LoFT: Parameter-Efficient Fine-Tuning for Long-tailed Semi-Supervised Learning in Open-World Scenarios
作者: Zhiyuan Huang, Jiahao Chen, Yurou Liu, Bing Su
分类: cs.LG, cs.CV
发布日期: 2025-09-12 (更新: 2025-10-02)
💡 一句话要点
提出LoFT框架,通过高效参数微调解决开放世界长尾半监督学习问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长尾学习 半监督学习 开放世界 参数高效微调 伪标签
📋 核心要点
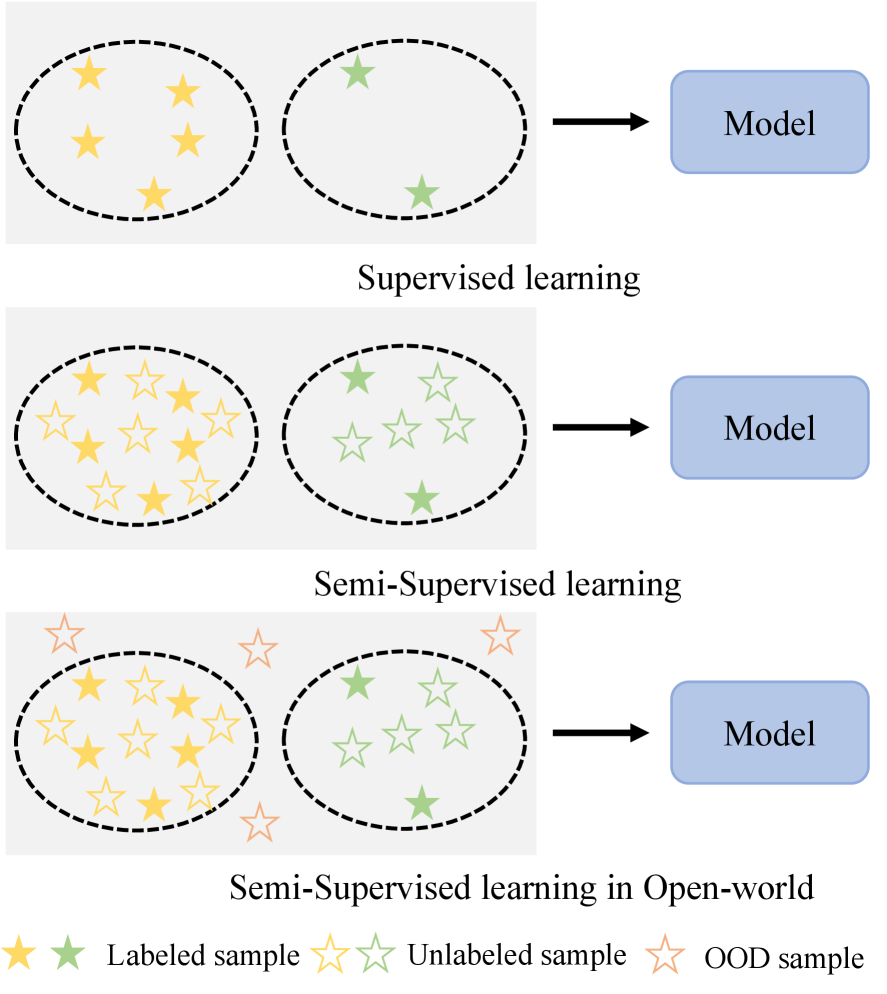
- 现有长尾半监督学习方法从头训练模型,易导致过拟合和伪标签质量低。
- LoFT框架通过高效参数微调基础模型,生成更可靠的伪标签,提升不平衡学习效果。
- LoFT-OW解决开放世界场景下的分布外样本问题,实验证明性能优于现有方法。
📝 摘要(中文)
长尾学习因其在现实场景中的广泛适用性而备受关注。在现有方法中,长尾半监督学习(LTSSL)通过将大量未标记数据纳入不平衡的标记数据集,成为一种有效的解决方案。然而,大多数先前的LTSSL方法旨在从头开始训练模型,这通常会导致过度自信和低质量伪标签等问题。为了应对这些挑战,我们将LTSSL扩展到基础模型微调范式,并提出了一个新颖的框架:LoFT(通过高效参数微调进行长尾半监督学习)。我们证明,微调的基础模型可以生成更可靠的伪标签,从而有利于不平衡学习。此外,我们通过研究开放世界条件下的半监督学习,探索了一种更实用的设置,其中未标记的数据可能包含分布外(OOD)样本。为了解决这个问题,我们提出了LoFT-OW(开放世界场景下的LoFT)来提高判别能力。在多个基准上的实验结果表明,与以前的方法相比,我们的方法取得了优异的性能,即使只使用了以前工作1%的未标记数据。
🔬 方法详解
问题定义:论文旨在解决开放世界场景下长尾半监督学习的问题。现有LTSSL方法通常从头训练模型,这在数据不平衡的情况下容易导致模型过拟合,并且生成的伪标签质量不高,影响模型的泛化能力。此外,现实场景中未标记数据往往包含分布外(OOD)样本,进一步加剧了学习难度。
核心思路:论文的核心思路是利用预训练的foundation model强大的表征能力,通过参数高效的微调(parameter-efficient fine-tuning)方式,避免从头训练带来的问题。微调后的模型能够生成更准确的伪标签,从而提升长尾数据的学习效果。同时,针对开放世界场景,设计相应的机制来处理OOD样本。
技术框架:LoFT框架主要包含两个阶段:首先,利用预训练的foundation model对标记数据进行微调,得到一个初步的模型。然后,利用该模型对未标记数据生成伪标签,并结合标记数据进行进一步的训练。对于开放世界场景,LoFT-OW框架在生成伪标签的过程中,会引入OOD检测机制,过滤掉置信度较低或被判定为OOD的样本,从而避免噪声数据对模型训练的干扰。
关键创新:论文的关键创新在于将parameter-efficient fine-tuning引入到长尾半监督学习中,并针对开放世界场景设计了相应的OOD处理机制。与从头训练相比,微调能够更好地利用预训练模型的知识,提高伪标签的质量和模型的泛化能力。同时,OOD检测机制能够有效降低噪声数据的影响,提升模型在复杂场景下的鲁棒性。
关键设计:论文采用了一种parameter-efficient的微调方法,具体细节未知。对于OOD检测,可能采用基于置信度的阈值过滤,或者训练一个额外的OOD检测器。损失函数方面,可能采用交叉熵损失函数结合伪标签损失函数,并根据类别数量进行加权,以平衡长尾数据的影响。具体网络结构取决于所使用的预训练模型。
