ALPHA: LLM-Enabled Active Learning for Human-Free Network Anomaly Detection
作者: Xuanhao Luo, Shivesh Madan Nath Jha, Akruti Sinha, Zhizhen Li, Yuchen Liu
分类: cs.NI, cs.LG
发布日期: 2025-09-07
备注: Accepted at 44th IEEE International Performance Computing and Communications Conference (IPCCC 2025)
💡 一句话要点
ALPHA:基于LLM的无人值守主动学习网络异常检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络异常检测 主动学习 大型语言模型 少样本学习 日志分析
📋 核心要点
- 传统网络日志分析依赖专家知识或全监督学习,需要大量标注数据和人工成本。
- ALPHA利用语义嵌入、聚类采样和LLM少样本标注,实现自动化异常检测。
- 实验表明,ALPHA在减少人工干预的同时,达到与全监督方法相当的检测精度。
📝 摘要(中文)
本文提出ALPHA,一种用于无人值守日志分析的主动学习流水线,旨在解决网络安全威胁和运营异常检测中对专家知识和大量标注数据的依赖问题。ALPHA集成了语义嵌入、基于聚类的代表性采样和大型语言模型(LLM)辅助的少样本标注,以实现异常检测过程的自动化。LLM标注的标签在集群中传播,从而能够以最少的监督训练大规模异常检测器。为了提高标注准确性,本文提出了一种两步少样本精炼策略,该策略基于LLM的观察到的错误模式自适应地选择信息丰富的提示。在真实日志数据集上的大量实验表明,ALPHA实现了与完全监督方法相当的检测精度,同时减少了人工干预。ALPHA还支持通过LLM驱动的根本原因解释进行可解释性分析。这些能力使ALPHA成为一种可扩展且经济高效的真正自动化基于日志的异常检测解决方案。
🔬 方法详解
问题定义:现有网络异常检测方法依赖于专家知识或全监督学习模型,这需要大量的人工标注数据,成本高昂且效率低下。如何降低对人工标注数据的依赖,实现自动化、低成本的网络异常检测是本文要解决的核心问题。
核心思路:本文的核心思路是利用主动学习框架,结合大型语言模型(LLM)的少样本学习能力,自动标注网络日志数据,并训练异常检测模型。通过聚类采样选择最具代表性的日志样本,减少LLM需要标注的数据量,并通过两步精炼策略提高LLM标注的准确性。
