Learning to Construct Knowledge through Sparse Reference Selection with Reinforcement Learning
作者: Shao-An Yin
分类: cs.LG, cs.AI, cs.IR
发布日期: 2025-09-07
备注: 8 pages, 2 figures
💡 一句话要点
提出基于强化学习的稀疏引用选择方法,用于知识构建
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 知识构建 稀疏引用选择 文献检索 深度学习
📋 核心要点
- 现有方法难以在海量文献中快速定位关键信息,尤其是在专业领域和信息受限的情况下。
- 该论文提出了一种基于深度强化学习的稀疏引用选择框架,模拟人类专家在有限资源下进行知识构建的过程。
- 实验表明,该方法在药物-基因关系发现任务中,仅通过标题和摘要即可有效构建知识。
📝 摘要(中文)
科学文献的快速增长使得获取新知识变得越来越困难,尤其是在推理复杂、全文访问受限以及目标参考文献在大量候选文献中稀疏的专业领域。本文提出了一种深度强化学习框架,用于稀疏引用选择,该框架模拟人类的知识构建过程,优先考虑在有限的时间和成本下阅读哪些论文。在药物-基因关系发现的评估中,仅限于访问标题和摘要,我们的方法证明了人类和机器都可以有效地从部分信息中构建知识。
🔬 方法详解
问题定义:论文旨在解决在海量科学文献中,如何高效地选择和阅读最相关的文献,从而构建特定领域的知识。现有方法在处理专业领域、信息受限(如仅有标题和摘要)以及目标文献稀疏的情况下,效率低下,难以快速定位关键信息。
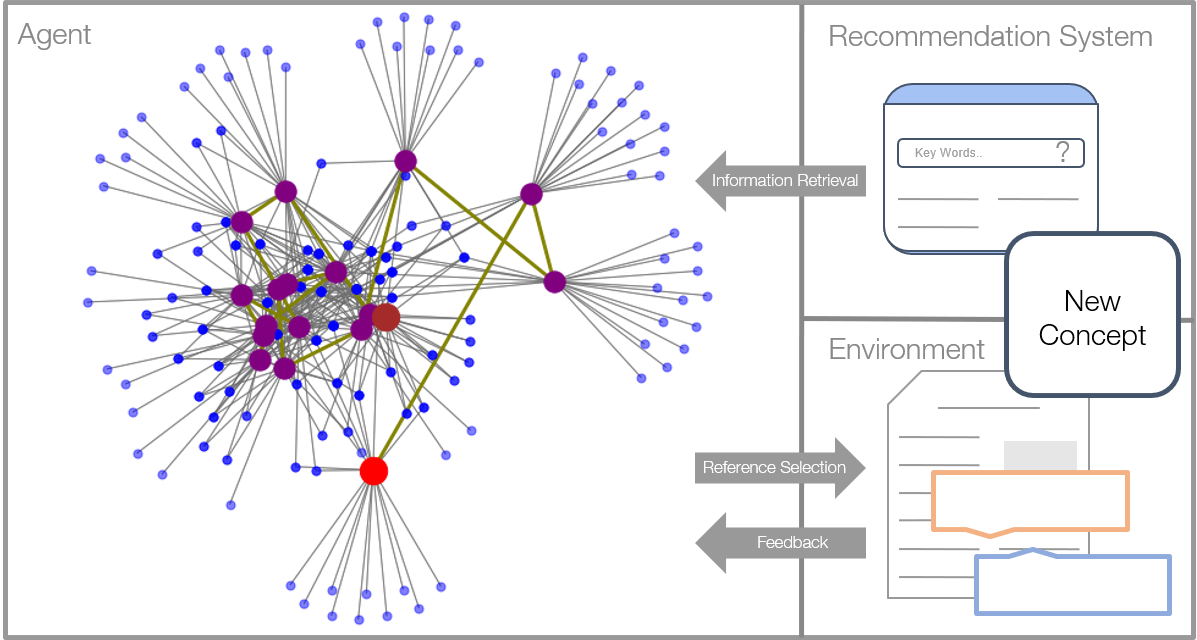
核心思路:论文的核心思路是模拟人类专家在阅读文献时的策略,即根据已读文献的信息,动态地选择下一步要阅读的文献,从而逐步构建知识。通过强化学习,训练一个智能体,使其能够学习到最优的文献选择策略。
技术框架:该框架主要包含以下几个模块:1) 环境:模拟文献阅读环境,提供文献信息(标题、摘要等)和奖励信号。2) 智能体:基于深度神经网络,根据当前状态(已读文献的信息)选择下一步要阅读的文献。3) 奖励函数:根据智能体的选择结果,给予奖励或惩罚,引导智能体学习最优策略。整体流程是,智能体与环境交互,不断学习和优化文献选择策略。
关键创新:该方法的主要创新点在于,将知识构建问题建模为一个稀疏引用选择问题,并利用强化学习来解决。与传统的文献检索方法相比,该方法能够根据已读文献的信息,动态地调整文献选择策略,从而更有效地构建知识。此外,该方法还能够处理信息受限的情况,例如仅有标题和摘要。
