Gradient Free Deep Reinforcement Learning With TabPFN
作者: David Schiff, Ofir Lindenbaum, Yonathan Efroni
分类: cs.LG, cs.AI
发布日期: 2025-09-14
💡 一句话要点
提出TabPFN RL,一种利用预训练Transformer进行免梯度深度强化学习的框架。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 免梯度强化学习 预训练Transformer 上下文学习 Q函数逼近 TabPFN
📋 核心要点
- 现有深度强化学习算法依赖梯度优化,对超参数敏感,训练不稳定,计算成本高昂。
- TabPFN RL利用预训练的Transformer TabPFN作为Q函数逼近器,通过上下文学习进行推理,无需梯度更新。
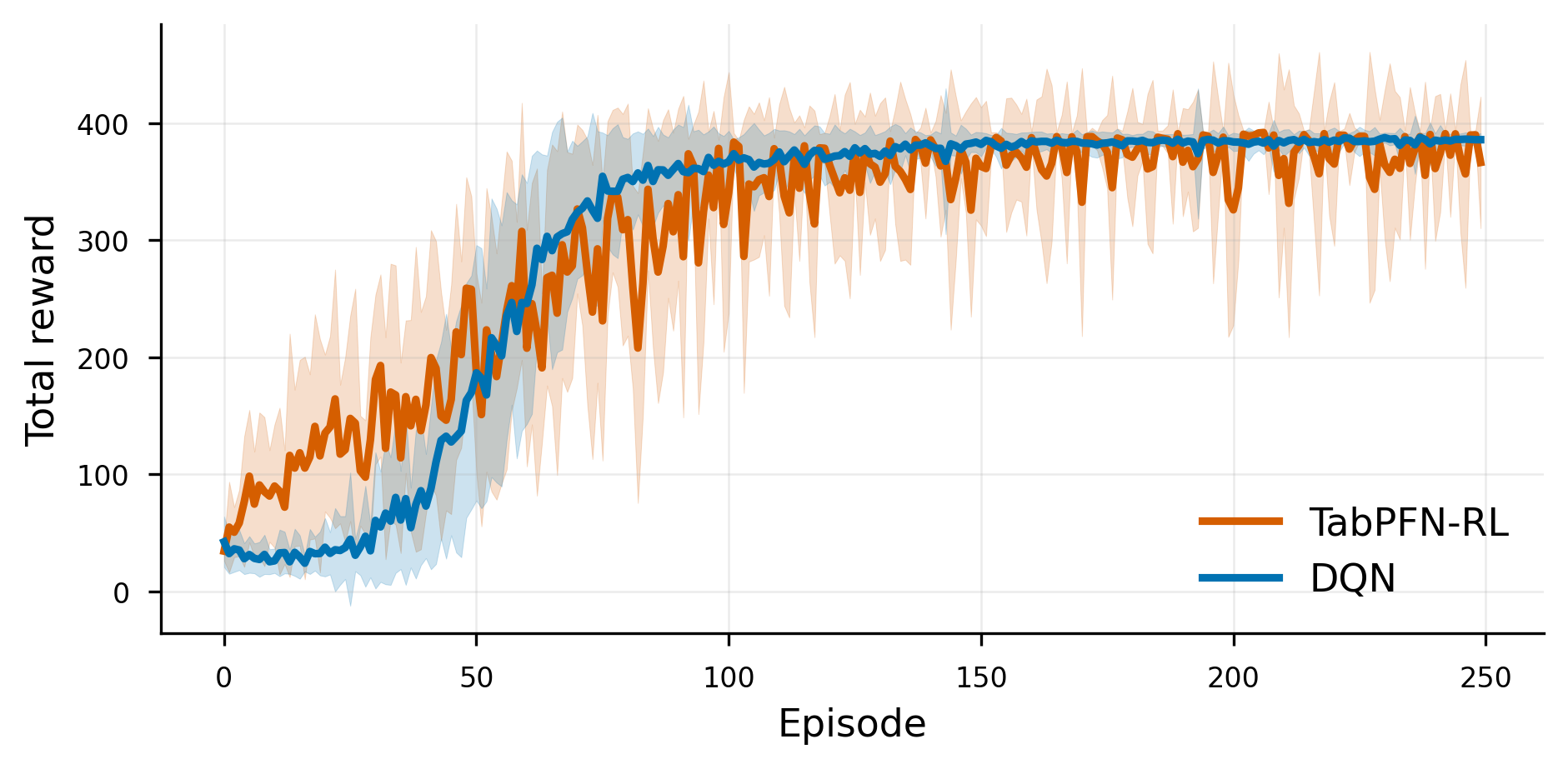
- 实验表明,TabPFN RL在经典控制任务上与DQN性能相当或更好,且无需梯度下降和超参数调优。
📝 摘要(中文)
本文提出TabPFN RL,一种新颖的免梯度深度强化学习框架,它将元训练Transformer TabPFN重新用作Q函数逼近器。TabPFN最初是为表格分类而开发的,是一个在数百万个合成数据集上预训练的Transformer,通过上下文学习对新的未见数据集执行推理。给定样本标签对的上下文数据集和新的未标记数据,它在单个前向传递中预测最可能的标签,而无需梯度更新或特定于任务的微调。我们使用TabPFN仅使用推理来预测Q值,从而消除了训练和推理时反向传播的需要。为了应对模型的固定上下文预算,我们设计了一个高奖励episode门,仅保留前5%的轨迹。在Gymnasium经典控制套件上的经验评估表明,TabPFN RL在CartPole v1、MountainCar v0和Acrobot v1上与Deep Q Network相匹配或超过,而无需应用梯度下降或任何广泛的超参数调整。我们讨论了自举目标和非平稳访问分布如何违反TabPFN先验中编码的独立性假设的理论方面,但该模型保留了令人惊讶的泛化能力。我们进一步形式化了上下文RL算法的内在上下文大小限制,并提出了在上下文已满时启用持续学习的原则性截断策略。我们的结果表明,诸如TabPFN之类的先前拟合网络是快速且计算高效的RL的可行基础,为使用大型预训练Transformer进行免梯度RL开辟了新的方向。
