GraMFedDHAR: Graph Based Multimodal Differentially Private Federated HAR
作者: Labani Halder, Tanmay Sen, Sarbani Palit
分类: cs.LG, cs.AI, cs.CR, stat.ML
发布日期: 2025-09-06
💡 一句话要点
GraMFedDHAR:基于图的多模态差分隐私联邦HAR框架,提升隐私保护下的活动识别精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体活动识别 多模态融合 联邦学习 图神经网络 差分隐私
📋 核心要点
- 传统集中式深度学习在多模态人体活动识别中面临数据共享限制和隐私泄露风险,联邦学习虽能保护隐私,但难以有效处理异构多模态数据。
- GraMFedDHAR框架将不同传感器数据建模为图结构,利用图卷积神经网络提取特征,并通过注意力机制融合多模态信息,提升模型鲁棒性。
- 实验表明,该框架在差分隐私约束下,相比传统方法性能提升显著,验证了图神经网络在多模态联邦学习中的有效性和抗噪性。
📝 摘要(中文)
本文提出了一种基于图的多模态联邦学习框架GraMFedDHAR,用于人体活动识别(HAR)任务。该框架将压力垫、深度相机和多个加速度计等不同的传感器数据流建模为特定模态的图,通过残差图卷积神经网络(GCNs)进行处理,并通过基于注意力的加权融合,而非简单的连接。融合后的嵌入能够实现鲁棒的活动分类,而差分隐私则在联邦聚合过程中保护数据。实验结果表明,所提出的MultiModalGCN模型优于基线MultiModalFFN,在集中式和联邦范式中,非差分隐私设置下的准确率提高了2%。更重要的是,在差分隐私约束下观察到显著的改进:MultiModalGCN始终优于MultiModalFFN,性能差距在7%到13%之间,具体取决于隐私预算和设置。这些结果突出了基于图的建模在多模态学习中的鲁棒性,其中GNN被证明更能抵抗DP噪声引入的性能下降。
🔬 方法详解
问题定义:论文旨在解决多模态人体活动识别(HAR)中,在保护用户隐私的前提下,如何有效利用异构传感器数据进行准确分类的问题。现有方法,如基于全连接前馈网络(FFN)的多模态融合,难以有效捕捉传感器数据间的复杂关系,且在差分隐私(DP)保护下性能下降明显。
