Clip Your Sequences Fairly: Enforcing Length Fairness for Sequence-Level RL
作者: Hanyi Mao, Quanjia Xiao, Lei Pang, Haixiao Liu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-11 (更新: 2025-10-13)
💡 一句话要点
提出FSPO,通过长度公平裁剪解决序列级强化学习中的长度偏差问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 序列级强化学习 长度公平性 重要性采样 大型语言模型 策略优化
📋 核心要点
- 现有序列级强化学习方法在处理长短序列时存在偏差,固定裁剪范围导致对不同长度序列的非公平加权。
- FSPO通过引入与序列长度平方根成比例的裁剪范围,实现了对不同长度序列的公平处理,避免了优化方向的扭曲。
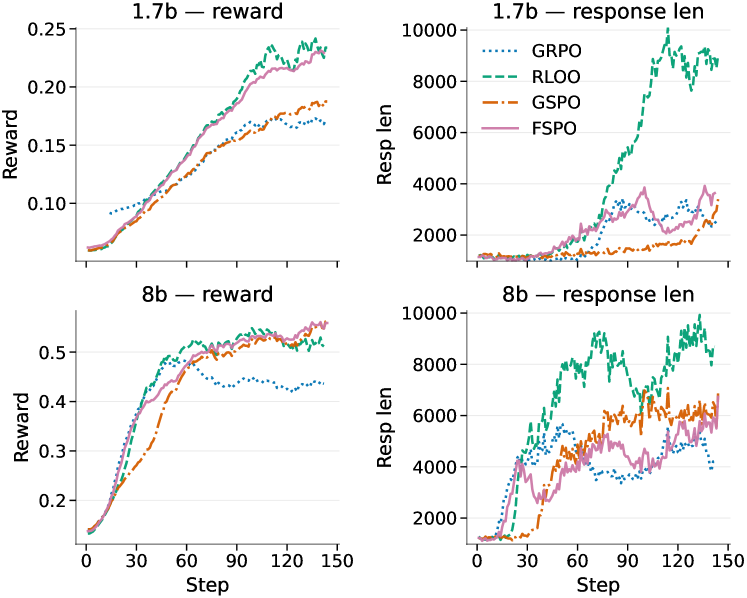
- 实验表明,FSPO能够有效降低长度偏差,稳定训练过程,并在多个数据集和模型上显著优于现有基线方法。
📝 摘要(中文)
本文提出了一种用于大型语言模型的序列级强化学习方法FSPO(Fair Sequence Policy Optimization),该方法对重要性采样(IS)权重强制执行长度公平裁剪。研究发现,当PPO/GRPO风格的裁剪被移植到序列时,会产生不匹配:固定的裁剪范围系统性地重新加权短响应与长响应,从而扭曲优化方向。FSPO引入了一个简单的补救措施:使用随$\sqrt{L}$缩放的带裁剪序列log-IS比率。理论上,通过长度重加权误差(LRE)形式化了长度公平性,并证明了小的LRE产生裁剪更新和真实更新之间的余弦方向保证。实验结果表明,FSPO在不同长度范围内实现了更平坦的裁剪率,稳定了训练,并在各种模型大小和评估数据集上优于基线,在Qwen3-8B-Base模型上获得了最大的收益。
🔬 方法详解
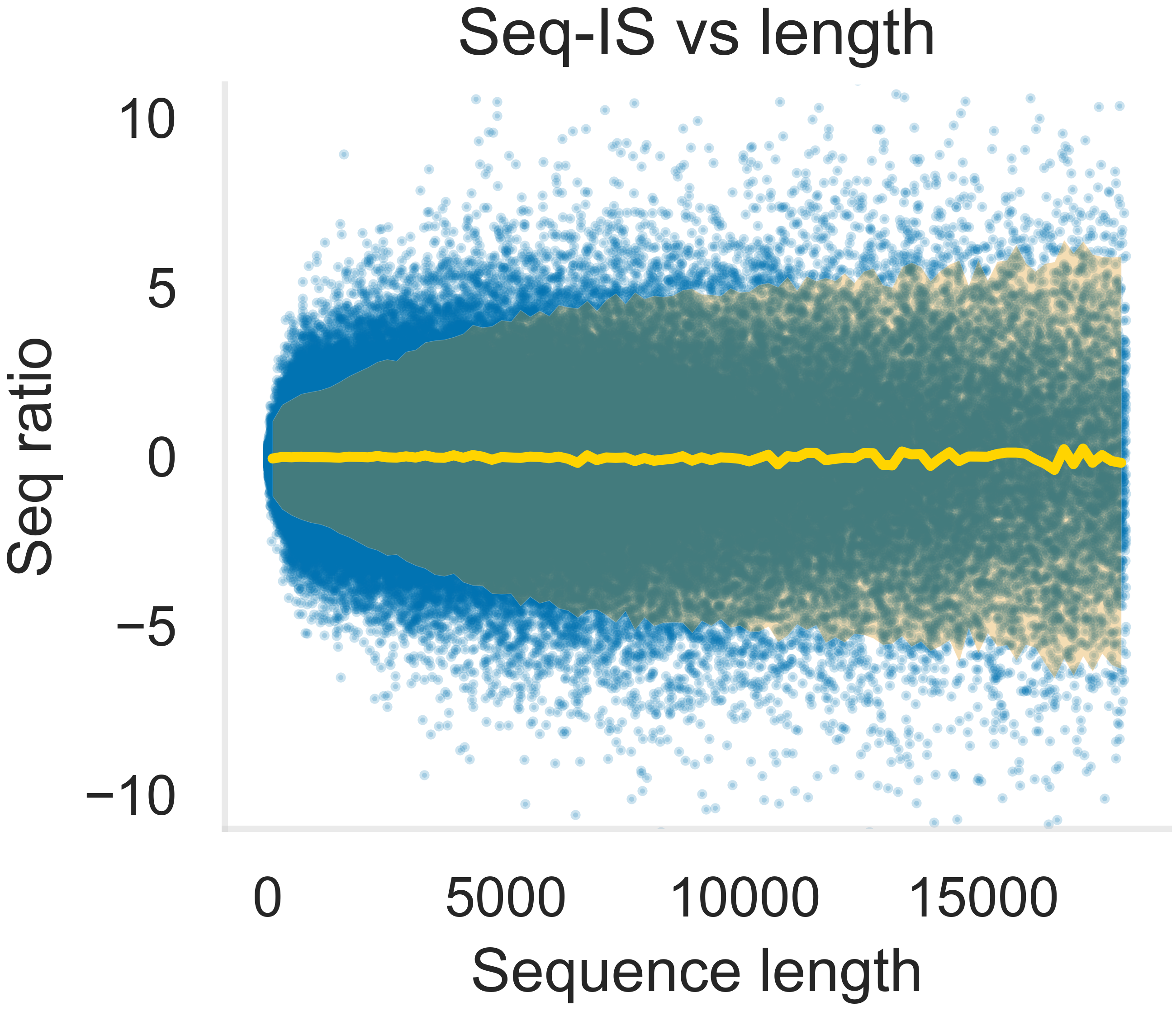
问题定义:序列级强化学习旨在优化生成文本的整体质量,但直接将PPO/GRPO等方法应用于序列时,会遇到长度偏差问题。具体来说,这些方法使用固定的裁剪范围来限制重要性采样权重,这导致短序列和长序列受到不同程度的限制。由于长序列通常具有更大的重要性采样权重变化范围,因此固定裁剪范围会不成比例地影响长序列,从而扭曲优化方向,导致模型偏向于生成特定长度的序列。
