Quantum-Enhanced Forecasting for Deep Reinforcement Learning in Algorithmic Trading
作者: Jun-Hao Chen, Yu-Chien Huang, Yun-Cheng Tsai, Samuel Yen-Chi Chen
分类: cs.LG, cs.CY
发布日期: 2025-09-11 (更新: 2025-09-12)
💡 一句话要点
提出基于量子增强深度强化学习的算法交易方法,实现外汇交易回报率提升。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子计算 深度强化学习 算法交易 时间序列预测 金融市场
📋 核心要点
- 传统算法交易模型难以有效捕捉金融市场中的复杂非线性关系,限制了交易回报。
- 论文提出一种基于量子增强深度强化学习的交易代理,利用QLSTM进行趋势预测,QA3C进行交易决策。
- 实验结果表明,该模型在美元/新台币交易中实现了优于传统货币ETF的回报率,验证了方法的有效性。
📝 摘要(中文)
本文探索了量子启发神经网络与深度强化学习在金融交易中的融合应用。作者构建了一个美元/新台币的交易代理,该代理集成了量子长短期记忆网络(QLSTM)用于短期趋势预测,以及量子异步优势行动者-评论家算法(QA3C),这是一种经典A3C算法的量子增强变体。该模型在2000-01-01至2025-04-30的数据上进行训练(80%训练,20%测试),长线做多策略实现了约5年内11.87%的回报率,最大回撤为0.92%,优于几种货币ETF。文章详细介绍了状态设计(QLSTM特征和指标)、趋势跟踪/风险控制的奖励函数以及多核训练。结果表明,混合模型能够实现具有竞争力的外汇交易性能。研究表明QLSTM在具有严格风险控制的小利润交易中有效,并提出了未来的改进方向。关键超参数包括:QLSTM序列长度=4,QA3C工作线程=8。局限性包括:经典量子模拟和简化的交易策略。
🔬 方法详解
问题定义:论文旨在解决外汇算法交易中,如何更有效地利用历史数据预测短期趋势,并在此基础上制定优化的交易策略的问题。现有方法,如传统的统计模型和经典深度学习模型,在捕捉金融市场中的复杂非线性关系方面存在局限性,难以实现稳定的超额收益。
核心思路:论文的核心思路是结合量子计算的优势,增强深度强化学习模型的能力。具体而言,利用量子长短期记忆网络(QLSTM)来提取时间序列数据中的复杂模式,并使用量子异步优势行动者-评论家算法(QA3C)来优化交易策略。这种混合方法旨在利用量子计算的潜力,提高模型对市场动态的适应性和预测精度。
技术框架:整体框架包含两个主要模块:QLSTM趋势预测模块和QA3C交易决策模块。首先,QLSTM模块接收历史市场数据(包括价格、成交量等)作为输入,预测短期价格趋势。然后,QA3C模块基于QLSTM的预测结果,结合当前市场状态(例如,持仓情况、风险指标等),做出买入、卖出或持有的决策。QA3C采用多线程异步训练方式,加速模型收敛。
关键创新:论文的关键创新在于将量子计算的思想引入到深度强化学习框架中,具体体现在QLSTM和QA3C两个模块的设计上。QLSTM利用量子门操作来增强LSTM网络的表达能力,使其能够更好地捕捉时间序列数据中的复杂关系。QA3C则通过量子化的方式改进了A3C算法,提高了探索效率和训练速度。
关键设计:QLSTM的关键设计包括量子门的选取和网络结构的优化,序列长度设置为4。QA3C的关键设计包括奖励函数的设计(考虑趋势跟踪和风险控制),以及多线程异步训练的参数设置(工作线程数为8)。奖励函数的设计旨在鼓励模型跟踪市场趋势的同时,控制交易风险。此外,论文还详细描述了状态空间的设计,包括QLSTM的输出特征和常用的技术指标。
🖼️ 关键图片

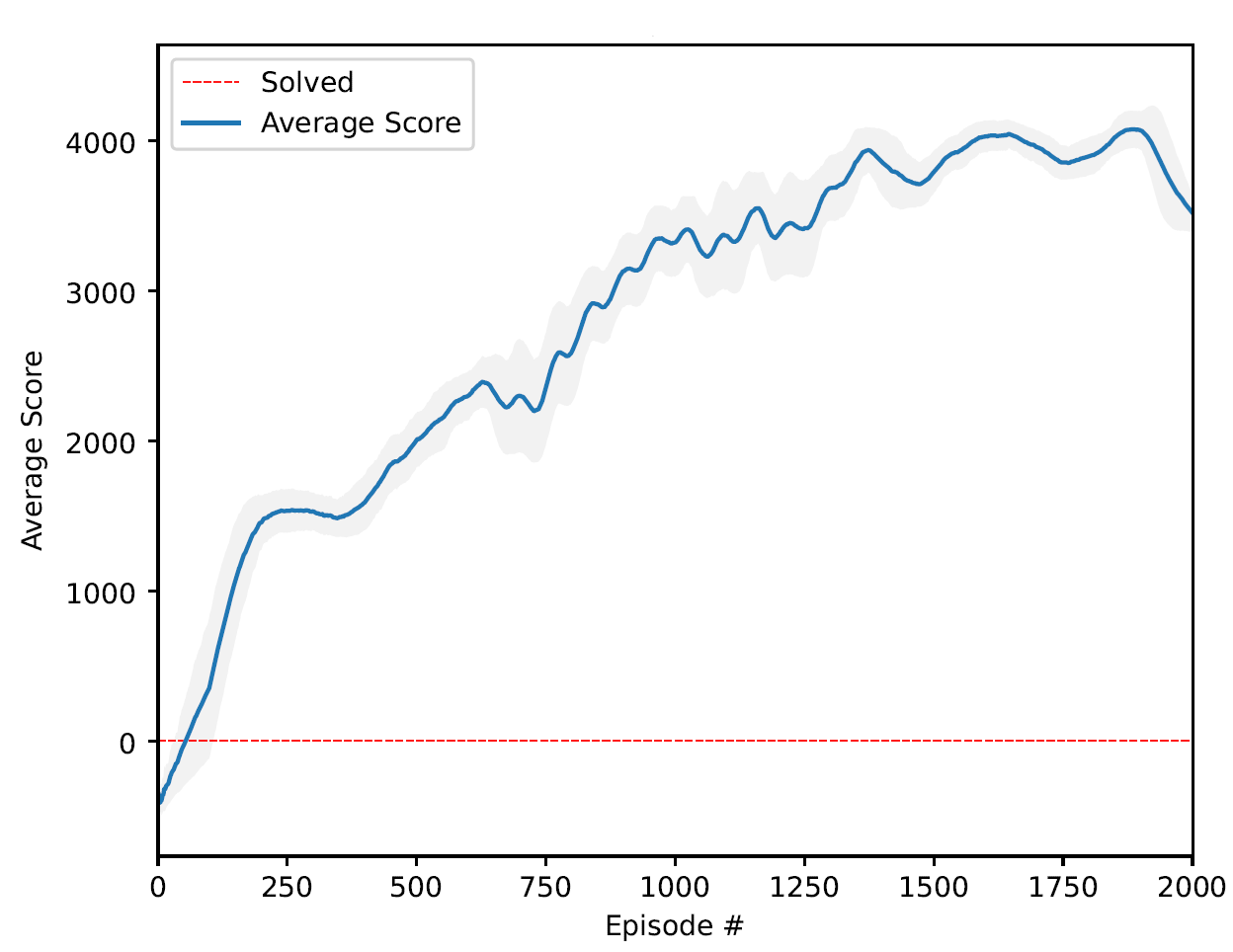
📊 实验亮点
