Why and How Auxiliary Tasks Improve JEPA Representations
作者: Jiacan Yu, Siyi Chen, Mingrui Liu, Nono Horiuchi, Vladimir Braverman, Zicheng Xu, Dan Haramati, Randall Balestriero
分类: cs.LG, cs.AI
发布日期: 2025-09-12 (更新: 2025-10-19)
💡 一句话要点
提出辅助任务提升JEPA表征质量的理论分析与实践方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联合嵌入预测架构 JEPA 辅助任务 表征学习 强化学习
📋 核心要点
- JEPA在视觉表征学习中应用广泛,但其内在机制尚不明确,存在表征坍塌的风险。
- 本文提出联合训练辅助回归头的JEPA变体,通过辅助任务锚定表征,避免不良表征坍塌。
- 实验表明,联合训练辅助头能够生成更丰富的表征,验证了理论分析的正确性。
📝 摘要(中文)
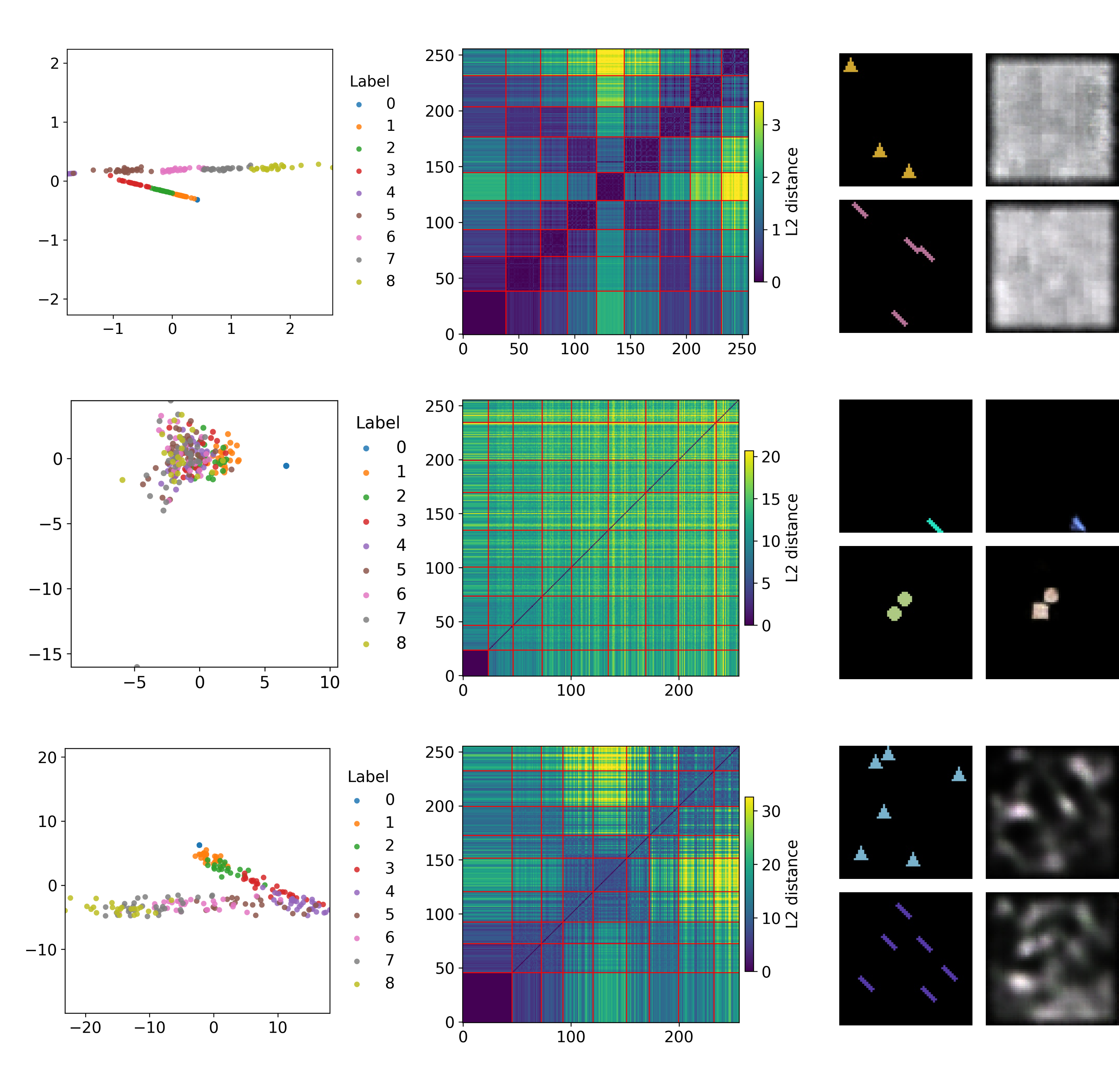
联合嵌入预测架构(JEPA)越来越多地应用于视觉表征学习和基于模型的强化学习中,但其行为仍未被充分理解。本文对一种简单实用的JEPA变体进行了理论分析,该变体具有与潜在动态联合训练的辅助回归头。我们证明了一个“无不良表征崩溃”定理:在确定性MDP中,如果训练使潜在转移一致性损失和辅助回归损失都趋于零,那么任何一对非等价的观测,即那些不具有相同转移动态或辅助值的观测,必须映射到不同的潜在表征。因此,辅助任务锚定了表征必须保留的区别。在计数环境中的受控消融实验证实了该理论,并表明与单独训练相比,将JEPA模型与辅助头联合训练可以生成更丰富的表征。我们的工作为改进JEPA编码器指明了一条道路:使用辅助函数对其进行训练,该辅助函数与转移动态一起编码正确的等价关系。
🔬 方法详解
问题定义:现有的JEPA模型在训练过程中,容易出现表征坍塌的问题,即不同的观测可能映射到相同的潜在表征,导致模型无法区分不同的状态。这限制了JEPA在视觉表征学习和强化学习中的应用。现有方法缺乏对JEPA表征能力的理论分析,难以指导模型设计和训练。
核心思路:本文的核心思路是引入辅助任务,通过辅助任务的监督信号来约束潜在表征的学习,从而避免表征坍塌。具体来说,本文提出了一种联合训练辅助回归头的JEPA变体,该辅助回归头预测与观测相关的辅助值。通过最小化辅助回归损失,模型被迫保留区分不同辅助值的观测所需的特征,从而避免了表征坍塌。
技术框架:该方法基于标准的JEPA框架,主要包括编码器、潜在转移模型和辅助回归头。编码器将观测映射到潜在表征,潜在转移模型预测下一个潜在表征,辅助回归头预测与当前观测相关的辅助值。整个框架通过联合训练来优化,目标是最小化潜在转移一致性损失和辅助回归损失。
关键创新:本文最重要的技术创新点在于提出了“无不良表征崩溃”定理,该定理证明了在确定性MDP中,如果训练使潜在转移一致性损失和辅助回归损失都趋于零,那么任何一对非等价的观测,即那些不具有相同转移动态或辅助值的观测,必须映射到不同的潜在表征。该定理为辅助任务如何提升JEPA表征质量提供了理论依据。
关键设计:关键设计包括辅助任务的选择和损失函数的设置。辅助任务需要与观测相关,并且能够提供有用的监督信号。辅助回归损失通常采用均方误差损失或交叉熵损失。此外,潜在转移一致性损失也需要仔细设计,以保证潜在转移模型的准确性。