🔬 方法详解
问题定义:现有深度强化学习算法严重依赖于基于梯度的优化方法,这导致了对超参数的高度敏感性、不稳定的训练动态以及高昂的计算成本。这些问题限制了深度强化学习算法的实际应用和可扩展性。
核心思路:本文的核心思路是利用预训练的Transformer模型TabPFN,通过上下文学习的方式直接预测Q值,从而避免了梯度计算的需求。TabPFN在大量合成数据集上进行预训练,使其具备了强大的泛化能力,能够在新任务上快速进行推理。这种方法的核心在于将强化学习问题转化为一个上下文学习问题,利用预训练模型的先验知识来加速学习过程。
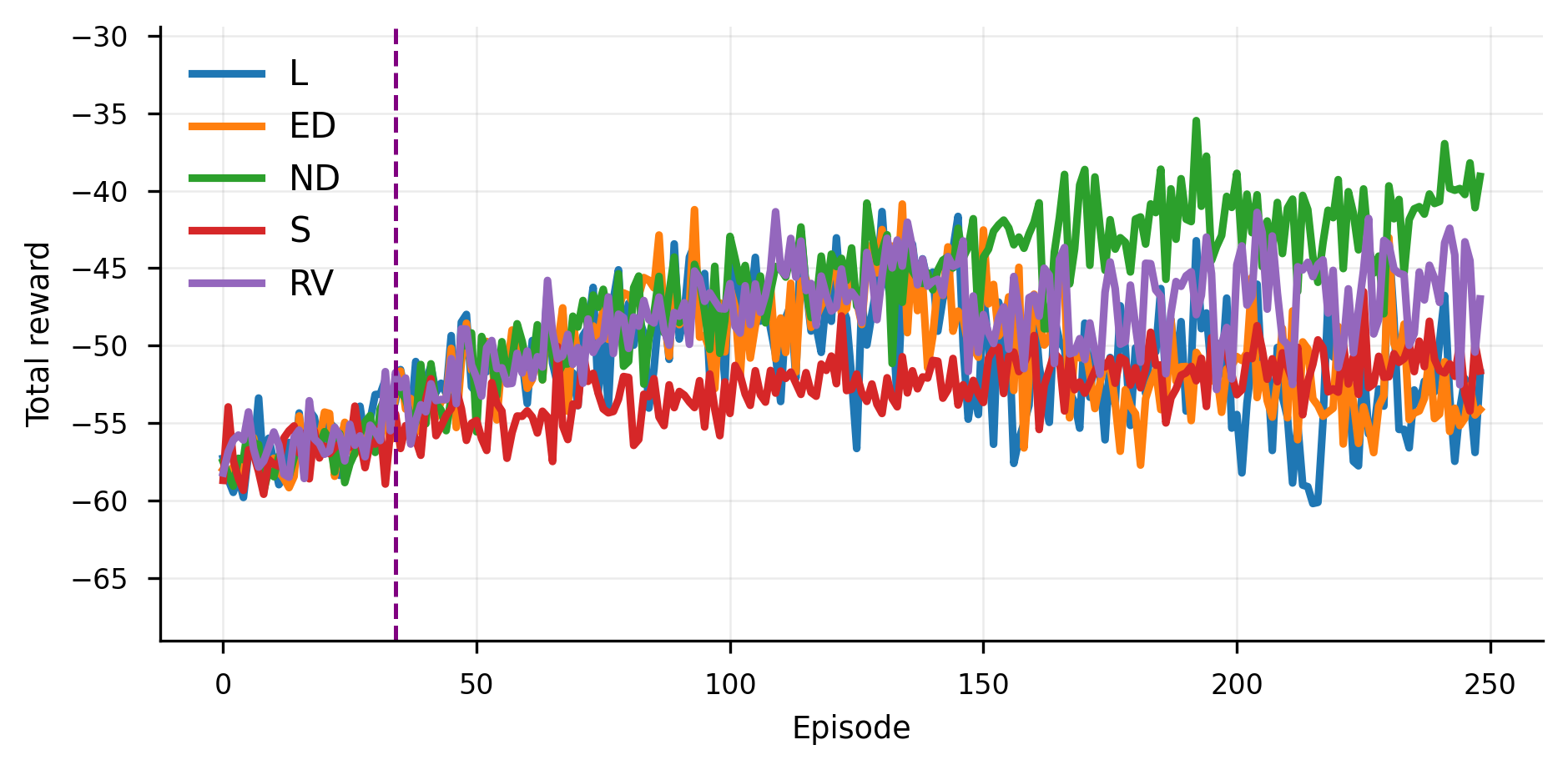
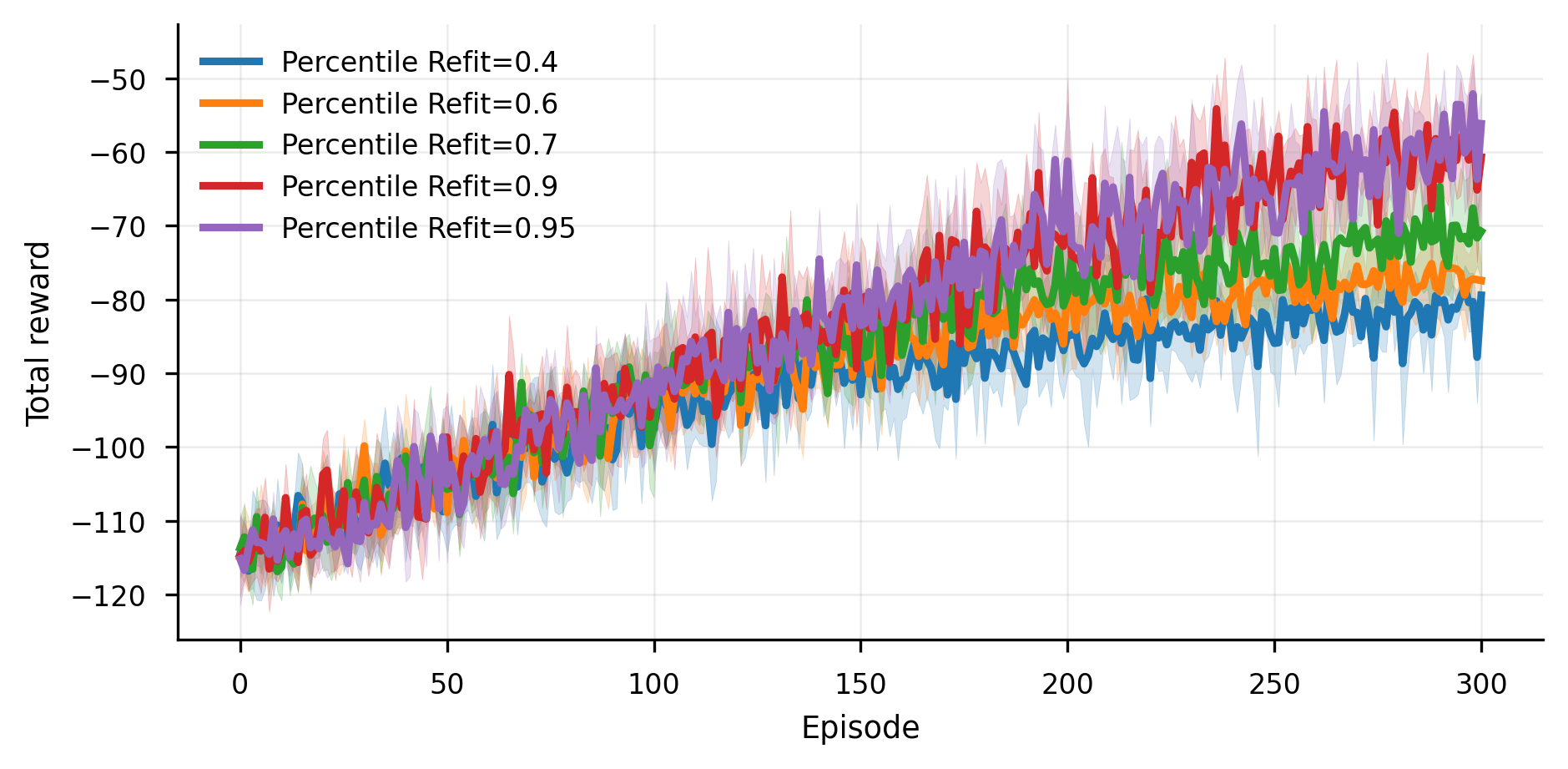
技术框架:TabPFN RL的整体框架包括以下几个主要步骤:1) 使用强化学习环境生成经验数据;2) 将经验数据整理成TabPFN可以接受的上下文格式,包括状态-动作对和对应的奖励;3) 使用TabPFN进行Q值预测,无需梯度更新;4) 根据预测的Q值选择动作,并与环境交互;5) 设计高奖励episode门,仅保留奖励最高的轨迹,以应对TabPFN的固定上下文预算。
关键创新:最重要的技术创新点在于将预训练的Transformer模型TabPFN应用于强化学习领域,并成功实现了免梯度的Q函数学习。与传统的基于梯度的强化学习算法相比,TabPFN RL无需进行反向传播,大大降低了计算成本,并提高了训练的稳定性。此外,论文还提出了针对上下文大小限制的截断策略,使得模型能够进行持续学习。
关键设计:TabPFN RL的关键设计包括:1) 使用TabPFN进行Q值预测,无需梯度更新;2) 设计高奖励episode门,仅保留前5%的轨迹,以应对TabPFN的固定上下文预算;3) 针对上下文大小限制,提出了原则性的截断策略,使得模型能够进行持续学习。这些设计使得TabPFN RL能够在经典控制任务上取得与DQN相当或更好的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TabPFN RL在Gymnasium经典控制套件的CartPole v1、MountainCar v0和Acrobot v1任务上,性能与Deep Q Network (DQN) 相匹配甚至超过,且无需梯度下降或任何广泛的超参数调整。这证明了预训练模型作为免梯度强化学习基础的可行性。
