Harnessing Optimization Dynamics for Curvature-Informed Model Merging
作者: Pouria Mahdavinia, Hamed Mahdavi, Niloofar Mireshghallah, Mehrdad Mahdavi
分类: cs.LG, cs.AI
发布日期: 2025-09-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出OTA+FFG,利用优化动态信息进行曲率感知的模型合并,提升SFT模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型合并 监督微调 优化轨迹 曲率感知 任务定位 二阶矩 大型语言模型
📋 核心要点
- 现有模型合并方法在整合多个SFT模型时,容易出现能力干扰和负迁移现象。
- 提出OTA合并,利用优化器二阶矩信息作为曲率代理,自适应调整参数权重,减少能力干扰。
- 引入FFG,通过曲率驱动的任务定位,稀疏化冲突或低重要性的参数编辑,进一步提升合并模型性能。
📝 摘要(中文)
模型合并是一种有效的后训练策略,用于在大型语言模型中组合多种能力,而无需联合重新训练。本文研究了监督微调(SFT)阶段的模型合并,其中多个基于能力的SFT检查点(涵盖数学、代码、精确指令遵循、通用指令遵循和知识回忆)必须合并到单个模型中。我们提出了优化轨迹感知(OTA)合并,这是一种曲率感知的聚合方法,它利用优化器的二阶矩统计量作为对角曲率代理来重新加权参数编辑并减轻干扰。作为OTA的补充,我们提出了快速Fisher嫁接(FFG),这是一种曲率驱动的任务定位步骤,可以稀疏化冲突或低重要性的编辑。FFG在早期注意力查询/键投影和token嵌入中诱导极低秩的掩码,从而利用跨能力的共享曲率。我们进一步开发了一种内存轻量级的二阶矩压缩方法,以保留OTA的效果。在各种基于能力的SFT检查点上,OTA+FFG改进了合并模型的质量,减少了负迁移,并且在各种稀疏度级别上保持稳健。分析表明,检查点之间存在大量的曲率重叠,这为简单的线性合并在实践中有效提供了一个新的视角。消融实验证实,FFG对于减少任务干扰至关重要,并且压缩的二阶矩保留了完整公式的增益。为了方便重现,我们在https://github.com/pmahdavi/ota-merge上开源了所有代码、训练和评估脚本、可视化工件以及特定于能力的SFT检查点。
🔬 方法详解
问题定义:论文旨在解决将多个经过监督微调(SFT)的语言模型合并为一个模型的问题,这些SFT模型各自擅长不同的任务(例如,数学、代码、指令遵循等)。现有模型合并方法,如简单的权重平均,容易导致不同任务之间的干扰,从而降低合并后模型的整体性能。这种干扰源于不同任务对模型参数的优化方向可能存在冲突。
核心思路:论文的核心思路是利用优化器在训练过程中产生的二阶矩统计量来估计模型参数空间的曲率。曲率信息可以反映参数对不同任务的重要性,并用于指导模型合并过程。通过对参数编辑进行重新加权,可以减轻任务之间的干扰,并保留各个SFT模型的优势。此外,通过稀疏化低重要性的参数编辑,可以进一步提高合并模型的效率和性能。
技术框架:整体框架包含两个主要模块:优化轨迹感知(OTA)合并和快速Fisher嫁接(FFG)。OTA合并首先利用优化器的二阶矩统计量作为对角曲率代理,对来自不同SFT模型的参数编辑进行重新加权,从而减少任务之间的干扰。然后,FFG利用曲率信息进行任务定位,稀疏化冲突或低重要性的编辑。最后,将经过OTA合并和FFG处理的参数进行合并,得到最终的合并模型。
关键创新:论文的关键创新在于将优化器的二阶矩统计量引入到模型合并过程中,并将其作为曲率的代理。这种方法能够更准确地估计参数对不同任务的重要性,从而实现更有效的模型合并。此外,FFG通过曲率驱动的任务定位,进一步提高了合并模型的性能。与现有方法相比,OTA+FFG能够更好地减少任务干扰,并保留各个SFT模型的优势。
关键设计:OTA合并的关键在于如何利用二阶矩统计量来计算参数的权重。论文使用对角曲率代理,并根据参数编辑的曲率值对其进行重新加权。FFG的关键在于如何确定需要稀疏化的参数。论文使用Fisher信息矩阵来估计参数的重要性,并根据重要性分数对参数进行排序和稀疏化。此外,论文还提出了一种内存轻量级的二阶矩压缩方法,以减少存储开销。
🖼️ 关键图片

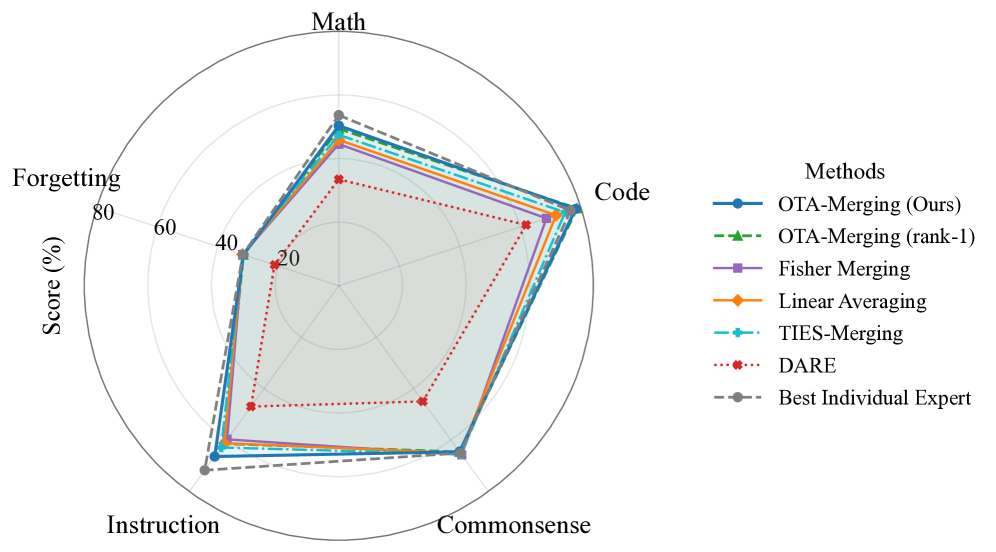
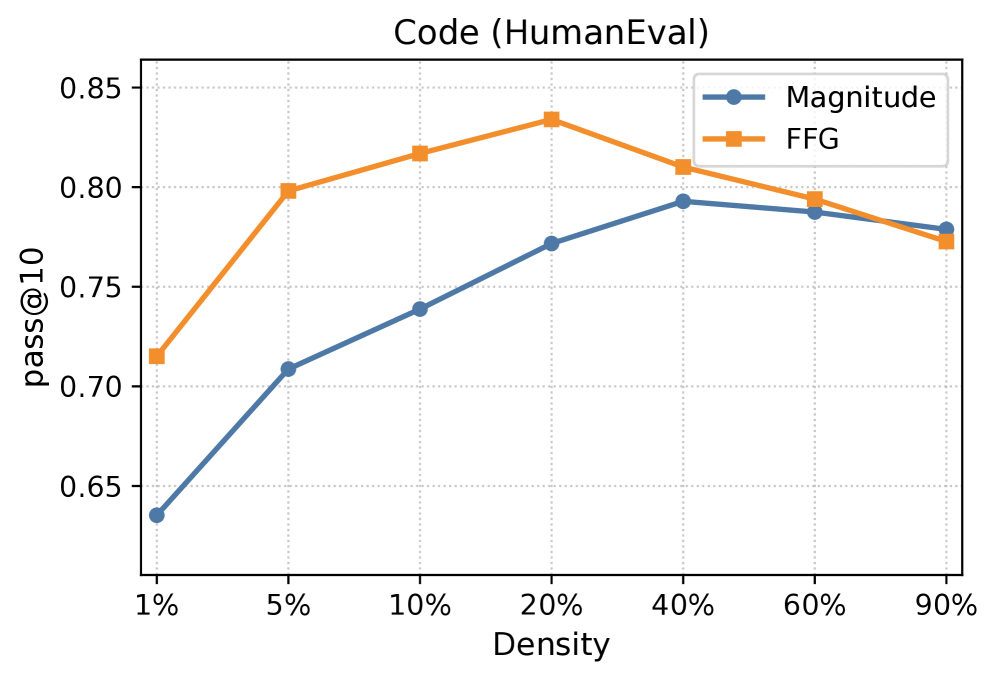
📊 实验亮点