实验结果表明,基于QLSTM和QA3C的交易代理在美元/新台币交易中取得了显著的回报。在2000-01-01至2025-04-30的数据上进行训练和测试,该模型实现了11.87%的总回报率,最大回撤为0.92%,优于几种货币ETF。这表明量子增强的深度强化学习方法在金融交易中具有潜力。
🎯 应用场景
该研究成果可应用于量化交易、风险管理和金融预测等领域。通过量子增强的深度强化学习模型,可以更有效地进行外汇、股票等金融资产的交易,提高投资回报率并降低风险。此外,该方法还可以扩展到其他需要时间序列预测和决策优化的领域,如能源管理、供应链优化等。
📄 摘要(原文)
The convergence of quantum-inspired neural networks and deep reinforcement learning offers a promising avenue for financial trading. We implemented a trading agent for USD/TWD by integrating Quantum Long Short-Term Memory (QLSTM) for short-term trend prediction with Quantum Asynchronous Advantage Actor-Critic (QA3C), a quantum-enhanced variant of the classical A3C. Trained on data from 2000-01-01 to 2025-04-30 (80\% training, 20\% testing), the long-only agent achieves 11.87\% return over around 5 years with 0.92\% max drawdown, outperforming several currency ETFs. We detail state design (QLSTM features and indicators), reward function for trend-following/risk control, and multi-core training. Results show hybrid models yield competitive FX trading performance. Implications include QLSTM's effectiveness for small-profit trades with tight risk and future enhancements. Key hyperparameters: QLSTM sequence length$=$4, QA3C workers$=$8. Limitations: classical quantum simulation and simplified strategy. \footnote{The views expressed in this article are those of the authors and do not represent the views of Wells Fargo. This article is for informational purposes only. Nothing contained in this article should be construed as investment advice. Wells Fargo makes no express or implied warranties and expressly disclaims all legal, tax, and accounting implications related to this article.