知识。2) 共享LoRA专家:所有任务共享一个LoRA模块,负责学习跨任务的通用知识。3) 任务感知判别器:用于区分共享专家输出的信息是否与当前任务相关,并引导共享专家学习任务对齐的表示。训练过程采用对抗学习的方式,判别器努力区分信息来源,共享专家则努力生成能够欺骗判别器的信息。
关键创新:MoE-CL的关键创新在于将混合专家模型与对抗学习相结合,用于持续指令调优。通过任务专属专家和共享专家的协同工作,实现了知识保留和跨任务迁移的平衡。对抗学习机制能够有效过滤掉与任务无关的噪声,提高共享专家的泛化能力。
关键设计:MoE-CL的关键设计包括:1) LoRA的选择:LoRA是一种参数高效的微调方法,适合在大型语言模型上进行持续学习。2) 判别器的设计:判别器需要能够准确区分共享专家输出的信息是否与当前任务相关,其结构和训练方式对整体性能至关重要。3) 对抗学习的损失函数:需要精心设计损失函数,以平衡共享专家和判别器的训练,并确保共享专家能够学习到有用的通用知识。
🖼️ 关键图片
📊 实验亮点
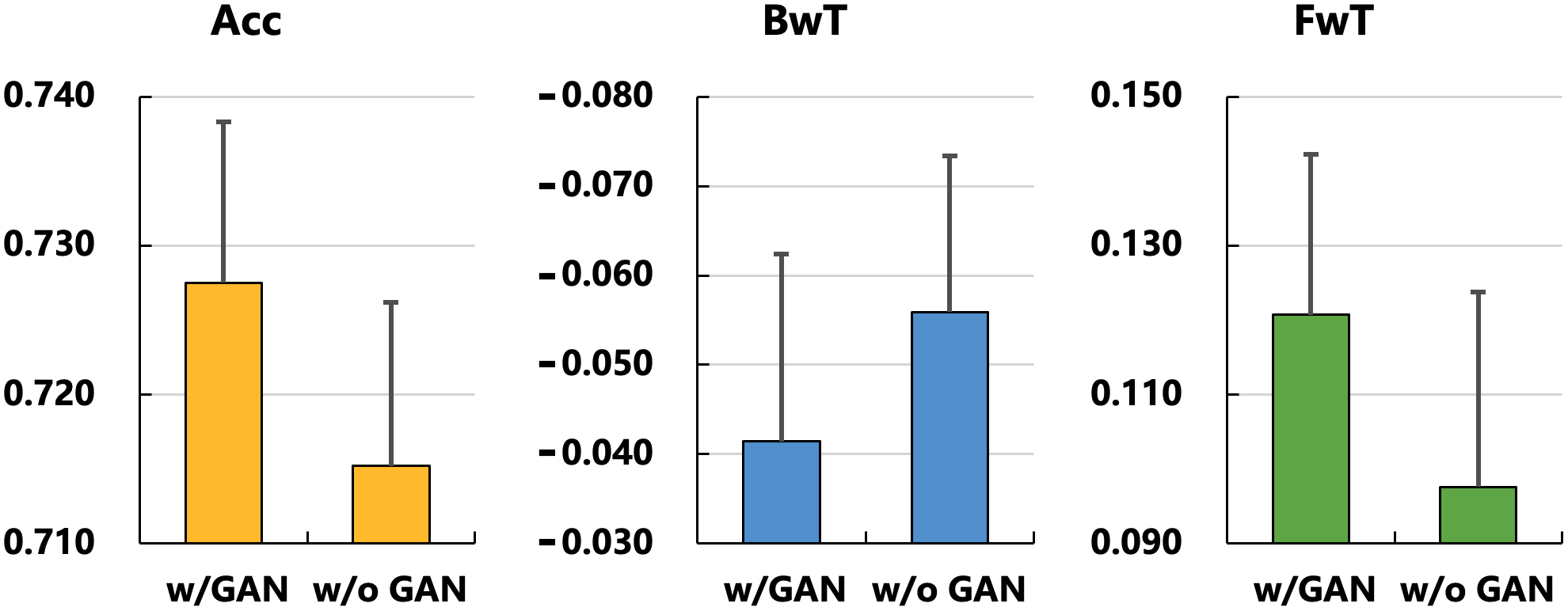
MoE-CL在MTL5和Tencent3基准测试中表现优于现有持续学习方法,验证了其有效性。在腾讯视频内容审核的实际A/B测试中,MoE-CL降低了15.3%的人工审核成本,证明了其在工业场景中的实用价值。这些结果表明,MoE-CL能够有效解决LLM在持续学习中遇到的灾难性遗忘问题,并实现知识的有效迁移。
🎯 应用场景
MoE-CL框架可应用于需要持续学习和适应的工业场景,例如智能客服、内容审核、金融风控等。通过不断学习新的数据和任务,模型可以保持最新的知识和技能,提高服务质量和效率。该方法尤其适用于数据分布不断变化的场景,可以有效降低人工干预成本。
📄 摘要(原文)
In real-world industrial settings, large language models (LLMs) must learn continually to keep pace with diverse and evolving tasks, requiring self-evolution to refine knowledge under dynamic data distributions. However, existing continual learning (CL) approaches, such as replay and parameter isolation, often suffer from catastrophic forgetting: training on new tasks degrades performance on earlier ones by overfitting to the new distribution and weakening generalization.We propose MoE-CL, a parameter-efficient adversarial mixture-of-experts framework for industrial-scale, self-evolving continual instruction tuning of LLMs. MoE-CL uses a dual-expert design: (1) a dedicated LoRA expert per task to preserve task-specific knowledge via parameter independence, mitigating forgetting; and (2) a shared LoRA expert to enable cross-task transfer. To prevent transferring task-irrelevant noise through the shared pathway, we integrate a task-aware discriminator within a GAN. The discriminator encourages the shared expert to pass only task-aligned information during sequential training. Through adversarial learning, the shared expert acquires generalized representations that mimic the discriminator, while dedicated experts retain task-specific details, balancing knowledge retention and cross-task generalization and thereby supporting self-evolution.Extensive experiments on the public MTL5 benchmark and an industrial Tencent3 benchmark validate the effectiveness of MoE-CL for continual instruction tuning. In real-world A/B testing for content compliance review on the Tencent Video platform, MoE-CL reduced manual review costs by 15.3%. These results demonstrate that MoE-CL is practical for large-scale industrial deployment where continual adaptation and stable transfer are critical.