技术框架:ALPHA的整体框架包含以下几个主要阶段:1) 语义嵌入:将网络日志数据转换为语义向量表示。2) 聚类采样:使用聚类算法对语义向量进行聚类,并从每个簇中选择最具代表性的样本。3) LLM少样本标注:利用LLM对选定的样本进行异常或正常的标注。4) 标签传播:将LLM标注的标签传播到同一簇中的其他样本。5) 异常检测器训练:使用标注后的数据训练异常检测模型。6) 根本原因分析:利用LLM对检测到的异常进行根本原因分析。
关键创新:ALPHA的关键创新在于将主动学习与LLM的少样本学习能力相结合,实现了无人值守的网络异常检测。与传统的全监督学习方法相比,ALPHA大大减少了对人工标注数据的需求。此外,ALPHA提出的两步少样本精炼策略能够有效提高LLM标注的准确性。
关键设计:在语义嵌入阶段,可以使用预训练的词嵌入模型或专门为日志数据设计的嵌入模型。聚类算法可以选择K-means或DBSCAN等。LLM的选择可以根据实际需求进行调整,例如使用GPT-3或LLaMA等。两步少样本精炼策略的关键在于选择合适的提示(Prompt),并根据LLM的反馈进行调整。具体的损失函数和网络结构的选择取决于异常检测器的类型,例如可以使用支持向量机(SVM)或深度神经网络。
🖼️ 关键图片

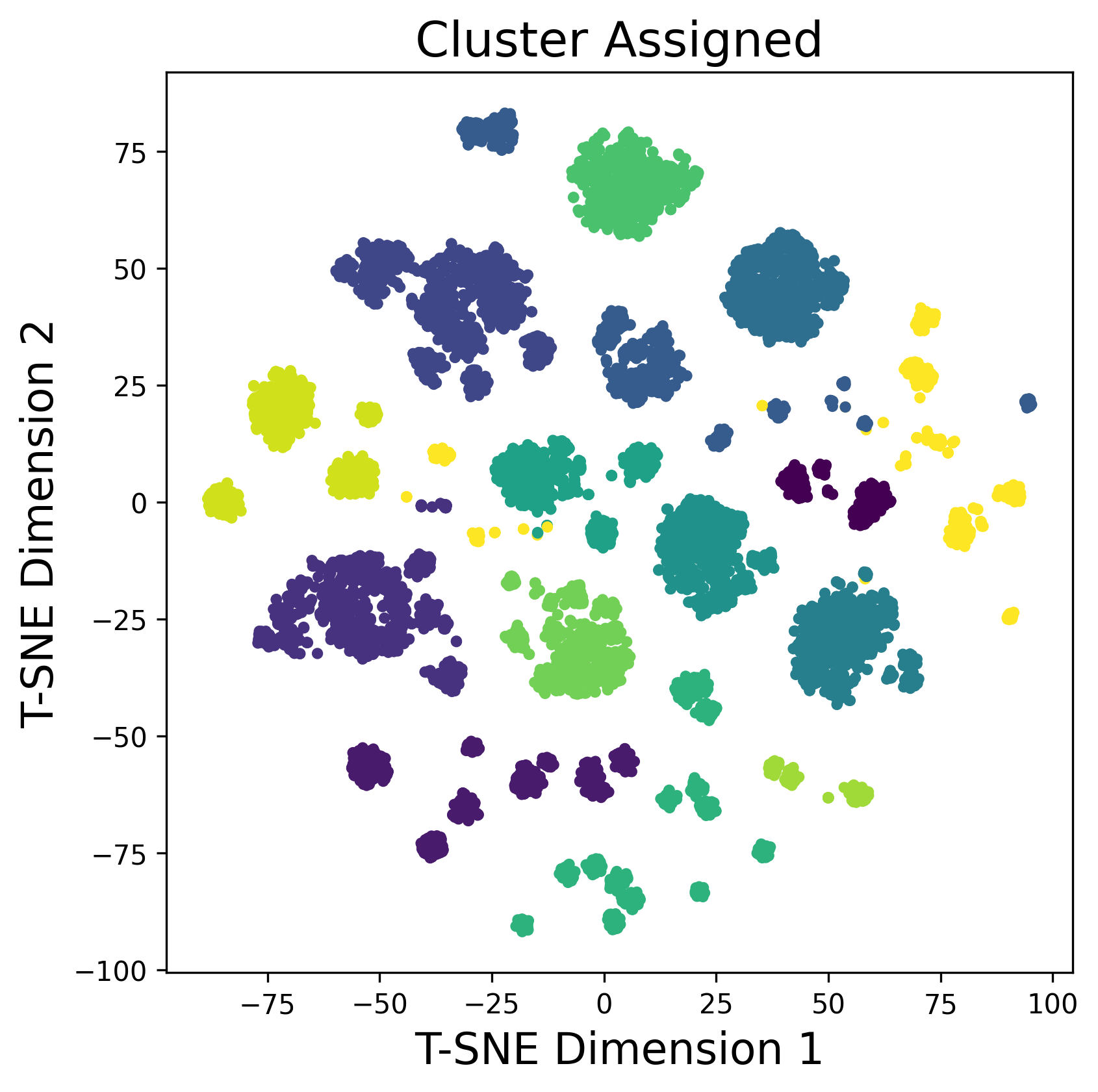
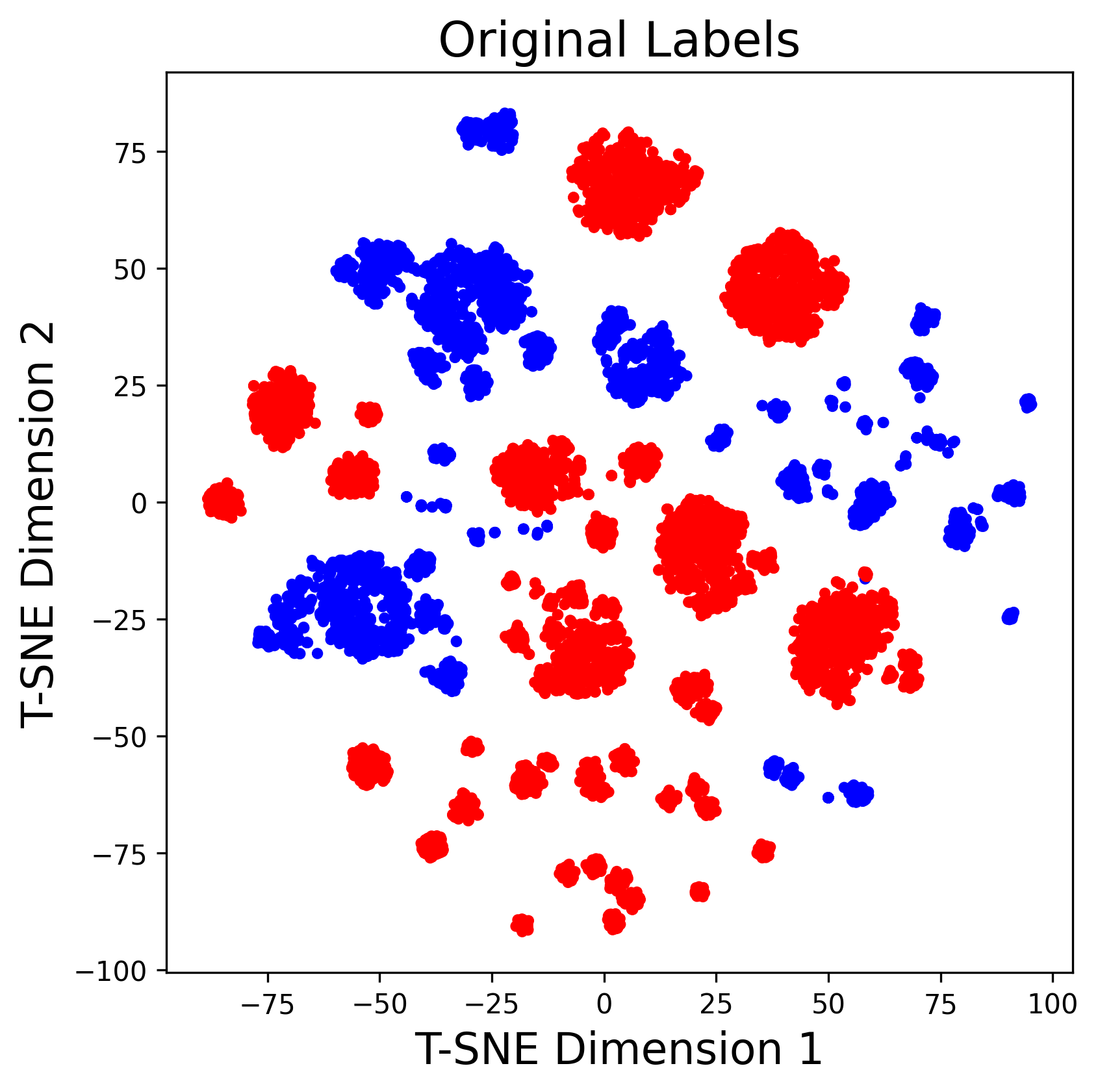
📊 实验亮点
实验结果表明,ALPHA在真实世界的日志数据集上实现了与全监督方法相当的检测精度,同时显著减少了人工标注工作。具体来说,ALPHA在保持高检测率的同时,可以将标注成本降低到传统方法的10%以下。此外,LLM驱动的根本原因分析功能可以帮助安全分析师快速定位问题的根源。
🎯 应用场景
ALPHA可应用于各种网络安全场景,例如入侵检测、恶意软件分析和异常行为识别。该方法能够降低网络安全运营的成本,提高检测效率,并减轻安全分析师的工作负担。未来,ALPHA可以扩展到其他类型的日志数据分析,例如系统日志和应用程序日志,从而实现更全面的安全监控。
📄 摘要(原文)
Network log data analysis plays a critical role in detecting security threats and operational anomalies. Traditional log analysis methods for anomaly detection and root cause analysis rely heavily on expert knowledge or fully supervised learning models, both of which require extensive labeled data and significant human effort. To address these challenges, we propose ALPHA, the first Active Learning Pipeline for Human-free log Analysis. ALPHA integrates semantic embedding, clustering-based representative sampling, and large language model (LLM)-assisted few-shot annotation to automate the anomaly detection process. The LLM annotated labels are propagated across clusters, enabling large-scale training of an anomaly detector with minimal supervision. To enhance the annotation accuracy, we propose a two-step few-shot refinement strategy that adaptively selects informative prompts based on the LLM's observed error patterns. Extensive experiments on real-world log datasets demonstrate that ALPHA achieves detection accuracy comparable to fully supervised methods while mitigating human efforts in the loop. ALPHA also supports interpretable analysis through LLM-driven root cause explanations in the post-detection stage. These capabilities make ALPHA a scalable and cost-efficient solution for truly automated log-based anomaly detection.