Meta-Learning Reinforcement Learning for Crypto-Return Prediction
作者: Junqiao Wang, Zhaoyang Guan, Guanyu Liu, Tianze Xia, Xianzhi Li, Shuo Yin, Xinyuan Song, Chuhan Cheng, Tianyu Shi, Alex Lee
分类: cs.LG, cs.AI
发布日期: 2025-09-11 (更新: 2026-02-01)
💡 一句话要点
提出Meta-RL-Crypto,用于加密货币回报预测的自改进交易Agent
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 加密货币预测 元学习 强化学习 Transformer 自我改进 交易Agent 多模态输入
📋 核心要点
- 加密货币回报预测受多种因素影响,数据稀缺,传统方法难以有效应对快速变化的市场环境。
- Meta-RL-Crypto结合元学习和强化学习,通过Actor、Judge和Meta-Judge的迭代,实现Agent的自我改进。
- 实验表明,Meta-RL-Crypto在真实市场中表现良好,优于其他基于LLM的基线方法,具有实际应用潜力。
📝 摘要(中文)
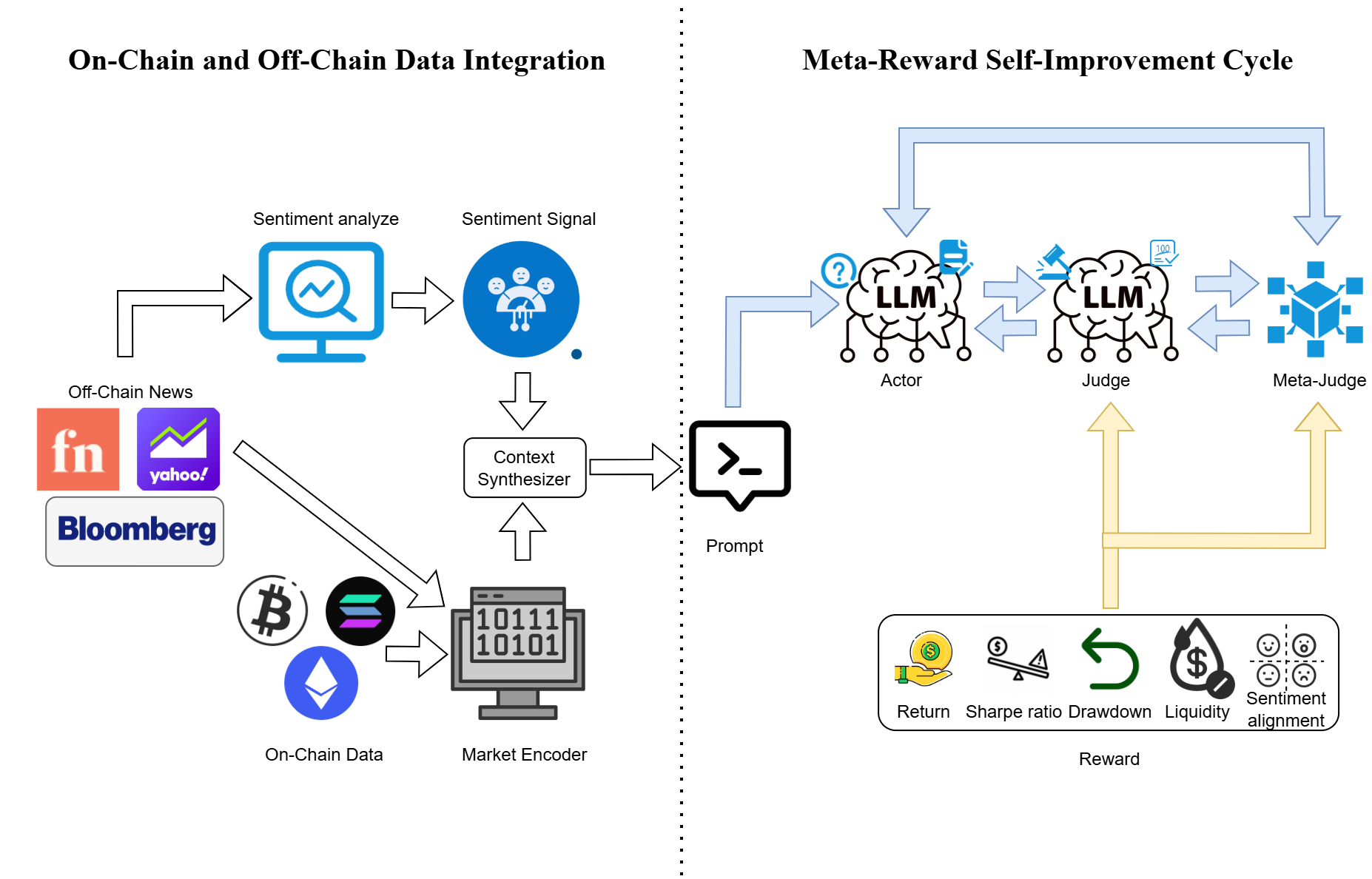
预测加密货币回报非常困难,价格波动受到快速变化的市场活动、新闻和社交情绪的影响,同时标记的训练数据稀缺且昂贵。本文提出Meta-RL-Crypto,一个统一的基于Transformer的架构,它结合了元学习和强化学习(RL),以创建一个完全自我改进的交易Agent。从一个简单的指令调优LLM开始,Agent在一个闭环架构中迭代地在三个角色(Actor、Judge和Meta-Judge)之间切换。这个学习过程不需要额外的人工监督,它可以利用多模态市场输入和内部偏好反馈。系统中的Agent不断改进交易策略和评估标准。在不同市场机制下的实验表明,Meta-RL-Crypto在真实市场的技术指标上表现良好,并且优于其他基于LLM的基线。
🔬 方法详解
问题定义:论文旨在解决加密货币回报预测的难题。现有方法难以有效利用多模态市场信息,且缺乏足够的标记数据进行训练,导致预测精度不高,难以适应快速变化的市场环境。现有基于LLM的方法也难以持续改进交易策略和评估标准。