🎯 应用场景
TabPFN RL的潜在应用领域包括机器人控制、游戏AI、自动驾驶等。该研究的实际价值在于降低了强化学习算法的计算成本和超参数敏感性,使其更容易应用于实际场景。未来,该方法有望扩展到更复杂的强化学习任务中,并与其他预训练模型相结合,进一步提升性能。
📄 摘要(原文)
Gradient based optimization is fundamental to most modern deep reinforcement learning algorithms, however, it introduces significant sensitivity to hyperparameters, unstable training dynamics, and high computational costs. We propose TabPFN RL, a novel gradient free deep RL framework that repurposes the meta trained transformer TabPFN as a Q function approximator. Originally developed for tabular classification, TabPFN is a transformer pre trained on millions of synthetic datasets to perform inference on new unseen datasets via in context learning. Given an in context dataset of sample label pairs and new unlabeled data, it predicts the most likely labels in a single forward pass, without gradient updates or task specific fine tuning. We use TabPFN to predict Q values using inference only, thereby eliminating the need for back propagation at both training and inference. To cope with the model's fixed context budget, we design a high reward episode gate that retains only the top 5% of trajectories. Empirical evaluations on the Gymnasium classic control suite demonstrate that TabPFN RL matches or surpasses Deep Q Network on CartPole v1, MountainCar v0, and Acrobot v1, without applying gradient descent or any extensive hyperparameter tuning. We discuss the theoretical aspects of how bootstrapped targets and non stationary visitation distributions violate the independence assumptions encoded in TabPFN's prior, yet the model retains a surprising generalization capacity. We further formalize the intrinsic context size limit of in context RL algorithms and propose principled truncation strategies that enable continual learning when the context is full. Our results establish prior fitted networks such as TabPFN as a viable foundation for fast and computationally efficient RL, opening new directions for gradient free RL with large pre trained transformers.