WindFM: An Open-Source Foundation Model for Zero-Shot Wind Power Forecasting
作者: Hang Fan, Yu Shi, Zongliang Fu, Shuo Chen, Wei Wei, Wei Xu, Jian Li
分类: cs.LG
发布日期: 2025-09-08
🔗 代码/项目: GITHUB
💡 一句话要点
WindFM:用于零样本风力发电预测的开源基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 风力发电预测 基础模型 零样本学习 时间序列预测 Transformer 能源管理 可再生能源
📋 核心要点
- 现有风电预测方法难以兼顾泛化性和领域知识,特定站点模型缺乏迁移能力,通用时间序列模型微调成本高。
- WindFM采用离散化-生成框架,将连续时间序列转换为离散token,利用Transformer学习风电动态的通用表示。
- 实验表明,WindFM在零样本预测任务上优于现有模型,且在分布外数据上表现出良好的鲁棒性和迁移性。
📝 摘要(中文)
高质量的风力发电预测对于现代电网的运行至关重要。然而,目前主流的数据驱动方法要么训练特定站点的模型,无法推广到其他位置,要么依赖于通用时间序列基础模型的微调,难以整合能源领域的特定数据。本文介绍了WindFM,一个轻量级的生成式基础模型,专门为概率性风力发电预测而设计。WindFM采用离散化-生成框架。一个专门的时间序列分词器首先将连续的多元观测转换为离散的、分层的token。随后,一个仅解码器的Transformer通过自回归地预训练这些token序列,学习风力发电动态的通用表示。使用包含来自超过126,000个站点的约1500亿个时间步的综合WIND Toolkit数据集,WindFM发展了对大气条件和功率输出之间复杂相互作用的基础理解。大量实验表明,我们紧凑的810万参数模型在确定性和概率性任务上都实现了最先进的零样本性能,优于专门的模型和更大的基础模型,而无需任何微调。特别地,WindFM在来自不同大陆的分布外数据下表现出强大的适应性,证明了其学习表示的鲁棒性和可迁移性。我们预训练的模型已在https://github.com/shiyu-coder/WindFM上公开。
🔬 方法详解
问题定义:论文旨在解决风力发电功率预测问题,现有方法要么是针对特定站点的模型,泛化能力差;要么是通用时间序列模型,难以融入风电领域的专业知识,且微调成本高昂。
核心思路:论文的核心思路是构建一个轻量级的、可泛化的风电领域基础模型。通过将连续的时间序列数据离散化为token序列,并利用Transformer模型进行自回归预训练,从而学习风电动态的通用表示。这样,模型就可以在新的站点或场景下进行零样本预测,无需微调。
技术框架:WindFM的技术框架主要包括两个阶段:时间序列token化和Transformer预训练。首先,使用专门的时间序列分词器将连续的多元观测数据(例如风速、风向等)转换为离散的、分层的token序列。然后,使用一个仅解码器的Transformer模型,以自回归的方式在这些token序列上进行预训练,学习风电动态的通用表示。
关键创新:WindFM的关键创新在于其离散化-生成框架和轻量级模型设计。通过将连续数据离散化,可以有效地利用Transformer模型的强大序列建模能力。同时,通过优化模型结构和参数量,使其能够在有限的计算资源下实现高性能。此外,WindFM专注于风电领域,能够更好地捕捉风电数据的特性。
关键设计:WindFM的关键设计包括:(1) 专门的时间序列分词器,用于将连续数据转换为离散token;(2) 仅解码器的Transformer模型,用于自回归预训练;(3) 损失函数采用标准的交叉熵损失函数,用于优化模型参数;(4) 模型参数量为8.1M,属于轻量级模型。
🖼️ 关键图片

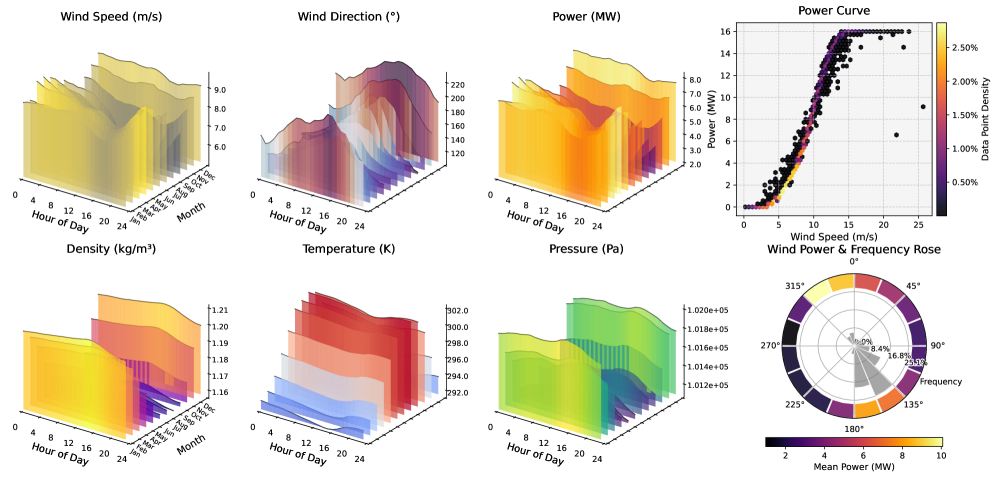
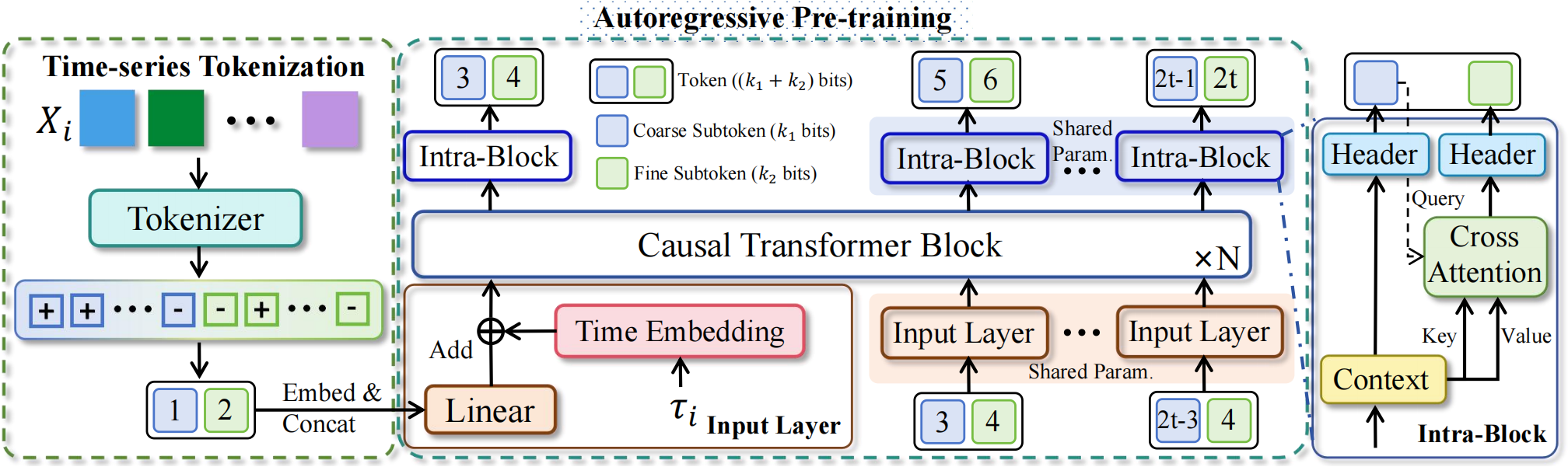
📊 实验亮点
