ProfilingAgent: Profiling-Guided Agentic Reasoning for Adaptive Model Optimization
作者: Sadegh Jafari, Aishwarya Sarkar, Mohiuddin Bilwal, Ali Jannesari
分类: cs.LG, cs.CV, cs.PF
发布日期: 2025-09-06
备注: 13 pages, 3 figures, 5 tables, 1 algorithm
💡 一句话要点
ProfilingAgent:提出Profiling引导的Agentic推理,自适应优化模型压缩。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型压缩 大型语言模型 Agentic推理 Profiling引导 自适应优化 剪枝 量化
📋 核心要点
- 现有模型压缩方法依赖于统一启发式策略,忽略了架构和运行时异构性,导致优化效果受限。
- ProfilingAgent利用大型语言模型作为Agent,通过分析静态和动态指标,自适应地设计模型压缩策略。
- 实验表明,ProfilingAgent在剪枝和量化方面均取得了显著效果,在精度和效率上均优于传统方法。
📝 摘要(中文)
基础模型面临日益增长的计算和内存瓶颈,阻碍了其在资源受限平台上的部署。虽然剪枝和量化等压缩技术被广泛使用,但大多数依赖于忽略架构和运行时异构性的统一启发式方法。Profiling工具可以暴露每层的延迟、内存和计算成本,但很少被集成到自动化流程中。我们提出了ProfilingAgent,一种Profiling引导的、基于Agent的方案,它使用大型语言模型(LLM)通过结构化剪枝和训练后动态量化来自动化压缩。我们的模块化多Agent系统对静态指标(MACs、参数计数)和动态信号(延迟、内存)进行推理,以设计特定于架构的策略。与启发式基线不同,ProfilingAgent根据瓶颈定制分层决策。在ImageNet-1K、CIFAR-10和CIFAR-100上,使用ResNet-101、ViT-B/16、Swin-B和DeiT-B/16进行的实验表明,剪枝保持了有竞争力的或改进的准确性(ImageNet-1K上约1%的下降,ViT-B/16在较小数据集上+2%的增益),而量化实现了高达74%的内存节省,且精度损失小于0.5%。我们的量化还实现了高达1.74倍的一致推理加速。与GPT-4o和GPT-4-Turbo的对比研究突出了LLM推理质量对于迭代剪枝的重要性。这些结果确立了Agent系统作为Profiling引导模型优化的可扩展解决方案。
🔬 方法详解
问题定义:现有模型压缩方法,如剪枝和量化,通常采用统一的启发式策略,无法充分利用不同架构和运行时环境的异构性。这导致压缩后的模型在精度和效率上难以达到最优平衡。Profiling工具虽然可以提供细粒度的性能指标,但缺乏自动化集成到压缩流程中。
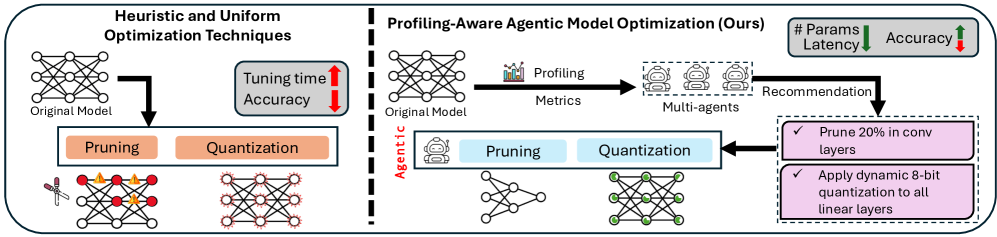
核心思路:ProfilingAgent的核心思路是利用大型语言模型(LLM)的推理能力,构建一个智能Agent系统,该系统能够根据Profiling工具提供的静态(如MACs、参数量)和动态(如延迟、内存)指标,自适应地设计和执行模型压缩策略。通过迭代地分析和优化,ProfilingAgent能够针对特定架构和部署环境,找到最佳的压缩方案。
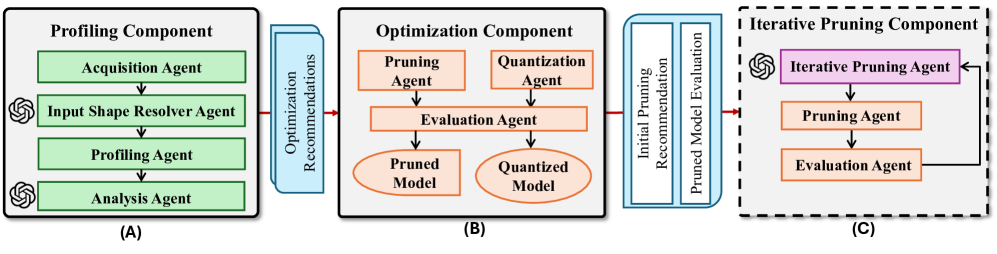
技术框架:ProfilingAgent采用模块化的多Agent系统架构。主要包含以下几个模块:1) Profiling模块:负责收集模型的静态和动态性能指标。2) Reasoning模块:利用LLM对Profiling数据进行推理,识别性能瓶颈,并生成压缩策略。3) Execution模块:根据Reasoning模块生成的策略,执行剪枝和量化操作。4) Evaluation模块:评估压缩后模型的性能,并将结果反馈给Reasoning模块,进行迭代优化。
关键创新:ProfilingAgent的关键创新在于将大型语言模型引入到模型压缩流程中,实现了自动化和自适应的压缩策略设计。与传统的启发式方法相比,ProfilingAgent能够更好地理解模型的内部结构和运行时行为,从而做出更明智的压缩决策。此外,多Agent系统的模块化设计使得ProfilingAgent具有良好的可扩展性和灵活性。
