Causal Debiasing Medical Multimodal Representation Learning with Missing Modalities
作者: Xiaoguang Zhu, Lianlong Sun, Yang Liu, Pengyi Jiang, Uma Srivatsa, Nipavan Chiamvimonvat, Vladimir Filkov
分类: cs.LG, cs.AI
发布日期: 2025-09-06
备注: Submitted to IEEE TKDE
💡 一句话要点
提出因果去偏的多模态表示学习框架,解决医学数据缺失模态下的偏差问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态表示学习 缺失模态 因果推断 偏差消除 医学数据挖掘
📋 核心要点
- 医学多模态数据常因各种原因缺失,导致模型学习到的表征存在偏差,影响泛化能力。
- 论文提出一种因果去偏框架,通过干预缺失模式和解耦因果特征来减轻偏差。
- 在真实数据集上的实验表明,该方法能够有效提升模型性能,并提供因果关系上的洞察。
📝 摘要(中文)
医学多模态表示学习旨在将异构临床数据整合为统一的患者表征,以支持预测建模,这是医学数据挖掘领域一项重要但具有挑战性的任务。然而,现实世界的医学数据集常常由于成本、协议或患者特定约束而存在模态缺失。现有方法主要通过从原始数据空间或特征空间中的可用观察中学习来解决此问题,但通常忽略了数据采集过程本身引入的潜在偏差。本文识别了两种阻碍模型泛化的偏差:由模态可用性的非随机模式导致的缺失偏差,以及由影响观察到的特征和结果的潜在混淆因素引起的分布偏差。为了应对这些挑战,我们对数据生成过程进行了结构因果分析,并提出了一个与现有基于直接预测的多模态学习方法兼容的统一框架。我们的方法包括两个关键组件:(1)一个基于后门调整来近似因果干预的缺失去混淆模块,以及(2)一个显式地将因果特征与虚假相关性解耦的双分支神经网络。我们在真实世界的公共和院内数据集上评估了我们的方法,证明了其有效性和因果洞察力。
🔬 方法详解
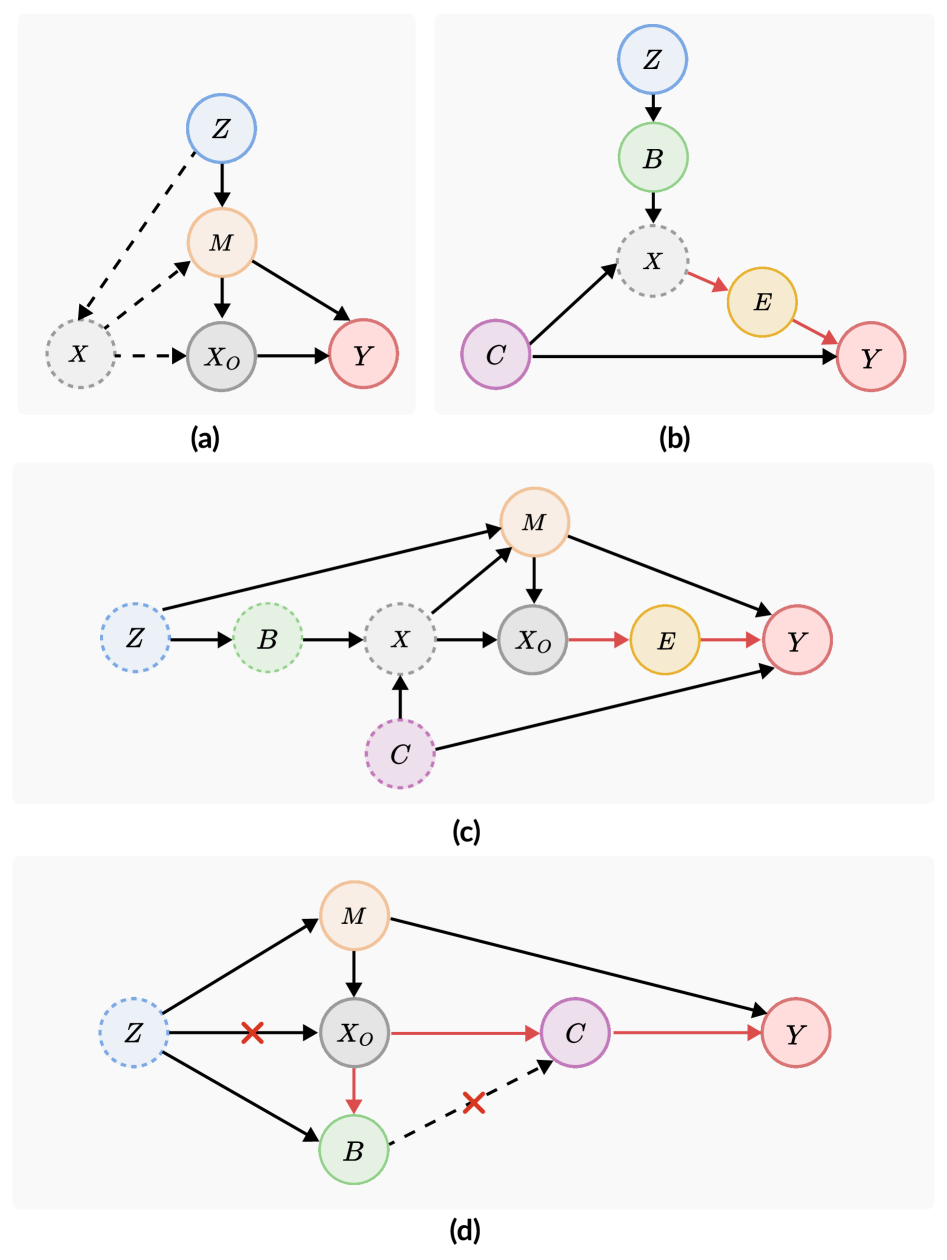
问题定义:医学多模态表示学习旨在整合不同类型的临床数据,但实际应用中,由于成本、协议等原因,数据经常存在缺失模态。现有方法主要关注利用现有数据进行学习,忽略了数据缺失过程引入的偏差,例如缺失模式的非随机性以及潜在混淆因素的影响。这些偏差会导致模型泛化能力下降。
核心思路:论文的核心思路是利用因果推断来解决缺失模态带来的偏差问题。通过对数据生成过程进行结构因果分析,识别出缺失偏差和分布偏差,并设计相应的去偏模块。核心在于将观察到的数据视为受到因果机制影响的结果,并通过干预和解耦的方式来消除偏差的影响。
技术框架:该方法包含两个主要模块:缺失去混淆模块和双分支神经网络。缺失去混淆模块通过后门调整来近似因果干预,从而消除缺失模式带来的偏差。双分支神经网络则将特征分为因果特征和非因果特征,通过解耦的方式来减少虚假相关性的影响。整体流程是先通过缺失去混淆模块处理数据,然后将处理后的数据输入到双分支神经网络进行特征学习和预测。
关键创新:该方法最重要的创新点在于将因果推断引入到医学多模态表示学习中,并针对缺失模态问题设计了专门的去偏模块。与现有方法相比,该方法能够显式地建模和消除数据缺失过程带来的偏差,从而提高模型的泛化能力。
关键设计:缺失去混淆模块使用后门调整来估计因果干预的效果,具体实现方式未知(论文中未详细说明)。双分支神经网络的设计目标是解耦因果特征和非因果特征,具体网络结构未知(论文中未详细说明)。损失函数的设计需要考虑如何促进因果特征的学习和抑制非因果特征的影响,具体形式未知(论文中未详细说明)。
🖼️ 关键图片

📊 实验亮点