🖼️ 关键图片
📊 实验亮点
在计数环境中的受控消融实验表明,与单独训练相比,将JEPA模型与辅助头联合训练可以生成更丰富的表征。实验结果验证了“无不良表征崩溃”定理的正确性,并表明辅助任务能够有效地提升JEPA模型的表征能力。
🎯 应用场景
该研究成果可应用于视觉表征学习、机器人控制和强化学习等领域。通过引入合适的辅助任务,可以提升JEPA模型的表征能力,使其能够更好地捕捉环境的动态特性,从而提高控制策略的性能。此外,该研究也为设计更有效的自监督学习算法提供了新的思路。
📄 摘要(原文)
Joint-Embedding Predictive Architecture (JEPA) is increasingly used for visual representation learning and as a component in model-based RL, but its behavior remains poorly understood. We provide a theoretical characterization of a simple, practical JEPA variant that has an auxiliary regression head trained jointly with latent dynamics. We prove a No Unhealthy Representation Collapse theorem: in deterministic MDPs, if training drives both the latent-transition consistency loss and the auxiliary regression loss to zero, then any pair of non-equivalent observations, i.e., those that do not have the same transition dynamics or auxiliary value, must map to distinct latent representations. Thus, the auxiliary task anchors which distinctions the representation must preserve. Controlled ablations in a counting environment corroborate the theory and show that training the JEPA model jointly with the auxiliary head generates a richer representation than training them separately. Our work indicates a path to improve JEPA encoders: training them with an auxiliary function that, together with the transition dynamics, encodes the right equivalence relations.