Outcome-based Exploration for LLM Reasoning
作者: Yuda Song, Julia Kempe, Remi Munos
分类: cs.LG, cs.CL
发布日期: 2025-09-08
备注: 26 pages, 11 figures
💡 一句话要点
提出基于结果的探索方法,提升LLM推理能力并保持生成多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 推理能力 多样性 探索策略
📋 核心要点
- 基于结果的强化学习虽然提高了LLM的推理准确性,但牺牲了生成多样性,影响了实际应用。
- 论文提出基于结果的探索方法,通过奖励罕见答案和惩罚批次内重复来提升多样性。
- 实验表明,该方法在提高准确率的同时,有效缓解了多样性崩溃,提升了LLM的推理能力。
📝 摘要(中文)
强化学习(RL)已成为提升大型语言模型(LLM)推理能力的有效方法。基于结果的强化学习,仅根据最终答案的正确性来奖励策略,虽然能显著提高准确率,但也会导致生成多样性的系统性损失。这种崩溃会损害实际性能,因为多样性对于测试时的扩展至关重要。我们通过将RL后训练视为一个采样过程来分析这种现象,并表明,令人惊讶的是,相对于基础模型,RL甚至会降低训练集上的有效多样性。我们的研究强调了两个核心发现:(i)多样性退化的传递,即已解决问题上多样性的降低会传播到未解决的问题上,以及(ii)结果空间的可处理性,因为推理任务只允许有限数量的不同答案。受这些见解的启发,我们提出了基于结果的探索,它根据最终结果分配探索奖励。我们介绍了两种互补的算法:历史探索,通过UCB风格的奖励来鼓励很少观察到的答案,以及批量探索,惩罚批次内的重复以促进测试时多样性。在Llama和Qwen模型上进行的标准竞赛数学实验表明,这两种方法都能提高准确率,同时减轻多样性崩溃。在理论方面,我们通过一种新的基于结果的bandit模型,形式化了基于结果的探索的好处。总之,这些贡献为RL方法开辟了一条实用途径,可以在不牺牲可扩展部署所需多样性的前提下,增强推理能力。
🔬 方法详解
问题定义:现有基于结果的强化学习方法在提升LLM推理能力时,过度关注正确答案,导致生成多样性显著下降。这种多样性缺失会严重影响模型在实际场景中的泛化能力和鲁棒性,尤其是在需要处理复杂或开放式问题时。因此,如何在提升准确率的同时,保持或恢复LLM的生成多样性,是一个亟待解决的问题。
核心思路:论文的核心思路是引入基于结果的探索机制,鼓励模型探索更多不同的答案,而不是仅仅集中于已知的正确答案。通过对罕见答案给予奖励,并对批次内的重复答案进行惩罚,促使模型在训练过程中学习到更多样化的推理路径和表达方式。这种探索机制旨在平衡准确率和多样性,从而提升模型在实际应用中的性能。
技术框架:整体框架是在标准的强化学习流程中,引入了额外的探索奖励。具体来说,模型首先生成答案,然后根据答案的正确性获得基础奖励。在此基础上,模型还会根据答案的罕见程度(历史探索)和批次内的重复程度(批量探索)获得额外的探索奖励。最终的奖励是基础奖励和探索奖励的加权和,用于更新模型的策略。
关键创新:论文的关键创新在于提出了基于结果的探索策略,将探索奖励与最终答案的结果直接关联。与传统的探索方法(如ε-greedy或Thompson sampling)不同,该方法更加关注答案的多样性,而不是仅仅关注动作的多样性。此外,论文还提出了两种具体的探索算法:历史探索和批量探索,分别从不同的角度来促进答案的多样性。
关键设计:历史探索使用UCB(Upper Confidence Bound)风格的奖励,鼓励模型探索历史上很少观察到的答案。具体来说,对于每个答案,计算其被观察到的次数,并根据UCB公式计算其探索奖励。批量探索则惩罚批次内的重复答案,鼓励模型生成更多不同的答案。具体来说,对于每个答案,计算其在当前批次内出现的次数,并根据一个惩罚函数计算其探索奖励。这两种探索算法可以单独使用,也可以结合使用,以达到更好的效果。
🖼️ 关键图片

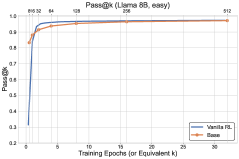
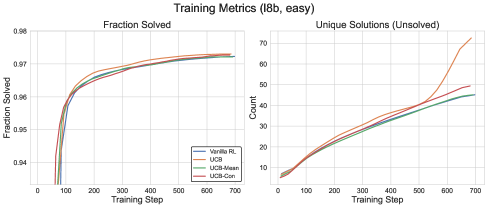
📊 实验亮点
实验结果表明,提出的基于结果的探索方法在标准竞赛数学数据集上,显著提高了Llama和Qwen模型的准确率,同时有效缓解了多样性崩溃。具体来说,与基线方法相比,该方法在保持或提高准确率的同时,显著增加了生成答案的多样性,证明了其有效性。
🎯 应用场景
该研究成果可广泛应用于需要LLM进行复杂推理的场景,例如数学问题求解、代码生成、知识问答等。通过提升LLM的推理能力和生成多样性,可以提高模型在实际应用中的泛化能力和鲁棒性,使其能够更好地适应各种复杂和开放式的问题。
📄 摘要(原文)
Reinforcement learning (RL) has emerged as a powerful method for improving the reasoning abilities of large language models (LLMs). Outcome-based RL, which rewards policies solely for the correctness of the final answer, yields substantial accuracy gains but also induces a systematic loss in generation diversity. This collapse undermines real-world performance, where diversity is critical for test-time scaling. We analyze this phenomenon by viewing RL post-training as a sampling process and show that, strikingly, RL can reduce effective diversity even on the training set relative to the base model. Our study highlights two central findings: (i) a transfer of diversity degradation, where reduced diversity on solved problems propagates to unsolved ones, and (ii) the tractability of the outcome space, since reasoning tasks admit only a limited set of distinct answers. Motivated by these insights, we propose outcome-based exploration, which assigns exploration bonuses according to final outcomes. We introduce two complementary algorithms: historical exploration, which encourages rarely observed answers via UCB-style bonuses, and batch exploration, which penalizes within-batch repetition to promote test-time diversity. Experiments on standard competition math with Llama and Qwen models demonstrate that both methods improve accuracy while mitigating diversity collapse. On the theoretical side, we formalize the benefit of outcome-based exploration through a new model of outcome-based bandits. Together, these contributions chart a practical path toward RL methods that enhance reasoning without sacrificing the diversity essential for scalable deployment.