Profiling LoRA/QLoRA Fine-Tuning Efficiency on Consumer GPUs: An RTX 4060 Case Study
作者: MSR Avinash
分类: cs.LG, cs.AI, cs.PF
发布日期: 2025-09-07
备注: 8 pages, 3 figures, 2 tables. Primary category: cs.LG (Machine Learning); secondary: cs.AI (Artificial Intelligence). LaTeX source with figures included
💡 一句话要点
研究RTX 4060上LoRA/QLoRA微调LLM效率,提供资源受限场景下的实用指南。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LoRA QLoRA 参数高效微调 消费级GPU RTX 4060 大型语言模型 性能分析
📋 核心要点
- 现有研究缺乏对消费级GPU(特别是8GB VRAM限制下)上LoRA/QLoRA微调LLM效率的系统性探索。
- 该研究通过在RTX 4060上对Qwen2.5-1.5B-Instruct模型进行LoRA/QLoRA微调,系统分析了不同配置下的性能。
- 实验结果表明,Paged优化器能显著提升吞吐量,fp16精度优于bf16,且在8GB限制下可支持较长序列长度。
📝 摘要(中文)
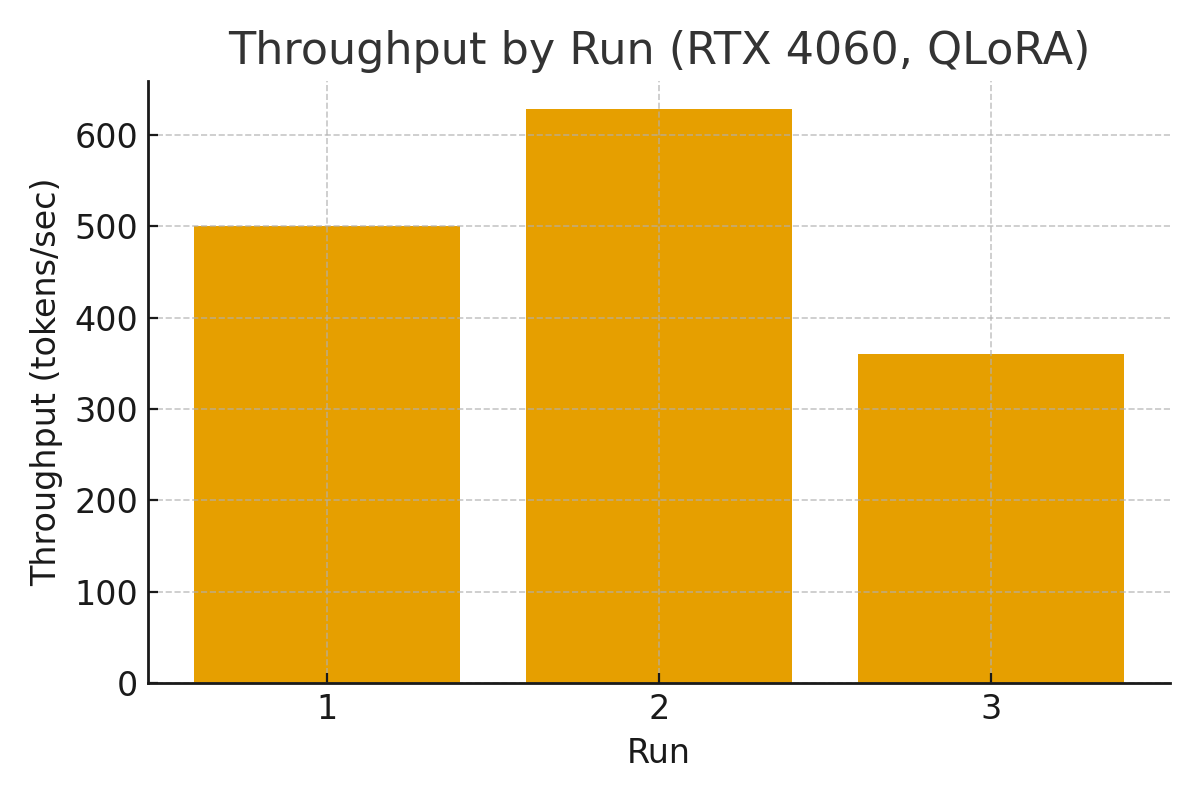
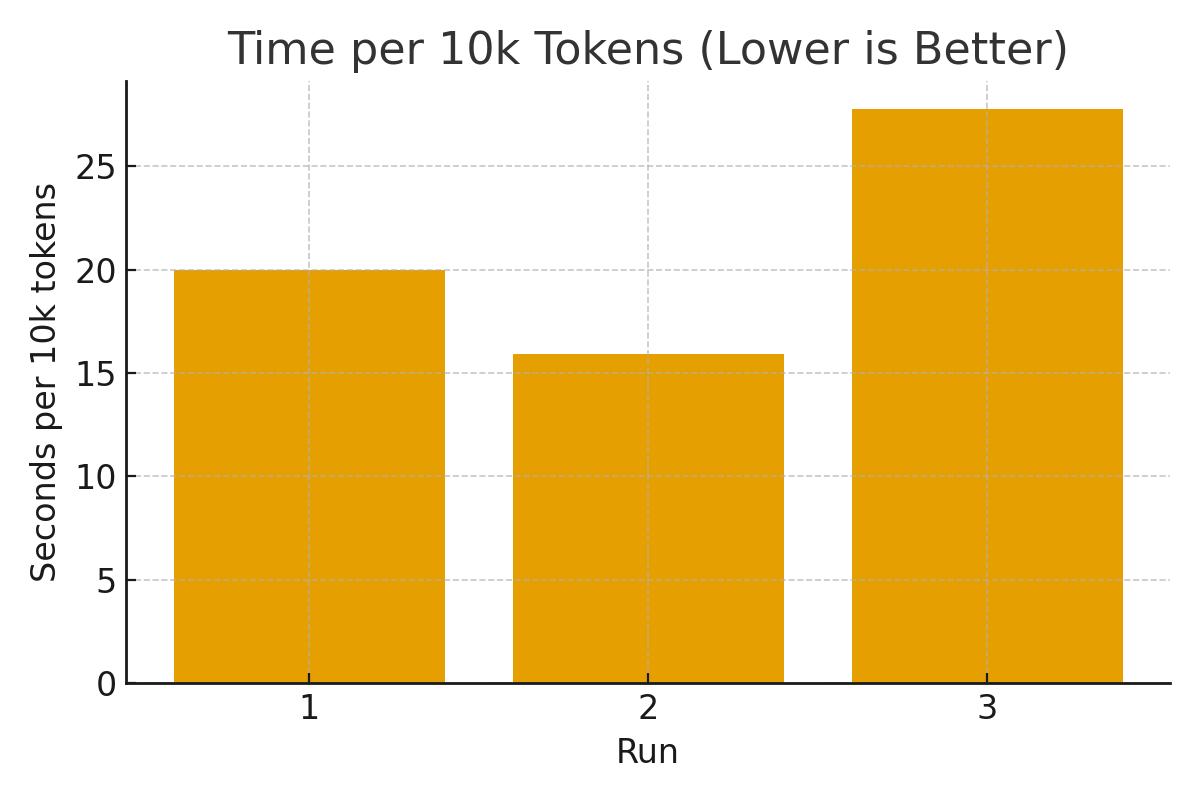
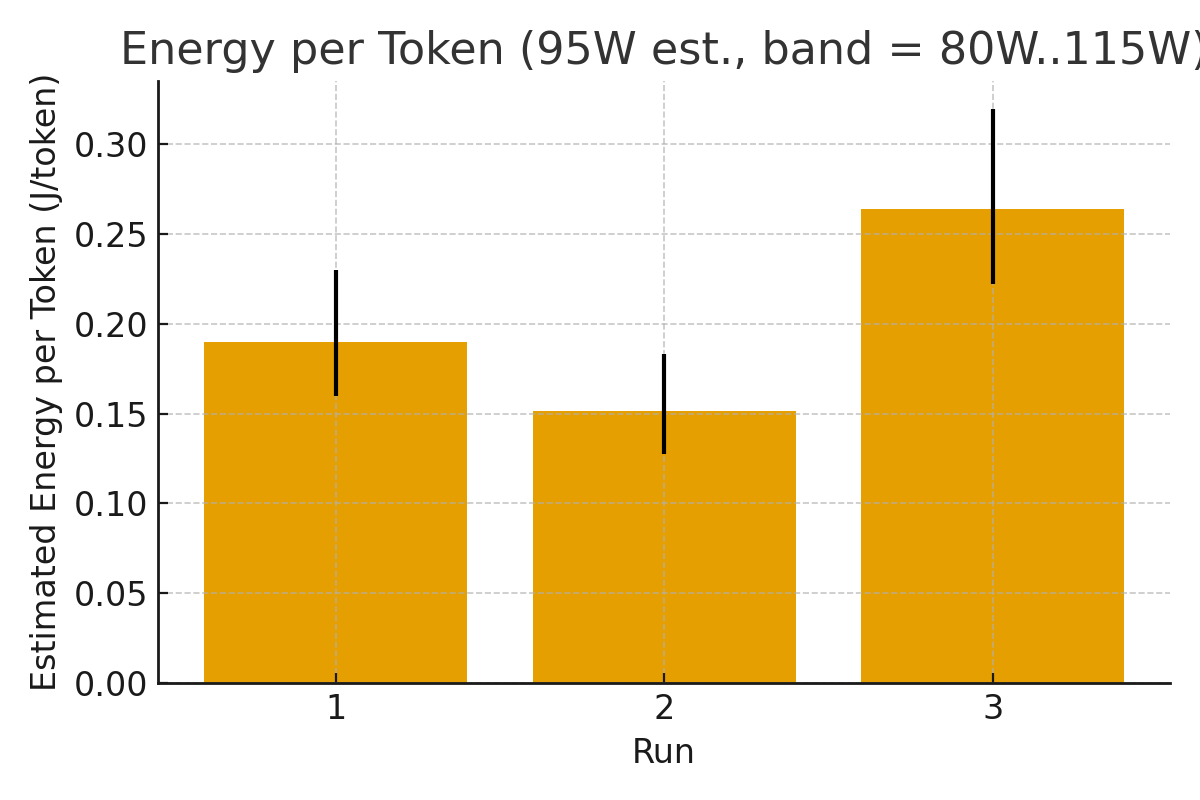
本文针对消费级GPU上使用LoRA和QLoRA等参数高效方法微调大型语言模型(LLM)的效率进行了研究,尤其关注8GB VRAM严格限制下的性能。我们使用Qwen2.5-1.5B-Instruct模型在单个NVIDIA RTX 4060上,对LoRA/QLoRA微调进行了受控的性能分析。