AQUA: Attention via QUery mAgnitudes for Memory and Compute Efficient Inference in LLMs
作者: Santhosh G S, Saurav Prakash, Balaraman Ravindran
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-14
💡 一句话要点
AQUA:通过查询幅度注意力机制,提升LLM推理的内存和计算效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 注意力机制 大型语言模型 推理加速 稀疏注意力 模型优化
📋 核心要点
- 现有注意力机制的二次复杂度限制了LLM处理长上下文的能力,成为计算和内存瓶颈。
- AQUA通过离线计算投影矩阵和在线动态选择维度子集,降低注意力计算复杂度。
- 实验表明,AQUA能在Llama-3.1-8B上减少25%的注意力计算量,且性能影响不显著。
📝 摘要(中文)
本文提出AQUA(Attention via QUery mAgnitudes),一种新颖且通用的近似策略,旨在显著降低注意力机制的计算成本,并实现性能上的平滑过渡。该方法包含两个阶段:首先,通过在校准数据集上进行SVD分解,离线计算出一个通用的、与语言无关的投影矩阵;然后,在在线推理阶段,投影查询和键向量,并根据查询的幅度动态选择一个稀疏的维度子集。论文对AQUA进行了形式化的理论分析,确定了其计算效率超过标准注意力的盈亏平衡点。在Llama-3.1-8B等先进模型上的实验评估表明,在对各种基准测试的性能影响微乎其微的情况下,可以实现注意力点积计算量减少25%。此外,AQUA还能够协同加速现有的token eviction方法(如H2O),并直接减少KV-cache的内存大小,从而体现了其通用性。AQUA提供了一个可控的旋钮来平衡效率和准确性,为大规模LLM推理提供了一个实用且强大的工具,使其更易于访问和可持续。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中注意力机制的二次复杂度问题。标准注意力机制的计算和内存需求随着序列长度的增加呈平方增长,这限制了LLM处理长上下文的能力,并成为推理效率的瓶颈。现有方法要么牺牲精度,要么引入额外的复杂性,难以在实际应用中取得理想的平衡。
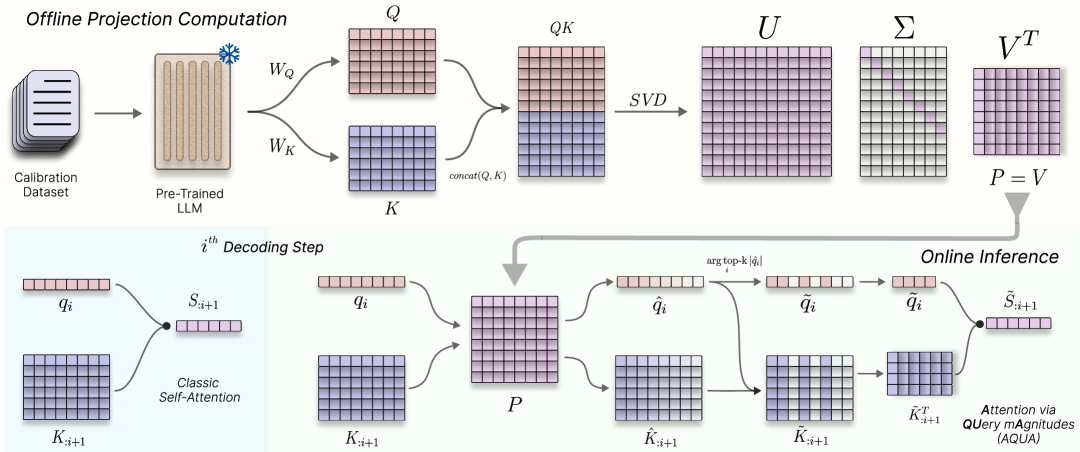
核心思路:AQUA的核心思路是利用查询向量的幅度(magnitude)来动态选择参与注意力计算的关键维度。通过离线学习一个通用的投影矩阵,将高维的查询和键向量投影到低维空间,并在在线推理时,根据查询向量的幅度选择重要的维度进行计算,从而实现稀疏注意力,降低计算复杂度。
技术框架:AQUA包含两个主要阶段:离线投影矩阵计算和在线稀疏注意力计算。在离线阶段,使用SVD分解在校准数据集上学习一个通用的投影矩阵。该矩阵旨在保留原始向量空间中的重要信息,并降低维度。在线推理阶段,首先使用离线学习的投影矩阵投影查询和键向量。然后,根据查询向量的幅度,动态选择一个稀疏的维度子集。最后,仅在选定的维度上执行注意力计算。
关键创新:AQUA的关键创新在于其动态维度选择机制,该机制基于查询向量的幅度自适应地选择参与计算的维度。与静态稀疏注意力方法相比,AQUA能够更好地保留重要信息,并实现更高的精度。此外,AQUA的离线投影矩阵学习方法使其能够应用于各种LLM,而无需针对特定模型进行微调。
关键设计:AQUA的关键设计包括:1) 使用SVD分解进行离线投影矩阵学习,确保投影矩阵能够保留原始向量空间中的重要信息;2) 基于查询向量幅度的动态维度选择机制,允许模型自适应地关注重要的维度;3) 可控的稀疏度参数,允许用户根据计算资源和精度需求调整稀疏度。
🖼️ 关键图片
📊 实验亮点
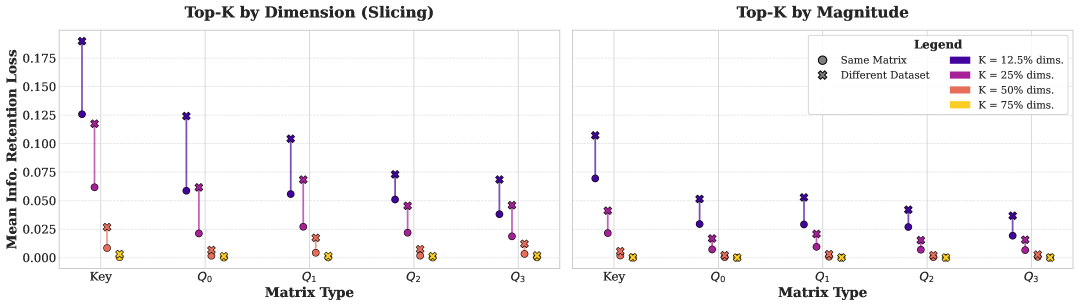
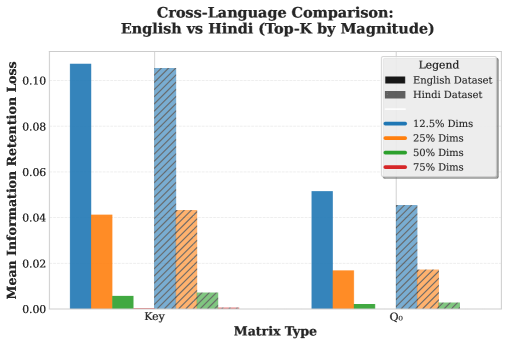