核心思路:FSPO的核心思路是引入长度公平裁剪,即裁剪范围与序列长度相关。具体而言,FSPO使用一个与序列长度的平方根成比例的裁剪范围。这样做的目的是确保无论序列长度如何,重要性采样权重都受到相似程度的限制,从而避免了对特定长度序列的过度惩罚或奖励。这种长度公平的裁剪策略能够更准确地反映序列的真实价值,从而引导模型学习生成更符合期望的序列。
技术框架:FSPO的整体框架与标准的序列级强化学习方法类似,包括以下几个主要步骤:1) 使用策略网络生成序列;2) 使用奖励函数评估生成的序列;3) 计算重要性采样权重;4) 使用长度公平裁剪策略调整重要性采样权重;5) 使用调整后的重要性采样权重更新策略网络。关键在于第4步,即长度公平裁剪策略的引入,它替代了传统的固定裁剪范围。
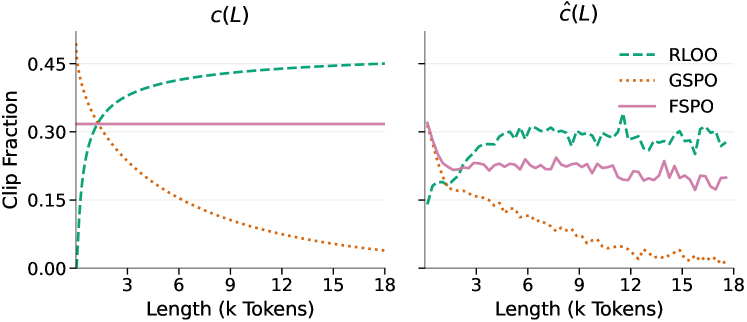
关键创新:FSPO最关键的创新在于提出了长度公平裁剪的概念,并将其应用于序列级强化学习。与传统的固定裁剪范围相比,长度公平裁剪能够更好地处理不同长度序列之间的差异,避免了长度偏差问题。此外,论文还从理论上分析了长度公平裁剪的有效性,并提出了长度重加权误差(LRE)来衡量长度公平性。
关键设计:FSPO的关键设计在于裁剪范围的计算方式。论文建议使用与序列长度的平方根成比例的裁剪范围,即$\sqrt{L}$。具体而言,对于序列长度为L的序列,其重要性采样权重的裁剪范围为$[1 - c\sqrt{L}, 1 + c\sqrt{L}]$,其中c是一个超参数,用于控制裁剪的强度。此外,论文还定义了长度重加权误差(LRE)来衡量长度公平性,并证明了小的LRE能够保证裁剪更新和真实更新之间的余弦方向一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FSPO在多个数据集和模型上均优于基线方法。例如,在Qwen3-8B-Base模型上,FSPO取得了显著的性能提升。此外,FSPO还能够有效降低不同长度序列的裁剪率差异,从而验证了其长度公平性。实验结果表明,FSPO能够稳定训练过程,并生成更高质量的序列。
🎯 应用场景
FSPO可应用于各种需要序列生成的任务,例如文本摘要、机器翻译、对话生成等。通过减少长度偏差,FSPO能够帮助模型生成更自然、更符合人类偏好的序列。该方法在大型语言模型微调领域具有重要价值,可以提升生成文本的质量和多样性,并有望应用于智能客服、内容创作等实际场景。
📄 摘要(原文)
We propose FSPO (Fair Sequence Policy Optimization), a sequence-level reinforcement learning method for LLMs that enforces length-fair clipping on the importance-sampling (IS) weight. We study RL methods with sequence-level IS and identify a mismatch when PPO/GRPO-style clipping is transplanted to sequences: a fixed clip range systematically reweights short vs. long responses, distorting the optimization direction. FSPO introduces a simple remedy: we clip the sequence log-IS ratio with a band that scales as $\sqrt{L}$. Theoretically, we formalize length fairness via a Length Reweighting Error (LRE) and prove that small LRE yields a cosine directional guarantee between the clipped and true updates. Empirically, FSPO flattens clip rates across length bins, stabilizes training, and outperforms baselines across model sizes and evaluation datasets, with the largest gains on the Qwen3-8B-Base model.