Neural Scaling Laws for Deep Regression
作者: Tilen Cadez, Kyoung-Min Kim
分类: cs.LG, cond-mat.other
发布日期: 2025-09-12 (更新: 2025-11-24)
备注: Supplementary Information will be provided with the published manuscript
💡 一句话要点
研究深度回归模型中的神经缩放律,揭示数据量与模型性能的幂律关系。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经缩放律 深度回归 模型容量 数据集大小 幂律关系
📋 核心要点
- 现有深度学习缩放律研究主要集中在分类任务,深度回归模型的缩放规律尚不明确。
- 本文通过实证研究,探索了深度回归模型中损失与数据集大小、模型容量之间的幂律关系。
- 实验结果表明,深度回归模型也存在显著的缩放效应,且性能提升潜力巨大。
📝 摘要(中文)
神经缩放律是深度学习模型泛化误差与模型特征之间幂律关系的体现,对于在有限资源下开发可靠模型至关重要。尽管大型语言模型的成功突显了这些定律的重要性,但它们在深度回归模型中的应用仍未得到充分探索。本文针对扭曲范德瓦尔斯磁体的参数估计模型,对深度回归中的神经缩放律进行了实证研究。我们观察到损失与训练数据集大小和模型容量之间存在幂律关系,涵盖了广泛的数值范围,并采用了各种架构,包括全连接网络、残差网络和视觉Transformer。此外,控制这些关系的缩放指数范围为1到2,具体数值取决于回归参数和模型细节。一致的缩放行为及其较大的缩放指数表明,随着数据量的增加,深度回归模型的性能可以得到显著提高。
🔬 方法详解
问题定义:论文旨在研究深度回归模型中的神经缩放律,即模型性能(通常用损失函数衡量)如何随着训练数据集大小和模型容量的变化而变化。现有研究主要集中在分类任务上,对深度回归模型的缩放规律缺乏深入理解,阻碍了资源受限情况下深度回归模型的有效开发和优化。
核心思路:论文的核心思路是通过大量的实验,观察深度回归模型的损失函数与训练数据量、模型参数量之间的关系。通过拟合这些关系,确定是否存在幂律关系,并分析幂律的指数。这种方法旨在揭示深度回归模型性能提升的内在机制,为模型设计和数据选择提供指导。
技术框架:论文采用实证研究的方法,主要流程如下:1) 选择一个具体的深度回归任务:扭曲范德瓦尔斯磁体的参数估计。2) 选择多种不同的网络架构:包括全连接网络、残差网络和视觉Transformer。3) 在不同的数据集大小和模型容量下训练这些模型。4) 记录模型的损失函数值。5) 分析损失函数值与数据集大小、模型容量之间的关系,拟合幂律曲线,确定缩放指数。
关键创新:论文的关键创新在于将神经缩放律的研究扩展到了深度回归模型,并证实了深度回归模型也存在显著的缩放效应。此外,论文还发现深度回归模型的缩放指数范围为1到2,表明增加数据量可以带来显著的性能提升。这为深度回归模型的优化提供了新的思路。
关键设计:论文的关键设计包括:1) 选择了扭曲范德瓦尔斯磁体的参数估计作为回归任务,该任务具有一定的复杂性和实际意义。2) 采用了多种不同的网络架构,以验证缩放律的普适性。3) 在足够大的数据集大小和模型容量范围内进行了实验,以确保能够观察到清晰的缩放效应。4) 使用了合适的损失函数(具体损失函数类型未知)来衡量模型的性能。
🖼️ 关键图片


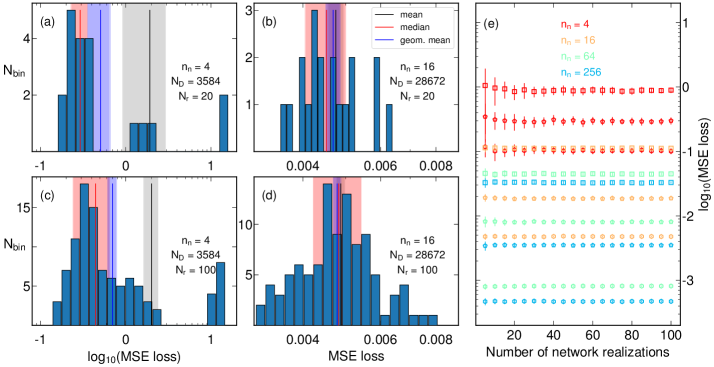
📊 实验亮点
实验结果表明,深度回归模型的损失与训练数据集大小和模型容量之间存在幂律关系,缩放指数范围为1到2。这意味着增加数据量可以带来显著的性能提升。例如,在特定模型和参数下,数据量翻倍可能使损失降低50%甚至更多(具体数值取决于缩放指数)。该结果为深度回归模型的优化提供了重要的理论依据。
🎯 应用场景
该研究成果可应用于各种需要深度回归模型的领域,例如物理参数预测、材料设计、金融预测等。通过理解深度回归模型的缩放律,可以更有效地利用有限的计算资源和数据资源,设计出性能更优的回归模型。此外,该研究还可以指导数据增强策略,提高模型的泛化能力。
📄 摘要(原文)
Neural scaling laws--power-law relationships between generalization errors and characteristics of deep learning models--are vital tools for developing reliable models while managing limited resources. Although the success of large language models highlights the importance of these laws, their application to deep regression models remains largely unexplored. Here, we empirically investigate neural scaling laws in deep regression using a parameter estimation model for twisted van der Waals magnets. We observe power-law relationships between the loss and both training dataset size and model capacity across a wide range of values, employing various architectures--including fully connected networks, residual networks, and vision transformers. Furthermore, the scaling exponents governing these relationships range from 1 to 2, with specific values depending on the regressed parameters and model details. The consistent scaling behaviors and their large scaling exponents suggest that the performance of deep regression models can improve substantially with increasing data size.