核心思路:核心思路是将不同模态的传感器数据建模成图结构,利用图卷积神经网络(GCN)提取特征,并通过注意力机制进行模态融合。这种方法能够更好地捕捉数据间的依赖关系,并且GCN对DP噪声具有更强的鲁棒性。
技术框架:GraMFedDHAR框架包含以下主要模块:1) 图构建:将每个传感器数据流(如压力垫、深度相机、加速度计)表示为一个图,节点代表传感器读数,边代表传感器之间的关系(例如,空间或时间邻近性)。2) 特征提取:使用残差GCN提取每个模态图的特征表示。3) 模态融合:利用注意力机制对不同模态的特征进行加权融合,生成最终的活动表示。4) 分类:使用分类器(如Softmax)预测活动类别。5) 联邦学习与差分隐私:在联邦学习框架下,客户端本地训练模型,并将模型参数上传到服务器进行聚合。在参数聚合过程中,应用差分隐私机制,防止隐私泄露。
关键创新:主要创新点在于:1) 基于图的多模态表示:将传感器数据建模为图结构,能够更好地捕捉数据间的关系。2) 残差GCN:使用残差GCN提取特征,提高模型的表达能力。3) 注意力机制融合:使用注意力机制进行模态融合,能够自适应地学习不同模态的重要性。4) 差分隐私下的鲁棒性:证明了GCN在差分隐私保护下比传统FFN更具鲁棒性。
关键设计:1) 图构建:具体如何定义节点和边,例如,可以使用滑动窗口将时间序列数据分割成节点,并根据时间邻近性或传感器物理位置定义边。2) 残差GCN:GCN的层数、每层的节点特征维度、残差连接的具体方式等。3) 注意力机制:注意力权重的计算方式,例如,可以使用自注意力机制。4) 差分隐私:差分隐私的参数(如ε和δ)的选择,以及噪声添加的具体方式(如高斯噪声)。损失函数通常是交叉熵损失,用于分类任务。
🖼️ 关键图片
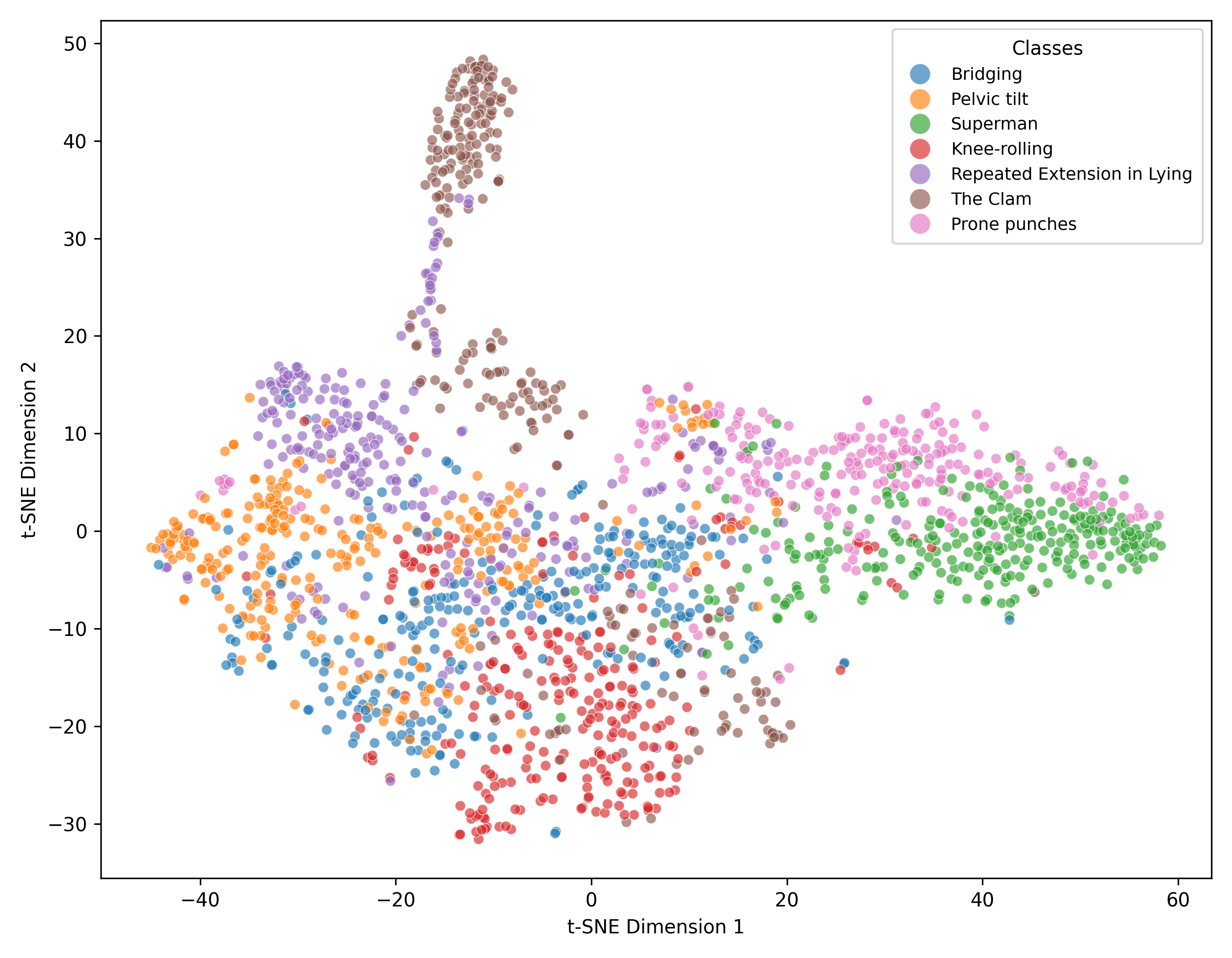
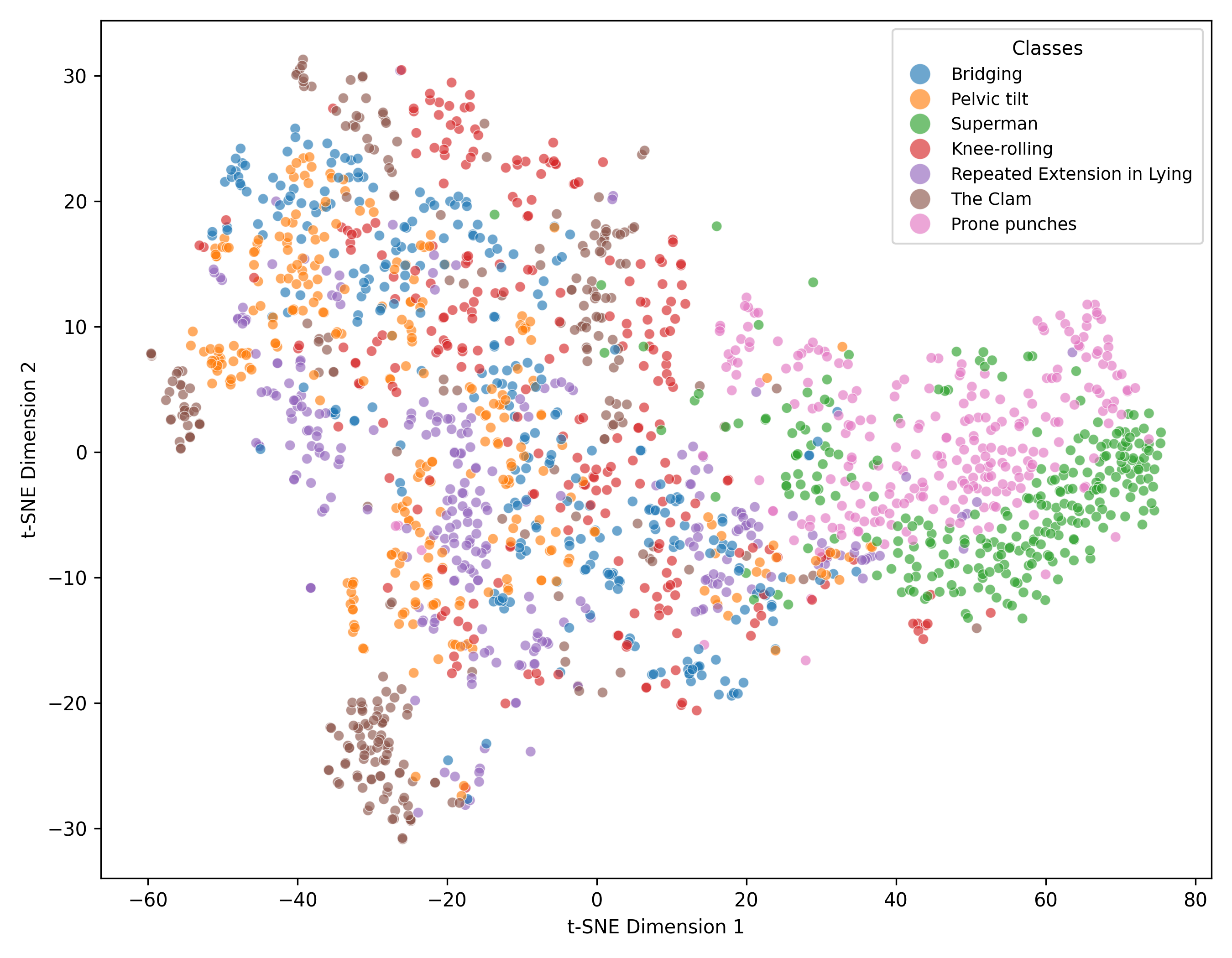
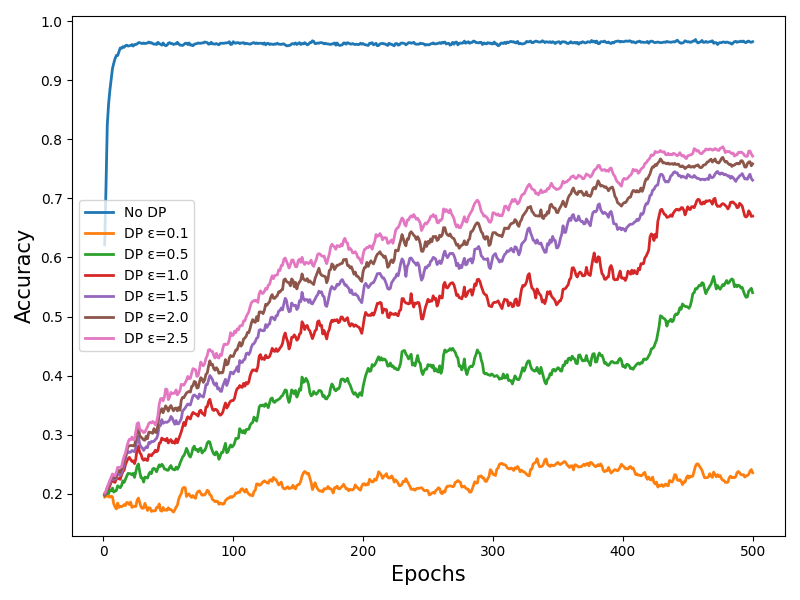
📊 实验亮点