关键设计:智能体采用深度神经网络(具体结构未知)来表示策略函数,输入是已读文献的向量表示,输出是选择下一篇文献的概率分布。奖励函数的设计至关重要,需要能够反映智能体选择的文献是否与目标知识相关。具体的奖励函数形式未知,但可能包括与目标知识的相似度、是否发现了新的关键信息等因素。训练过程中,采用策略梯度算法(如REINFORCE或Actor-Critic)来优化策略函数。
🖼️ 关键图片
📊 实验亮点
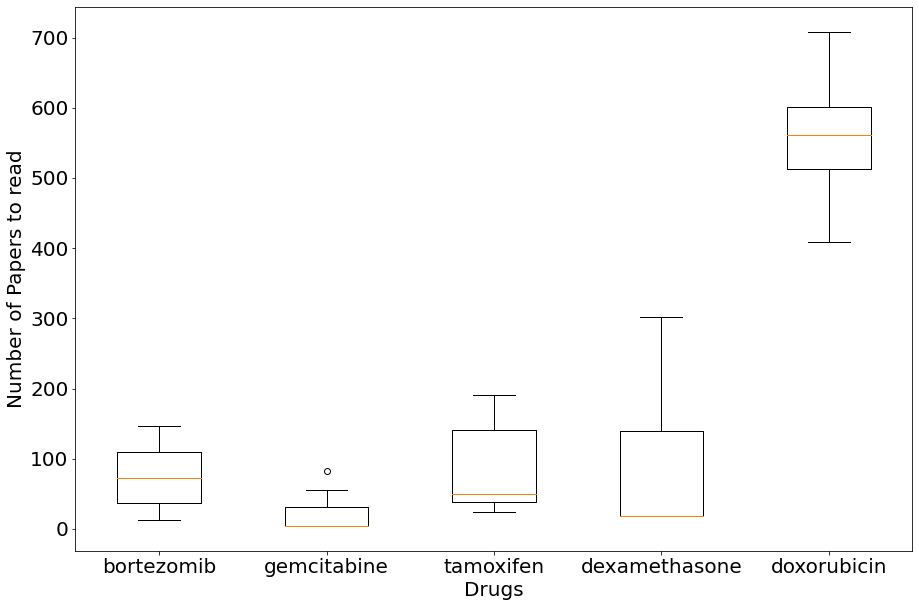
该论文在药物-基因关系发现任务上进行了评估,结果表明,该方法在仅访问标题和摘要的情况下,能够有效地构建知识。具体的性能数据和对比基线未知,但摘要中强调了该方法能够使机器像人类一样从部分信息中构建知识,表明其具有一定的优越性。
🎯 应用场景
该研究成果可应用于多个领域,例如:科学研究、技术情报分析、专利分析等。通过该方法,研究人员可以更高效地从海量文献中获取所需知识,加速科研进程。企业可以利用该方法进行竞争情报分析,了解行业动态和技术趋势。此外,该方法还可以用于个性化推荐系统,为用户推荐最相关的文献或信息。
📄 摘要(原文)
The rapid expansion of scientific literature makes it increasingly difficult to acquire new knowledge, particularly in specialized domains where reasoning is complex, full-text access is restricted, and target references are sparse among a large set of candidates. We present a Deep Reinforcement Learning framework for sparse reference selection that emulates human knowledge construction, prioritizing which papers to read under limited time and cost. Evaluated on drug--gene relation discovery with access restricted to titles and abstracts, our approach demonstrates that both humans and machines can construct knowledge effectively from partial information.