🖼️ 关键图片
📊 实验亮点
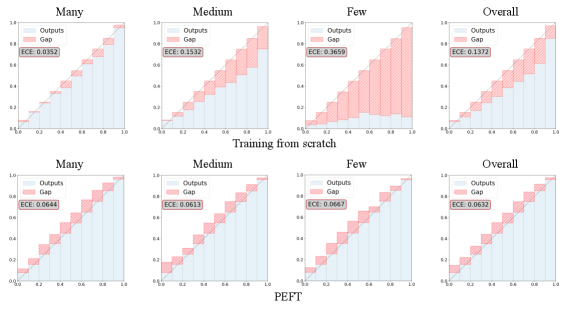
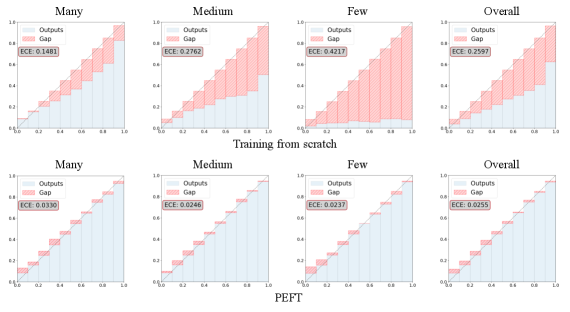
实验结果表明,LoFT框架在多个长尾半监督学习基准数据集上取得了显著的性能提升,即使只使用少量未标记数据(例如1%),也能超越之前的state-of-the-art方法。LoFT-OW框架在开放世界场景下也表现出优异的性能,证明了其对OOD样本的鲁棒性。
🎯 应用场景
该研究成果可应用于图像识别、目标检测、自然语言处理等领域,尤其是在数据分布不平衡且存在大量未标注数据的场景下,例如医疗诊断、自动驾驶、社交媒体分析等。通过利用预训练模型和高效微调策略,可以显著降低模型训练成本,提高模型在复杂环境下的性能和泛化能力。
📄 摘要(原文)
Long-tailed learning has garnered increasing attention due to its wide applicability in real-world scenarios. Among existing approaches, Long-Tailed Semi-Supervised Learning (LTSSL) has emerged as an effective solution by incorporating a large amount of unlabeled data into the imbalanced labeled dataset. However, most prior LTSSL methods are designed to train models from scratch, which often leads to issues such as overconfidence and low-quality pseudo-labels. To address these challenges, we extend LTSSL into the foundation model fine-tuning paradigm and propose a novel framework: LoFT (Long-tailed semi-supervised learning via parameter-efficient Fine-Tuning). We demonstrate that fine-tuned foundation models can generate more reliable pseudolabels, thereby benefiting imbalanced learning. Furthermore, we explore a more practical setting by investigating semi-supervised learning under open-world conditions, where the unlabeled data may include out-of-distribution (OOD) samples. To handle this problem, we propose LoFT-OW (LoFT under Open-World scenarios) to improve the discriminative ability. Experimental results on multiple benchmarks demonstrate that our method achieves superior performance compared to previous approaches, even when utilizing only 1\% of the unlabeled data compared with previous works.