实验结果表明,AQUA能够在Llama-3.1-8B模型上实现25%的注意力点积计算量减少,而对各种基准测试的性能影响微乎其微。具体而言,在某些任务上,AQUA甚至可以提高模型的性能。此外,AQUA还能够协同加速现有的token eviction方法(如H2O),并直接减少KV-cache的内存大小。
🎯 应用场景
AQUA可应用于各种需要处理长序列的LLM应用场景,例如机器翻译、文本摘要、问答系统和对话生成。通过降低注意力计算的复杂度和内存需求,AQUA可以使LLM在资源受限的设备上运行,并提高大规模推理的效率。此外,AQUA还可以与其他优化技术(如token eviction)结合使用,进一步提高LLM的性能。
📄 摘要(原文)
The quadratic complexity of the attention mechanism remains a fundamental barrier to scaling Large Language Models (LLMs) to longer contexts, creating a critical bottleneck in both computation and memory. To address this, we introduce AQUA (Attention via QUery mAgnitudes) a novel and versatile approximation strategy that significantly reduces the cost of attention with a graceful performance trade-off. Our method operates in two phases: an efficient offline step where we compute a universal, language agnostic projection matrix via SVD on a calibration dataset, and an online inference step where we project query and key vectors and dynamically select a sparse subset of dimensions based on the query's magnitude. We provide a formal theoretical analysis of AQUA, establishing the break-even point at which it becomes more computationally efficient than standard attention. Our empirical evaluations on state-of-the-art models like Llama-3.1-8B demonstrate that a 25% reduction in the attention dot-product computation can be achieved with a statistically insignificant impact on performance across a wide range of benchmarks. We further showcase the versatility of AQUA by demonstrating its ability to synergistically accelerate existing token eviction methods like H2O and to directly reduce KV-cache memory size. By offering a controllable knob to balance efficiency and accuracy, AQUA provides a practical and powerful tool for making large-scale LLM inference more accessible and sustainable.