核心思路:论文的核心思路是结合元学习和强化学习,构建一个能够自我改进的交易Agent。通过元学习,Agent能够快速适应不同的市场环境;通过强化学习,Agent能够根据市场反馈不断优化交易策略。这种结合使得Agent能够在数据稀缺的情况下,实现高性能的加密货币回报预测。
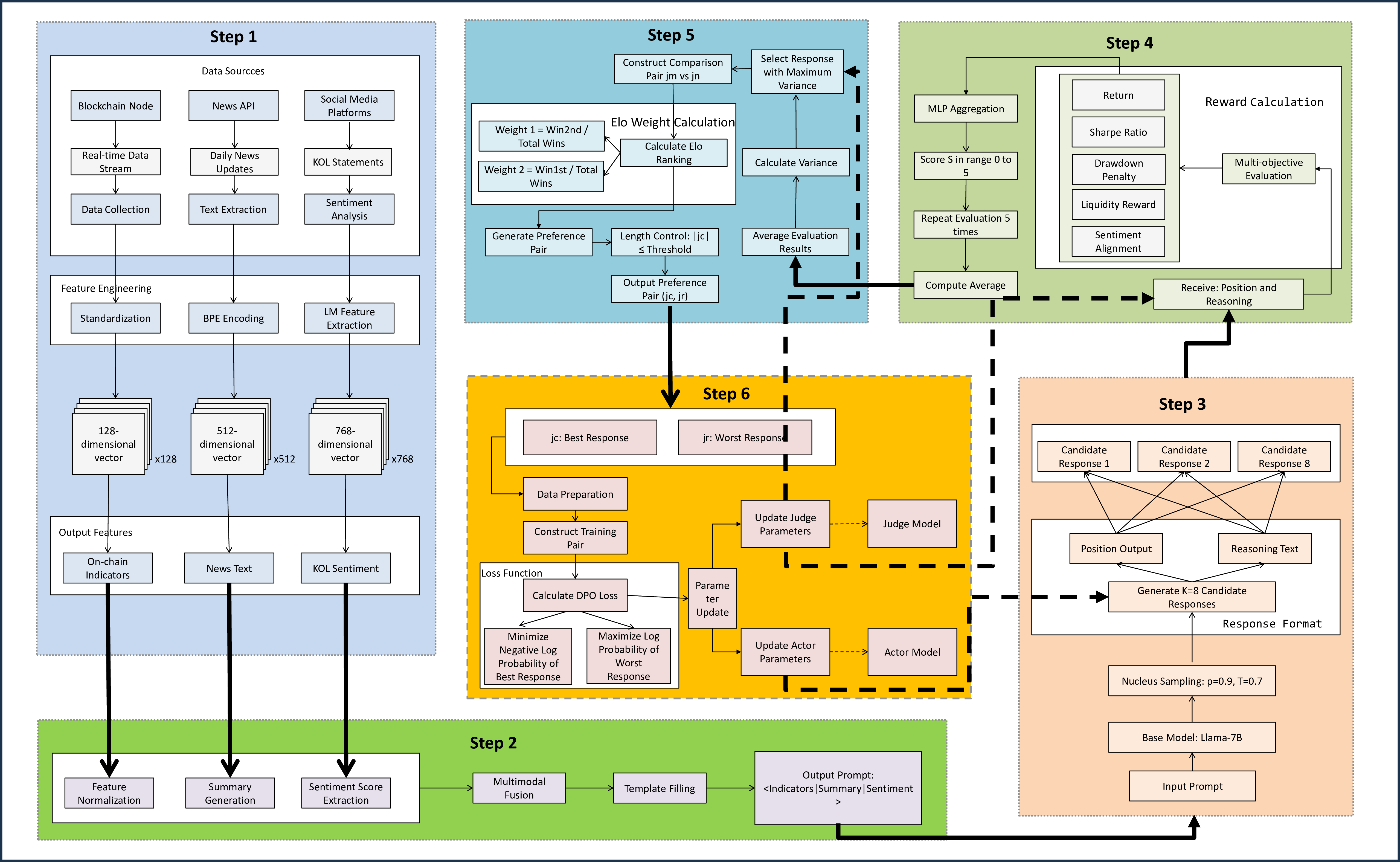
技术框架:Meta-RL-Crypto采用一个闭环架构,包含三个主要模块:Actor、Judge和Meta-Judge。Actor负责执行交易策略,Judge负责评估Actor的表现,Meta-Judge负责改进Judge的评估标准。Agent从一个指令调优的LLM开始,通过不断迭代这三个模块,实现自我改进。系统可以利用多模态市场输入(例如,链上活动、新闻和社交情绪)和内部偏好反馈。
关键创新:该方法最重要的创新点在于将元学习和强化学习结合,并设计了一个闭环的自我改进架构。传统的强化学习方法需要大量的人工监督和标记数据,而Meta-RL-Crypto通过元学习,减少了对人工监督的依赖,并能够快速适应新的市场环境。此外,Meta-Judge模块能够不断改进评估标准,使得Agent能够更好地理解市场动态。
关键设计:论文中没有详细描述关键参数设置、损失函数和网络结构等技术细节。Transformer架构是基础,但具体如何针对加密货币预测进行优化,以及Actor、Judge和Meta-Judge的具体实现方式(例如,损失函数的设计、网络结构的选取)未知。指令调优的LLM作为初始模型,其具体选择和调优策略也未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Meta-RL-Crypto在真实市场的技术指标上表现良好,并且优于其他基于LLM的基线方法。具体的性能数据和提升幅度在摘要中没有明确给出,需要查阅论文全文才能获取更详细的信息。但总体而言,该方法在加密货币回报预测方面展现了良好的潜力。
🎯 应用场景
Meta-RL-Crypto可应用于自动化加密货币交易、风险管理和投资组合优化等领域。该研究的实际价值在于降低了加密货币交易的门槛,提高了交易效率和盈利能力。未来,该方法可以扩展到其他金融市场,为投资者提供更智能的交易工具。
📄 摘要(原文)
Predicting cryptocurrency returns is notoriously difficult: price movements are driven by a fast-shifting blend of on-chain activity, news flow, and social sentiment, while labeled training data are scarce and expensive. In this paper, we present Meta-RL-Crypto, a unified transformer-based architecture that unifies meta-learning and reinforcement learning (RL) to create a fully self-improving trading agent. Starting from a vanilla instruction-tuned LLM, the agent iteratively alternates between three roles-actor, judge, and meta-judge-in a closed-loop architecture. This learning process requires no additional human supervision. It can leverage multimodal market inputs and internal preference feedback. The agent in the system continuously refines both the trading policy and evaluation criteria. Experiments across diverse market regimes demonstrate that Meta-RL-Crypto shows good performance on the technical indicators of the real market and outperforming other LLM-based baselines.