通过三个代表性配置,系统地改变了批量大小、序列长度、优化器选择(AdamW vs. PagedAdamW)和精度(fp16 vs. bf16)。我们报告了吞吐量(tokens/s)、每1万个tokens的时间和VRAM占用,以及基于GPU板卡功率限制的能源估计。结果表明,Paged优化器将吞吐量提高了高达25%(628 tok/s vs. 500 tok/s基线),而bf16相对于fp16降低了效率。尽管存在8GB的限制,但使用参数高效策略可以实现高达2048个tokens的序列长度。据我们所知,这是第一个在消费级GPU上对LLM微调效率进行系统案例研究,为资源受限的研究人员和从业者提供了可复现的基准和实用指南。
🔬 方法详解
问题定义:论文旨在解决在消费级GPU(如RTX 4060)上,使用LoRA/QLoRA等参数高效微调方法训练大型语言模型时,如何高效利用有限的VRAM资源,并优化训练速度的问题。现有方法缺乏针对此类硬件的系统性分析和优化指导,导致资源受限的研究者难以充分利用这些技术。
核心思路:论文的核心思路是通过系统性的实验分析,评估不同配置(如批量大小、序列长度、优化器、精度)对微调效率的影响,从而为资源受限的用户提供最佳实践和性能基准。通过细致的性能剖析,揭示不同参数选择对吞吐量、VRAM占用和能耗的影响。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择Qwen2.5-1.5B-Instruct模型作为实验对象;2) 在RTX 4060 GPU上,使用LoRA/QLoRA进行微调;3) 系统性地改变批量大小、序列长度、优化器(AdamW vs. PagedAdamW)和精度(fp16 vs. bf16)等参数;4) 测量并记录吞吐量(tokens/s)、每1万个tokens的时间、VRAM占用和能耗等指标;5) 分析实验数据,总结不同配置下的性能表现,并给出优化建议。
关键创新:该研究的关键创新在于它是第一个针对消费级GPU上的LLM微调效率进行系统性案例研究。它不仅提供了可复现的基准数据,还为资源受限的研究人员和从业者提供了实用的优化指南。此外,该研究还深入探讨了Paged优化器和不同精度对微调效率的影响,为未来的研究方向提供了参考。