该方法在真实世界的公共和院内数据集上进行了评估,实验结果表明,该方法能够有效提高模型的性能,并提供因果关系上的洞察。具体的性能数据和提升幅度未知(论文中未详细说明)。与现有方法相比,该方法在处理缺失模态问题时具有更强的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于多种医学预测任务,例如疾病诊断、预后预测和治疗方案推荐。通过消除数据缺失带来的偏差,可以提高模型的准确性和可靠性,从而辅助医生进行更精准的临床决策。未来,该方法可以推广到其他领域的多模态数据分析中,例如金融风控和智能交通。
📄 摘要(原文)
Medical multimodal representation learning aims to integrate heterogeneous clinical data into unified patient representations to support predictive modeling, which remains an essential yet challenging task in the medical data mining community. However, real-world medical datasets often suffer from missing modalities due to cost, protocol, or patient-specific constraints. Existing methods primarily address this issue by learning from the available observations in either the raw data space or feature space, but typically neglect the underlying bias introduced by the data acquisition process itself. In this work, we identify two types of biases that hinder model generalization: missingness bias, which results from non-random patterns in modality availability, and distribution bias, which arises from latent confounders that influence both observed features and outcomes. To address these challenges, we perform a structural causal analysis of the data-generating process and propose a unified framework that is compatible with existing direct prediction-based multimodal learning methods. Our method consists of two key components: (1) a missingness deconfounding module that approximates causal intervention based on backdoor adjustment and (2) a dual-branch neural network that explicitly disentangles causal features from spurious correlations. We evaluated our method in real-world public and in-hospital datasets, demonstrating its effectiveness and causal insights.