实验结果表明,OTA+FFG在各种基于能力的SFT检查点上,显著提高了合并模型的质量,减少了负迁移,并且在各种稀疏度级别上保持稳健。消融实验证实,FFG对于减少任务干扰至关重要,并且压缩的二阶矩保留了完整公式的增益。分析还表明,检查点之间存在大量的曲率重叠,这为简单的线性合并在实践中有效提供了一个新的视角。
🎯 应用场景
该研究成果可应用于需要整合多个专业领域知识的大型语言模型。例如,可以将擅长不同编程语言的模型合并为一个更通用的代码生成模型,或者将擅长不同学科知识的模型合并为一个更全面的知识问答系统。该方法可以降低模型训练成本,提高模型性能,并促进多领域知识的融合。
📄 摘要(原文)
Model merging is an effective post-training strategy for composing capabilities in large language models without joint retraining. We study this in the supervised fine-tuning (SFT) stage, where multiple capability-based SFT checkpoints -- spanning math, code, precise instruction following, general instruction following, and knowledge recall -- must be consolidated into a single model. We introduce Optimization Trajectory Aware (OTA) Merging, a curvature-aware aggregation that leverages optimizer second-moment statistics as a diagonal curvature proxy to reweight parameter edits and mitigate interference. Complementing OTA, we propose Fast Fisher Grafting (FFG), a curvature-driven task-localization step that sparsifies conflicting or low-importance edits. FFG induces extremely low-rank masks concentrated in early attention query/key projections and token embeddings, exploiting shared curvature across capabilities. We further develop a memory-light compression of the second moments that preserves OTA's effect. Across diverse capability-based SFT checkpoints, OTA+FFG improves merged-model quality over strong weight-space baselines, reduces negative transfer, and remains robust across sparsity levels. Analyses reveal substantial curvature overlap between checkpoints, offering a novel lens on why simple linear merging can be effective in practice. Ablations confirm that FFG is critical for reducing task interference and that the compressed second moments retain the gains of the full formulation. To facilitate reproducibility, we open-source all code, training and evaluation scripts, visualization artifacts, and capability-specific SFT checkpoints at https://github.com/pmahdavi/ota-merge.