关键设计:实验中,关键的设计包括:1) 选择具有代表性的Qwen2.5-1.5B-Instruct模型,以保证结果的通用性;2) 系统性地改变批量大小、序列长度、优化器和精度等参数,以全面评估不同配置的影响;3) 使用标准的性能指标(如吞吐量、VRAM占用和能耗)进行评估,以便与其他研究进行比较;4) 基于GPU板卡功率限制进行能源估计,以提供更全面的性能分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用PagedAdamW优化器相比于AdamW,吞吐量提升高达25%(628 tok/s vs. 500 tok/s)。同时,fp16精度优于bf16。尽管受到8GB VRAM的限制,但通过参数高效微调策略,可以支持高达2048个tokens的序列长度。这些数据为在消费级GPU上进行LLM微调提供了重要的参考。
🎯 应用场景
该研究成果可应用于资源受限的科研机构、小型企业或个人开发者,帮助他们在消费级GPU上高效地微调大型语言模型,从而降低AI开发的门槛。其潜在应用领域包括:个性化教育、智能客服、内容创作、代码生成等。该研究为在边缘设备上部署LLM提供了可行性方案,具有重要的实际价值和未来影响。
📄 摘要(原文)
Fine-tuning large language models (LLMs) with parameter-efficient techniques such as LoRA and QLoRA has enabled adaptation of foundation models on modest hardware. Yet the efficiency of such training on consumer-grade GPUs, especially under strict 8 GB VRAM limits, remains underexplored. We present a controlled profiling study of LoRA/QLoRA fine-tuning using the Qwen2.5-1.5B-Instruct model on a single NVIDIA RTX 4060. Across three representative configurations, we systematically vary batch size, sequence length, optimizer choice (AdamW vs. PagedAdamW), and precision (fp16 vs. bf16). We report throughput (tokens/s), time per 10k tokens, and VRAM footprint, alongside energy estimates derived from GPU board power limits. Our results show that paged optimizers improve throughput by up to 25% (628 tok/s vs. 500 tok/s baseline), while bf16 degrades efficiency relative to fp16. Despite 8 GB constraints, sequence lengths up to 2048 tokens were feasible using parameter-efficient strategies. To our knowledge, this is the first systematic case study of LLM fine- tuning efficiency on consumer GPUs, providing reproducible benchmarks and practical guidelines for resource-constrained researchers and practitioners.