实验结果表明,在非差分隐私设置下,MultiModalGCN模型相比MultiModalFFN基线模型,在集中式和联邦学习场景中准确率提升了2%。更重要的是,在差分隐私约束下,MultiModalGCN的性能优势更加明显,相比MultiModalFFN,性能提升幅度达到7%到13%,验证了图神经网络在差分隐私保护下的鲁棒性。
🎯 应用场景
该研究成果可应用于智能家居、医疗健康、养老监护等领域,通过分析人体活动数据,实现跌倒检测、行为异常预警、康复训练监测等功能。在保护用户隐私的前提下,提升了活动识别的准确性和可靠性,具有重要的社会价值和应用前景。
📄 摘要(原文)
Human Activity Recognition (HAR) using multimodal sensor data remains challenging due to noisy or incomplete measurements, scarcity of labeled examples, and privacy concerns. Traditional centralized deep learning approaches are often constrained by infrastructure availability, network latency, and data sharing restrictions. While federated learning (FL) addresses privacy by training models locally and sharing only model parameters, it still has to tackle issues arising from the use of heterogeneous multimodal data and differential privacy requirements. In this article, a Graph-based Multimodal Federated Learning framework, GraMFedDHAR, is proposed for HAR tasks. Diverse sensor streams such as a pressure mat, depth camera, and multiple accelerometers are modeled as modality-specific graphs, processed through residual Graph Convolutional Neural Networks (GCNs), and fused via attention-based weighting rather than simple concatenation. The fused embeddings enable robust activity classification, while differential privacy safeguards data during federated aggregation. Experimental results show that the proposed MultiModalGCN model outperforms the baseline MultiModalFFN, with up to 2 percent higher accuracy in non-DP settings in both centralized and federated paradigms. More importantly, significant improvements are observed under differential privacy constraints: MultiModalGCN consistently surpasses MultiModalFFN, with performance gaps ranging from 7 to 13 percent depending on the privacy budget and setting. These results highlight the robustness of graph-based modeling in multimodal learning, where GNNs prove more resilient to the performance degradation introduced by DP noise.