关键设计:ProfilingAgent的关键设计包括:1) 使用LLM作为Reasoning Agent,利用其强大的推理能力。2) 设计合理的Prompt,引导LLM生成有效的压缩策略。3) 定义合适的奖励函数,指导Agent进行迭代优化。4) 采用结构化剪枝和动态量化等压缩技术,保证压缩后模型的性能。
🖼️ 关键图片
📊 实验亮点
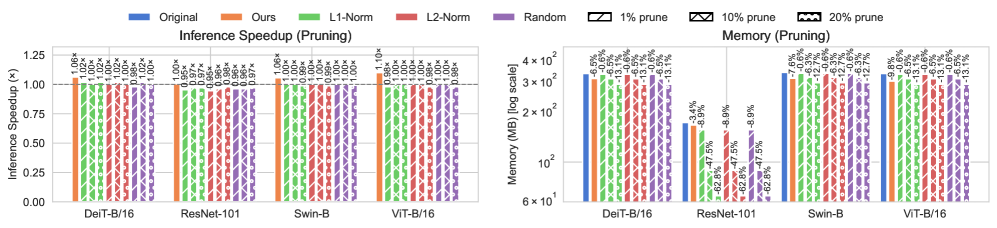
实验结果表明,ProfilingAgent在ImageNet-1K数据集上,使用ResNet-101进行剪枝,精度下降约1%。在较小数据集上,ViT-B/16的精度提升了2%。量化方面,ProfilingAgent实现了高达74%的内存节省,且精度损失小于0.5%。同时,推理速度提升高达1.74倍。与GPT-4o和GPT-4-Turbo的对比研究表明,LLM的推理能力对迭代剪枝至关重要。
🎯 应用场景
ProfilingAgent可应用于各种需要模型压缩的场景,例如移动设备、嵌入式系统和边缘计算。通过自动化模型压缩流程,ProfilingAgent可以降低模型部署的成本和难度,加速人工智能技术在资源受限环境中的应用。此外,该方法还可以用于模型优化和加速,提高推理效率。
📄 摘要(原文)
Foundation models face growing compute and memory bottlenecks, hindering deployment on resource-limited platforms. While compression techniques such as pruning and quantization are widely used, most rely on uniform heuristics that ignore architectural and runtime heterogeneity. Profiling tools expose per-layer latency, memory, and compute cost, yet are rarely integrated into automated pipelines. We propose ProfilingAgent, a profiling-guided, agentic approach that uses large language models (LLMs) to automate compression via structured pruning and post-training dynamic quantization. Our modular multi-agent system reasons over static metrics (MACs, parameter counts) and dynamic signals (latency, memory) to design architecture-specific strategies. Unlike heuristic baselines, ProfilingAgent tailors layer-wise decisions to bottlenecks. Experiments on ImageNet-1K, CIFAR-10, and CIFAR-100 with ResNet-101, ViT-B/16, Swin-B, and DeiT-B/16 show pruning maintains competitive or improved accuracy (about 1% drop on ImageNet-1K, +2% gains for ViT-B/16 on smaller datasets), while quantization achieves up to 74% memory savings with <0.5% accuracy loss. Our quantization also yields consistent inference speedups of up to 1.74 times faster. Comparative studies with GPT-4o and GPT-4-Turbo highlight the importance of LLM reasoning quality for iterative pruning. These results establish agentic systems as scalable solutions for profiling-guided model optimization.