Energy-convergence trade off for the training of neural networks on bio-inspired hardware
作者: Nikhil Garg, Paul Uriarte Vicandi, Yanming Zhang, Alexandre Baigol, Donato Francesco Falcone, Saketh Ram Mamidala, Bert Jan Offrein, Laura Bégon-Lours
分类: cs.ET, cs.LG, eess.SY
发布日期: 2025-09-10
💡 一句话要点
针对神经形态硬件,提出能量-收敛权衡方法,优化神经网络训练。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 神经形态计算 忆阻器 片上学习 能量效率 随机梯度下降
📋 核心要点
- 现有神经网络训练在边缘设备上功耗高,数据传输成本大,无法满足可穿戴设备等需求。
- 利用忆阻器特性,通过控制脉冲宽度,在能量消耗和收敛速度之间进行权衡,优化片上学习效率。
- 提出“对称点转移”技术,解决由于忆阻器不对称更新导致的精度下降问题,恢复了模型准确性。
📝 摘要(中文)
可穿戴传感器和植入式设备的日益普及推动了对边缘AI处理的需求,需要超低功耗以实现连续运行。受大脑启发,新兴的忆阻器器件有望通过消除计算和内存之间昂贵的数据传输来加速神经网络训练。然而,平衡性能和能源效率仍然是一个挑战。本文研究了基于HfO2/ZrO2超晶格的铁电突触器件,并将其实验测量的权重更新输入到硬件感知的神经网络模拟中。结果表明,在20纳秒到0.2毫秒的脉冲宽度范围内,较短的脉冲降低了每次更新的能量,但需要更多的训练周期,同时仍然在不牺牲准确性的前提下降低了总能量。与混合精度SGD相比,使用普通随机梯度下降(SGD)的分类精度有所降低。本文分析了其原因,并提出了一种“对称点转移”技术,解决了不对称更新并恢复了准确性。这些结果突出了准确性、收敛速度和能量使用之间的权衡,表明采用定制训练的短脉冲编程可以显著提高片上学习效率。
🔬 方法详解
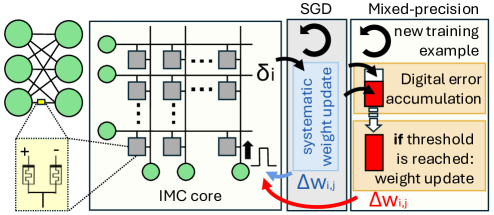
问题定义:论文旨在解决在生物启发硬件(特别是基于忆阻器的神经形态硬件)上训练神经网络时,能量效率和收敛速度之间的矛盾。传统的神经网络训练方法在边缘设备上功耗过高,且数据需要在计算单元和存储单元之间频繁传输,导致能量效率低下。忆阻器作为一种新兴的神经形态器件,具有在本地进行计算和存储的潜力,可以显著降低数据传输的能量消耗,但其权重更新特性可能导致收敛速度变慢甚至精度下降。
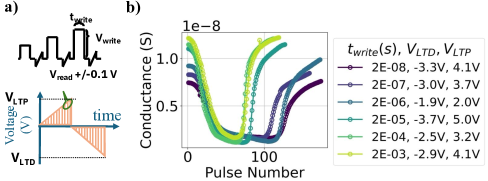
核心思路:论文的核心思路是通过调整忆阻器权重更新的脉冲宽度,在能量消耗和收敛速度之间进行权衡。较短的脉冲宽度可以降低每次权重更新的能量消耗,但可能导致权重更新幅度较小,需要更多的训练周期才能达到相同的精度。同时,论文还提出了一种“对称点转移”技术,用于解决忆阻器不对称更新带来的精度损失问题。
技术框架:论文的技术框架主要包括以下几个部分:1) 基于HfO2/ZrO2超晶格的铁电突触器件的实验测量,获取不同脉冲宽度下的权重更新数据;2) 将实验测量的权重更新数据输入到硬件感知的神经网络模拟中;3) 使用随机梯度下降(SGD)或混合精度SGD进行神经网络训练;4) 评估不同脉冲宽度和训练策略下的分类精度、收敛速度和能量消耗;5) 应用“对称点转移”技术,提高分类精度。
关键创新:论文的关键创新点在于:1) 提出了能量-收敛权衡的概念,并探索了通过调整忆阻器权重更新的脉冲宽度来实现能量效率和收敛速度的优化;2) 提出了一种“对称点转移”技术,用于解决忆阻器不对称更新带来的精度损失问题,该技术能够有效提高神经网络的分类精度。
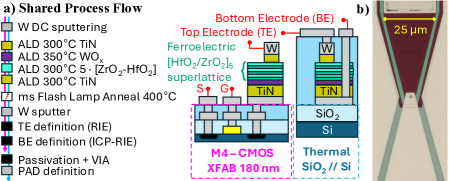
关键设计:论文的关键设计包括:1) 忆阻器器件的材料选择和结构设计,采用了HfO2/ZrO2超晶格结构,以实现良好的铁电性能;2) 权重更新脉冲宽度的选择范围,从20纳秒到0.2毫秒,以探索不同脉冲宽度下的能量消耗和收敛速度;3) 训练策略的选择,包括普通SGD和混合精度SGD,以评估不同训练策略对分类精度的影响;4) “对称点转移”技术的具体实现,通过调整权重更新的阈值,使正向和负向更新更加对称。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用较短的脉冲宽度可以降低每次权重更新的能量消耗,同时通过增加训练周期,可以在不牺牲准确性的前提下降低总能量消耗。此外,“对称点转移”技术能够有效提高神经网络的分类精度,恢复因忆阻器不对称更新造成的精度损失。具体而言,在某些实验设置下,该技术可以将分类精度提高到接近混合精度SGD的水平。
🎯 应用场景
该研究成果可应用于可穿戴设备、植入式医疗设备等边缘计算场景,实现低功耗、高性能的AI处理。通过优化神经网络训练过程,降低设备能耗,延长电池续航时间,提升用户体验。此外,该研究对于开发新型神经形态计算系统,推动人工智能在资源受限环境下的应用具有重要意义。
📄 摘要(原文)
The increasing deployment of wearable sensors and implantable devices is shifting AI processing demands to the extreme edge, necessitating ultra-low power for continuous operation. Inspired by the brain, emerging memristive devices promise to accelerate neural network training by eliminating costly data transfers between compute and memory. Though, balancing performance and energy efficiency remains a challenge. We investigate ferroelectric synaptic devices based on HfO2/ZrO2 superlattices and feed their experimentally measured weight updates into hardware-aware neural network simulations. Across pulse widths from 20 ns to 0.2 ms, shorter pulses lower per-update energy but require more training epochs while still reducing total energy without sacrificing accuracy. Classification accuracy using plain stochastic gradient descent (SGD) is diminished compared to mixed-precision SGD. We analyze the causes and propose a ``symmetry point shifting'' technique, addressing asymmetric updates and restoring accuracy. These results highlight a trade-off among accuracy, convergence speed, and energy use, showing that short-pulse programming with tailored training significantly enhances on-chip learning efficiency.