WindFM在WIND Toolkit数据集上进行了广泛的实验,结果表明,该模型在零样本预测任务上取得了最先进的性能,优于专门的模型和更大的基础模型,而无需任何微调。特别是在来自不同大陆的分布外数据上,WindFM表现出强大的适应性,证明了其学习表示的鲁棒性和可迁移性。该模型仅有8.1M参数,计算效率高。
🎯 应用场景
WindFM可应用于智能电网、能源管理系统等领域,实现对风力发电功率的精确预测,提高电网运行的稳定性和经济性。该模型能够降低风电预测的成本,加速风电技术的推广应用,并为可再生能源的优化调度提供有力支持。未来,WindFM有望扩展到其他可再生能源领域,构建更加通用的能源预测基础模型。
📄 摘要(原文)
High-quality wind power forecasting is crucial for the operation of modern power grids. However, prevailing data-driven paradigms either train a site-specific model which cannot generalize to other locations or rely on fine-tuning of general-purpose time series foundation models which are difficult to incorporate domain-specific data in the energy sector. This paper introduces WindFM, a lightweight and generative Foundation Model designed specifically for probabilistic wind power forecasting. WindFM employs a discretize-and-generate framework. A specialized time-series tokenizer first converts continuous multivariate observations into discrete, hierarchical tokens. Subsequently, a decoder-only Transformer learns a universal representation of wind generation dynamics by autoregressively pre-training on these token sequences. Using the comprehensive WIND Toolkit dataset comprising approximately 150 billion time steps from more than 126,000 sites, WindFM develops a foundational understanding of the complex interplay between atmospheric conditions and power output. Extensive experiments demonstrate that our compact 8.1M parameter model achieves state-of-the-art zero-shot performance on both deterministic and probabilistic tasks, outperforming specialized models and larger foundation models without any fine-tuning. In particular, WindFM exhibits strong adaptiveness under out-of-distribution data from a different continent, demonstrating the robustness and transferability of its learned representations. Our pre-trained model is publicly available at https://github.com/shiyu-coder/WindFM.